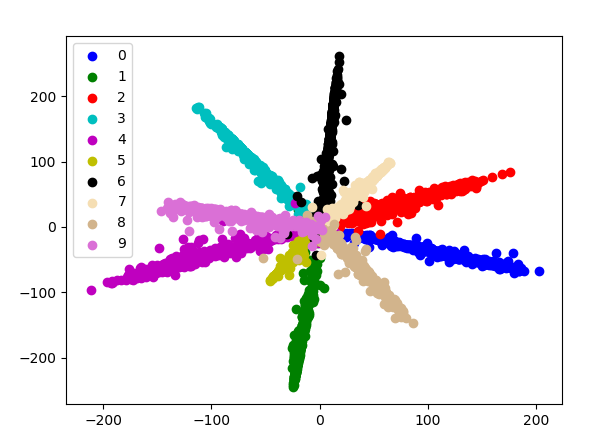
为了直观地验证网络对特征提取的性能,可以使用可视化技术来可视化经过网络之后的特征分布情况。这也是目前softmax-base的人脸识别论文的常见做法。
首先就是训练好一个网络然后进行测试,为了充分利用GPU的性能,测试过程中使用mini-batch的数据进行前向传播,并记录特征。
def vis():
'''
对模型结果进行可视化
'''
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Net().to(device)
#model.load_state_dict(torch.load('mnist_cnn.pt'))
model.eval()
print('加载模型完毕')
test_batch_size=64
kwargs = {'num_workers': 0, 'pin_memory': True} if torch.cuda.is_available() else {}
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=test_batch_size, shuffle=True, **kwargs)
data_iter=iter(test_loader)
cnt=0
fn='./res_random.csv'
with torch.no_grad():
while cnt<100:
cnt+=1
data, target = data_iter.__next__()
data, target = data.to(device), target.to(device)
output, features = model(data)
pred = output.argmax(dim=1, keepdim=True)
if test_batch_size==1:
target= target.cpu().numpy()[0]
features=features.cpu().numpy()[0]
else:
target= target.cpu().numpy()
features=features.cpu().numpy()
print(features.shape,',',target.shape)
#转换为1维的向量,方便后面解码
features=np.reshape(features,-1)
target=np.reshape(target,-1)
#features=np.array2string(features)
#target=np.array2string(target)
#features=features.tostring()
#target=target.tostring()
#后面就是存储到文件中
在获取到特征数据后,将特征可视化部分,之前有使用过pandas,发现挺好用的,为了不重复造轮子,直接在pandas的基础上操作数据。
fn='./res_random.csv'
df=pd.read_csv(fn,sep=' ',names=['feat','id'])
dic=df.set_index('feat')['id'].to_dict()
keys=list(dic.keys())
k=keys[0]
k=k.strip('][')
karr=np.fromstring(k,float,sep=' ')
karr=np.reshape(karr,(64,2)).tolist()
label=list(dic.values())
l=label[0]
l=l.strip('][')
larr=np.fromstring(l,int,sep=' ').tolist()
x, y=zip(*karr)
x=np.array(x)
y=np.array(y)
group=np.array(larr)
cdict={0:'b',1:'g',2:'r',3:'c',4:'m',5:'y',6:'k',7:'wheat',8:'tan',9:'orchid'}
fig, ax= plt.subplots()
total_x=[]
total_y=[]
total_l=[]
for k,l in zip(keys,label):
k=k.strip('][')
karr=np.fromstring(k,float,sep=' ')
karr=np.reshape(karr,(64,2)).tolist()
l=l.strip('][')
larr=np.fromstring(l,int,sep=' ').tolist()
x, y=zip(*karr)
x=list(x)
y=list(y)
total_x=total_x+x
total_y=total_y+y
total_l=total_l+larr
group=np.array(total_l)
x=np.array(total_x)
y=np.array(total_y)
for g in np.unique(group):
ix= np.where(group==g)
ax.scatter(x[ix],y[ix],c=cdict[g],label=int(g))
ax.legend()
plt.show()
这样就能得到
参考网站
不同标签绘制不同颜色
将列表形式的xy坐标分离
matplotlib颜色表
有空补一补注释