一、原理概述
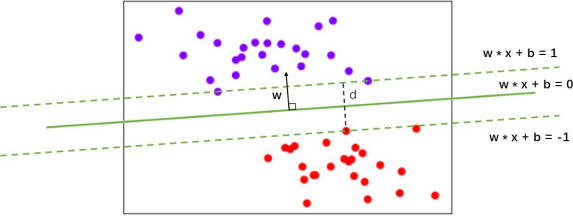
支持向量机分类器,是在数据空间中找出一个超平面作为决策边界,利用这个决策边界来对数据进行分类,并使分类误差尽量小的模型。决策边界是比所在数据空间小一维的空间,在三维数据空间中就是一个平面,在二维数据空间中就是一条直线。以二维数据为例,图中的数据集有两个特征,标签有两类,一类为紫色,一类为红色。对于这组数据,我们找出的决策边界被表达为w·x + b = 0,决策边界把平面分成了上下两部分,决策边界以上的样本 都分为一类,决策边界以下的样本被分为另一类。以我们的图像为例,绿色实线上部分为一类(全部都是紫色点),下部分为另一类(全都是红色点)。
平行于决策边界的两条虚线是距离决策边界相对距离为1的超平面,他们分别压过两类样本中距离决策边界最近的样本点,这些样本点就被成为支持向量。两条虚线超平面之间的距离叫做边际,简写为d。支持向量机分类器,就是以找出最大化的边际d为目标来求解损失函数,以求解出参数w和b ,以构建决策边界,然后用决策边界来分类的分类器。在这种最简单的情况下,我们的决策函数为:
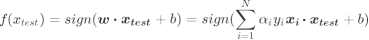
其中sign(h)是h > 0 时返回正1,h < 0时返回-1的符号函数,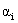 是拉格朗日乘数,
是拉格朗日乘数,![]()
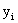 是样本i的真实标签,
是样本i的真实标签, 是测试训练,
是测试训练, 是测试样本,
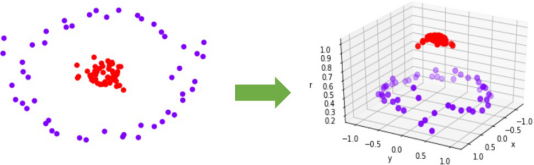
是测试样本,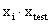 是原特征向量与测试特征向量的点积。当函数返回1,则样本i被分为正类。当函数返回-1,则样本被分为负类。
是原特征向量与测试特征向量的点积。当函数返回1,则样本i被分为正类。当函数返回-1,则样本被分为负类。
当然,不是所有数据都是线性可分的,不是所有数据我们都能够一眼看出,有一条直线,或一个平面,甚至一个超平面可以将数据完全分开。比如下面的环形数据。对于这样的数据,我们需要对它进行一个升维变化,来数据从原始的空间x投射到新空间Φ(x)中。升维之后,我们明显可以找出一个平面,能够将数据切分开来。Φ是一个映射函数,它代表了某种能够将数据升维的非线性的变换,我们对数据进行这样的变换,确保数据在自己的空间中一定能够线性可分。
能够处理非线性问题的SVM的决策函数如下:
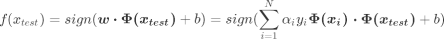
可见,除了我们对原始数据进行了升维处理之外,其他表达都和普通的线性SVM一模一样。
这种变换非常巧妙,但也带有一些实现问题。首先,我们可能不清楚应该什么样的数据应该使用什么类型的映射函数来确保可以在变换空间中找出线性决策边界。极端情况下,数据可能会被映射到无限维度的空间中,这种高维空间可能不是那么友好,维度越多,推导和计算的难度都会随之暴增。其次,即使已知适当的映射函数,我们想要计算类似于Φ( )·Φ(
)·Φ(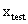 )这样的点积,计算量可能会无比巨大,要找出超平面所付出的代价是非常昂贵的。
)这样的点积,计算量可能会无比巨大,要找出超平面所付出的代价是非常昂贵的。
关键概念:核函数
而解决这些问题的数学方式,叫做“核技巧”(Kernel Trick),是一种能够使用数据原始空间中的向量计算来表示升维后的空间中的点积结果的数学方式。具体表现为,
K(u,v) = Φ(u)·Φ(v)。而这个原始空间中的点积函数K(u,v),就被叫做“核函数”(Kernel Function)。
有了核函数,我们可以将决策函数表示为:
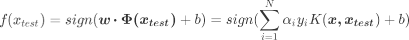
核函数能够帮助我们解决三个问题:
第一,有了核函数之后,我们无需去担心Φ究竟应该是什么样,因为非线性SVM中的核函数都是正定核函数(positive definite kernel functions),他们都满足美世定律(Mercer's theorem),确保了高维空间中任意两个向量的点积一定可以被低维空间中的这两个向量的某种计算来表示(多数时候是点积的某种变换)。
第二,使用核函数计算低维度中的向量关系比计算原本的Φ()·Φ()要简单太多了。
第三,因为计算是在原始空间中进行,所以避免了维度诅咒的问题。
选用不同的核函数,就可以解决不同数据分布下的寻找超平面问题。在sklearn的SVC中,这个功能由参数“kernel”和一系列与核函数相关的参数来进行控制。现在,我们在乳腺癌数据集上,来探索一下各种核函数的功能和选择。
二、SVC的重要参数kernel
在sklearn中实现SVC的基本流程:

作为SVC类最重要的参数之一,“kernel"在sklearn中可选以下几种选项:

可以看出,除了选项"linear"之外,其他核函数都可以处理非线性问题。多项式核函数有次数d,当d为1的时候它就是再处理线性问题,当d为更高次项的时候它就是在处理非线性问题。那究竟什么时候选择哪一个核函数呢?遗憾的是,关于核函数在不同数据集上的研究甚少,谷歌学术上的论文中也没有几篇是研究核函数在SVM中的运用的,更多的是关于核函数在深度学习,神经网络中如何使用。在sklearn中,也没有提供任何关于如何选取核函数的信息。
但无论如何,我们还是可以通过在不同的核函数中循环去找寻最佳的核函数来对核函数进行一个选取。我创造了一系列线性或非线性可分的数据,绘制出每个数据集上SVC在不同核函数下的决策边界,并计算SVC在不同核函数下分类准确率来观察核函数的效用。

可以观察到,线性核函数和多项式核函数在非线性数据上表现会浮动,如果数据相对线性可分,则表现不错,如果是像环形数据那样彻底不可分的,则表现糟糕。在线性数据集上,线性核函数和多项式核函数即便有扰动项也可以表现不错,可见多项式核函数是虽然也可以处理非线性情况,但更偏向于线性的功能。
Sigmoid核函数就比较尴尬了,它在非线性数据上强于两个线性核函数,但效果明显不如rbf,它在线性数据上完全比不上线性的核函数们,对扰动项的抵抗也比较弱,所以它功能比较弱小,很少被用到。
rbf,高斯径向基核函数基本在任何数据集上都表现不错,属于比较万能的核函数。我个人的经验是,无论如何先试试看高斯径向基核函数,它适用于核转换到很高的空间的情况,在各种情况下往往效果都很不错,如果rbf效果不好,那我们再试试看其他的核函数。另外,多项式核函数多被用于图像处理之中。
三、乳腺癌数据集下探索核函数的性质
1、探索kernel该如何选取
看起来,除了Sigmoid核函数,其他核函数效果都还不错。但其实各个核函数都有自己的问题。接下来,我们就使用乳腺癌数据集作为例子来展示一下:
1 Kernel = ["linear","poly","rbf","sigmoid"] 2 3 for kernel in Kernel: 4 clf= SVC(kernel = kernel 5 , gamma="auto" 6 # , degree = 1 7 , cache_size=5000 8 ).fit(Xtrain,Ytrain) 9 print("The accuracy under kernel %s is %f" % (kernel,clf.score(Xtest,Ytest)))
运行结果:
The accuracy under kernel linear is 0.929825
然后我们发现,怎么跑都跑不出来。模型一直停留在线性核函数之后,就没有再打印结果了。这证明,多项式核函 数此时此刻要消耗大量的时间,运算非常的缓慢。让我们在循环中去掉多项式核函数,再试试看能否跑出结果:
1 Kernel = ["linear","rbf","sigmoid"] 2 3 for kernel in Kernel: 4 clf= SVC(kernel = kernel 5 , gamma="auto" 6 # , degree = 1 7 , cache_size=5000 8 ).fit(Xtrain,Ytrain) 9 print("The accuracy under kernel %s is %f" % (kernel,clf.score(Xtest,Ytest)))
运行结果:
The accuracy under kernel linear is 0.929825
The accuracy under kernel rbf is 0.596491
The accuracy under kernel sigmoid is 0.596491
我们可以有两个发现。首先,乳腺癌数据集是一个线性数据集,线性核函数跑出来的效果很好。rbf和sigmoid两个擅长非线性的数据从效果上来看完全不可用。其次,线性核函数的运行速度远远不如非线性的两个核函数。
如果数据是线性的,那如果我们把degree参数调整为1,多项式核函数应该也可以得到不错的结果:
1 Kernel = ["linear","poly","rbf","sigmoid"] 2 3 for kernel in Kernel: 4 clf= SVC(kernel = kernel 5 , gamma="auto" 6 , degree = 1 7 , cache_size=5000 8 ).fit(Xtrain,Ytrain) 9 print("The accuracy under kernel %s is %f" % (kernel,clf.score(Xtest,Ytest)))
运行结果:
The accuracy under kernel linear is 0.929825
The accuracy under kernel poly is 0.923977
The accuracy under kernel rbf is 0.596491
The accuracy under kernel sigmoid is 0.596491
多项式核函数的运行速度立刻加快了,并且精度也提升到了接近线性核函数的水平。但是,我们之前的实验中,rbf在线性数据上也可以表现得非常好,那在这里,为什么跑出来的结果如此糟糕呢?
其实,这里真正的问题是数据的量纲问题。回忆一下我们如何求解决策边界,如何判断点是否在决策边界的一边? 是靠计算“距离”,虽然我们不能说SVM是完全的距离类模型,但是它严重受到数据量纲的影响。让我们来探索一下乳腺癌数据集的量纲:
1 import pandas as pd 2 data = pd.DataFrame(X) 3 data.describe([0.01,0.05,0.1,0.25,0.5,0.75,0.9,0.99]).T
| count | mean | std | min | 1% | 5% | 10% | 25% | 50% | 75% | 90% | 99% | max | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 569.0 | 14.127292 | 3.524049 | 6.981000 | 8.458360 | 9.529200 | 10.260000 | 11.700000 | 13.370000 | 15.780000 | 19.530000 | 24.371600 | 28.11000 |
| 1 | 569.0 | 19.289649 | 4.301036 | 9.710000 | 10.930400 | 13.088000 | 14.078000 | 16.170000 | 18.840000 | 21.800000 | 24.992000 | 30.652000 | 39.28000 |
| 2 | 569.0 | 91.969033 | 24.298981 | 43.790000 | 53.827600 | 60.496000 | 65.830000 | 75.170000 | 86.240000 | 104.100000 | 129.100000 | 165.724000 | 188.50000 |
| 3 | 569.0 | 654.889104 | 351.914129 | 143.500000 | 215.664000 | 275.780000 | 321.600000 | 420.300000 | 551.100000 | 782.700000 | 1177.400000 | 1786.600000 | 2501.00000 |
| 4 | 569.0 | 0.096360 | 0.014064 | 0.052630 | 0.068654 | 0.075042 | 0.079654 | 0.086370 | 0.095870 | 0.105300 | 0.114820 | 0.132888 | 0.16340 |
| 5 | 569.0 | 0.104341 | 0.052813 | 0.019380 | 0.033351 | 0.040660 | 0.049700 | 0.064920 | 0.092630 | 0.130400 | 0.175460 | 0.277192 | 0.34540 |
| 6 | 569.0 | 0.088799 | 0.079720 | 0.000000 | 0.000000 | 0.004983 | 0.013686 | 0.029560 | 0.061540 | 0.130700 | 0.203040 | 0.351688 | 0.42680 |
| 7 | 569.0 | 0.048919 | 0.038803 | 0.000000 | 0.000000 | 0.005621 | 0.011158 | 0.020310 | 0.033500 | 0.074000 | 0.100420 | 0.164208 | 0.20120 |
| 8 | 569.0 | 0.181162 | 0.027414 | 0.106000 | 0.129508 | 0.141500 | 0.149580 | 0.161900 | 0.179200 | 0.195700 | 0.214940 | 0.259564 | 0.30400 |
| 9 | 569.0 | 0.062798 | 0.007060 | 0.049960 | 0.051504 | 0.053926 | 0.055338 | 0.057700 | 0.061540 | 0.066120 | 0.072266 | 0.085438 | 0.09744 |
| 10 | 569.0 | 0.405172 | 0.277313 | 0.111500 | 0.119740 | 0.160100 | 0.183080 | 0.232400 | 0.324200 | 0.478900 | 0.748880 | 1.291320 | 2.87300 |
| 11 | 569.0 | 1.216853 | 0.551648 | 0.360200 | 0.410548 | 0.540140 | 0.640400 | 0.833900 | 1.108000 | 1.474000 | 1.909400 | 2.915440 | 4.88500 |
| 12 | 569.0 | 2.866059 | 2.021855 | 0.757000 | 0.953248 | 1.132800 | 1.280200 | 1.606000 | 2.287000 | 3.357000 | 5.123200 | 9.690040 | 21.98000 |
| 13 | 569.0 | 40.337079 | 45.491006 | 6.802000 | 8.514440 | 11.360000 | 13.160000 | 17.850000 | 24.530000 | 45.190000 | 91.314000 | 177.684000 | 542.20000 |
| 14 | 569.0 | 0.007041 | 0.003003 | 0.001713 | 0.003058 | 0.003690 | 0.004224 | 0.005169 | 0.006380 | 0.008146 | 0.010410 | 0.017258 | 0.03113 |
| 15 | 569.0 | 0.025478 | 0.017908 | 0.002252 | 0.004705 | 0.007892 | 0.009169 | 0.013080 | 0.020450 | 0.032450 | 0.047602 | 0.089872 | 0.13540 |
| 16 | 569.0 | 0.031894 | 0.030186 | 0.000000 | 0.000000 | 0.003253 | 0.007726 | 0.015090 | 0.025890 | 0.042050 | 0.058520 | 0.122292 | 0.39600 |
| 17 | 569.0 | 0.011796 | 0.006170 | 0.000000 | 0.000000 | 0.003831 | 0.005493 | 0.007638 | 0.010930 | 0.014710 | 0.018688 | 0.031194 | 0.05279 |
| 18 | 569.0 | 0.020542 | 0.008266 | 0.007882 | 0.010547 | 0.011758 | 0.013012 | 0.015160 | 0.018730 | 0.023480 | 0.030120 | 0.052208 | 0.07895 |
| 19 | 569.0 | 0.003795 | 0.002646 | 0.000895 | 0.001114 | 0.001522 | 0.001710 | 0.002248 | 0.003187 | 0.004558 | 0.006185 | 0.012650 | 0.02984 |
| 20 | 569.0 | 16.269190 | 4.833242 | 7.930000 | 9.207600 | 10.534000 | 11.234000 | 13.010000 | 14.970000 | 18.790000 | 23.682000 | 30.762800 | 36.04000 |
| 21 | 569.0 | 25.677223 | 6.146258 | 12.020000 | 15.200800 | 16.574000 | 17.800000 | 21.080000 | 25.410000 | 29.720000 | 33.646000 | 41.802400 | 49.54000 |
| 22 | 569.0 | 107.261213 | 33.602542 | 50.410000 | 58.270400 | 67.856000 | 72.178000 | 84.110000 | 97.660000 | 125.400000 | 157.740000 | 208.304000 | 251.20000 |
| 23 | 569.0 | 880.583128 | 569.356993 | 185.200000 | 256.192000 | 331.060000 | 384.720000 | 515.300000 | 686.500000 | 1084.000000 | 1673.000000 | 2918.160000 | 4254.00000 |
| 24 | 569.0 | 0.132369 | 0.022832 | 0.071170 | 0.087910 | 0.095734 | 0.102960 | 0.116600 | 0.131300 | 0.146000 | 0.161480 | 0.188908 | 0.22260 |
| 25 | 569.0 | 0.254265 | 0.157336 | 0.027290 | 0.050094 | 0.071196 | 0.093676 | 0.147200 | 0.211900 | 0.339100 | 0.447840 | 0.778644 | 1.05800 |
| 26 | 569.0 | 0.272188 | 0.208624 | 0.000000 | 0.000000 | 0.018360 | 0.045652 | 0.114500 | 0.226700 | 0.382900 | 0.571320 | 0.902380 | 1.25200 |
| 27 | 569.0 | 0.114606 | 0.065732 | 0.000000 | 0.000000 | 0.024286 | 0.038460 | 0.064930 | 0.099930 | 0.161400 | 0.208940 | 0.269216 | 0.29100 |
| 28 | 569.0 | 0.290076 | 0.061867 | 0.156500 | 0.176028 | 0.212700 | 0.226120 | 0.250400 | 0.282200 | 0.317900 | 0.360080 | 0.486908 | 0.66380 |
| 29 | 569.0 | 0.083946 | 0.018061 | 0.055040 | 0.058580 | 0.062558 | 0.065792 | 0.071460 | 0.080040 | 0.092080 | 0.106320 | 0.140628 | 0.20750 |
一眼望去,果然数据存在严重的量纲不一的问题。我们来使用数据预处理中的标准化的类,对数据进行标准化:
1 from sklearn.preprocessing import StandardScaler 2 X = StandardScaler().fit_transform(X) 3 data = pd.DataFrame(X) 4 data.describe([0.01,0.05,0.1,0.25,0.5,0.75,0.9,0.99]).T
| count | mean | std | min | 1% | 5% | 10% | 25% | 50% | 75% | 90% | 99% | max | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 569.0 | -3.162867e-15 | 1.00088 | -2.029648 | -1.610057 | -1.305923 | -1.098366 | -0.689385 | -0.215082 | 0.469393 | 1.534446 | 2.909529 | 3.971288 |
| 1 | 569.0 | -6.530609e-15 | 1.00088 | -2.229249 | -1.945253 | -1.443165 | -1.212786 | -0.725963 | -0.104636 | 0.584176 | 1.326975 | 2.644095 | 4.651889 |
| 2 | 569.0 | -7.078891e-16 | 1.00088 | -1.984504 | -1.571053 | -1.296381 | -1.076672 | -0.691956 | -0.235980 | 0.499677 | 1.529432 | 3.037982 | 3.976130 |
| 3 | 569.0 | -8.799835e-16 | 1.00088 | -1.454443 | -1.249201 | -1.078225 | -0.947908 | -0.667195 | -0.295187 | 0.363507 | 1.486075 | 3.218702 | 5.250529 |
| 4 | 569.0 | 6.132177e-15 | 1.00088 | -3.112085 | -1.971730 | -1.517125 | -1.188910 | -0.710963 | -0.034891 | 0.636199 | 1.313694 | 2.599511 | 4.770911 |
| 5 | 569.0 | -1.120369e-15 | 1.00088 | -1.610136 | -1.345369 | -1.206849 | -1.035527 | -0.747086 | -0.221940 | 0.493857 | 1.347811 | 3.275782 | 4.568425 |
| 6 | 569.0 | -4.421380e-16 | 1.00088 | -1.114873 | -1.114873 | -1.052316 | -0.943046 | -0.743748 | -0.342240 | 0.526062 | 1.434288 | 3.300560 | 4.243589 |
| 7 | 569.0 | 9.732500e-16 | 1.00088 | -1.261820 | -1.261820 | -1.116837 | -0.974010 | -0.737944 | -0.397721 | 0.646935 | 1.328412 | 2.973759 | 3.927930 |
| 8 | 569.0 | -1.971670e-15 | 1.00088 | -2.744117 | -1.885853 | -1.448032 | -1.153036 | -0.703240 | -0.071627 | 0.530779 | 1.233221 | 2.862418 | 4.484751 |
| 9 | 569.0 | -1.453631e-15 | 1.00088 | -1.819865 | -1.600987 | -1.257643 | -1.057477 | -0.722639 | -0.178279 | 0.470983 | 1.342243 | 3.209454 | 4.910919 |
| 10 | 569.0 | -9.076415e-16 | 1.00088 | -1.059924 | -1.030184 | -0.884517 | -0.801577 | -0.623571 | -0.292245 | 0.266100 | 1.240514 | 3.198294 | 8.906909 |
| 11 | 569.0 | -8.853492e-16 | 1.00088 | -1.554264 | -1.462915 | -1.227791 | -1.045885 | -0.694809 | -0.197498 | 0.466552 | 1.256518 | 3.081820 | 6.655279 |
| 12 | 569.0 | 1.773674e-15 | 1.00088 | -1.044049 | -0.946900 | -0.858016 | -0.785049 | -0.623768 | -0.286652 | 0.243031 | 1.117354 | 3.378079 | 9.461986 |
| 13 | 569.0 | -8.291551e-16 | 1.00088 | -0.737829 | -0.700152 | -0.637545 | -0.597942 | -0.494754 | -0.347783 | 0.106773 | 1.121579 | 3.021867 | 11.041842 |
| 14 | 569.0 | -7.541809e-16 | 1.00088 | -1.776065 | -1.327593 | -1.116972 | -0.939031 | -0.624018 | -0.220335 | 0.368355 | 1.123053 | 3.405812 | 8.029999 |
| 15 | 569.0 | -3.921877e-16 | 1.00088 | -1.298098 | -1.160988 | -0.982870 | -0.911510 | -0.692926 | -0.281020 | 0.389654 | 1.236492 | 3.598943 | 6.143482 |
| 16 | 569.0 | 7.917900e-16 | 1.00088 | -1.057501 | -1.057501 | -0.949654 | -0.801336 | -0.557161 | -0.199065 | 0.336752 | 0.882848 | 2.997338 | 12.072680 |
| 17 | 569.0 | -2.739461e-16 | 1.00088 | -1.913447 | -1.913447 | -1.292055 | -1.022462 | -0.674490 | -0.140496 | 0.472657 | 1.117927 | 3.146456 | 6.649601 |
| 18 | 569.0 | -3.108234e-16 | 1.00088 | -1.532890 | -1.210240 | -1.063590 | -0.911757 | -0.651681 | -0.219430 | 0.355692 | 1.159654 | 3.834036 | 7.071917 |
| 19 | 569.0 | -3.366766e-16 | 1.00088 | -1.096968 | -1.014237 | -0.859880 | -0.788466 | -0.585118 | -0.229940 | 0.288642 | 0.904208 | 3.349301 | 9.851593 |
| 20 | 569.0 | -2.333224e-15 | 1.00088 | -1.726901 | -1.462332 | -1.187658 | -1.042700 | -0.674921 | -0.269040 | 0.522016 | 1.535063 | 3.001373 | 4.094189 |
| 21 | 569.0 | 1.763674e-15 | 1.00088 | -2.223994 | -1.706020 | -1.482403 | -1.282757 | -0.748629 | -0.043516 | 0.658341 | 1.297666 | 2.625885 | 3.885905 |
| 22 | 569.0 | -1.198026e-15 | 1.00088 | -1.693361 | -1.459232 | -1.173717 | -1.044983 | -0.689578 | -0.285980 | 0.540279 | 1.503553 | 3.009644 | 4.287337 |
| 23 | 569.0 | 5.049661e-16 | 1.00088 | -1.222423 | -1.097625 | -0.966014 | -0.871684 | -0.642136 | -0.341181 | 0.357589 | 1.393000 | 3.581882 | 5.930172 |
| 24 | 569.0 | -5.213170e-15 | 1.00088 | -2.682695 | -1.948882 | -1.605910 | -1.289152 | -0.691230 | -0.046843 | 0.597545 | 1.276124 | 2.478455 | 3.955374 |
| 25 | 569.0 | -2.174788e-15 | 1.00088 | -1.443878 | -1.298811 | -1.164575 | -1.021571 | -0.681083 | -0.269501 | 0.539669 | 1.231407 | 3.335783 | 5.112877 |
| 26 | 569.0 | 6.856456e-16 | 1.00088 | -1.305831 | -1.305831 | -1.217748 | -1.086814 | -0.756514 | -0.218232 | 0.531141 | 1.435090 | 3.023359 | 4.700669 |
| 27 | 569.0 | -1.412656e-16 | 1.00088 | -1.745063 | -1.745063 | -1.375270 | -1.159448 | -0.756400 | -0.223469 | 0.712510 | 1.436382 | 2.354181 | 2.685877 |
| 28 | 569.0 | -2.289567e-15 | 1.00088 | -2.160960 | -1.845039 | -1.251767 | -1.034661 | -0.641864 | -0.127409 | 0.450138 | 1.132518 | 3.184317 | 6.046041 |
| 29 | 569.0 | 2.575171e-15 | 1.00088 | -1.601839 | -1.405690 | -1.185223 | -1.006009 | -0.691912 | -0.216444 | 0.450762 | 1.239884 | 3.141089 | 6.846856 |
标准化完毕后,再次让SVC在核函数中遍历,此时我们把degree的数值设定为1,观察各个核函数在去量纲后的数据上的表现:
1 Kernel = ["linear","poly","rbf","sigmoid"] 2 3 for kernel in Kernel: 4 clf= SVC(kernel = kernel 5 , gamma="auto" 6 , degree = 1 7 , cache_size=5000 8 ).fit(Xtrain,Ytrain) 9 print("The accuracy under kernel %s is %f" % (kernel,clf.score(Xtest,Ytest)))
运行结果:
The accuracy under kernel linear is 0.976608
The accuracy under kernel poly is 0.964912
The accuracy under kernel rbf is 0.970760
The accuracy under kernel sigmoid is 0.953216
量纲统一之后,可以观察到,所有核函数的运算时间都大大地减少了,尤其是对于线性核来说,而多项式核函数居然变成了计算最快的。其次,rbf表现出了非常优秀的结果。经过探索,我们可以得到的结论是:
1.线性核,尤其是多项式核函数在高次项时计算非常缓慢
2.rbf和多项式核函数都不擅长处理量纲不统一的数据集
幸运的是,这两个缺点都可以由数据无量纲化来解决。因此,SVM执行之前,非常推荐先进行数据的无量纲化!到了这一步,我们是否已经完成建模了呢?虽然线性核函数的效果是最好的,但它是没有核函数相关参数可以调整的,rbf和多项式却还有着可以调整的相关参数,接下来我们就来看看这些参数。
2、选取与核函数相关的参数:degree & gamma & coef0

在知道如何选取核函数后,我们还要观察一下除了kernel之外的核函数相关的参数。对于线性核函数,"kernel"是唯一能够影响它的参数,但是对于其他三种非线性核函数,他们还受到参数gamma,degree以及coef0的影响。参数gamma就是表达式中的 ,degree就是多项式核函数的次数 ,参数coef0就是常数项 。其中,高斯径向基核函数受到gamma的影响,而多项式核函数受到全部三个参数的影响。
|
参数 |
含义 |
|
degree |
整数,可不填,默认3 多项式核函数的次数('poly'),如果核函数没有选择"poly",这个参数会被忽略 |
|
gamma |
浮点数,可不填,默认“auto" 核函数的系数,仅在参数Kernel的选项为”rbf","poly"和"sigmoid”的时候有效输入“auto",自动使用1/(n_features)作为gamma的取值 输入"scale",则使用1/(n_features * X.std())作为gamma的取值 输入"auto_deprecated",则表示没有传递明确的gamma值(不推荐使用) |
|
coef0 |
浮点数,可不填,默认=0.0 核函数中的常数项,它只在参数kernel为'poly'和'sigmoid'的时候有效。 |
但从核函数的公式来看,我们其实很难去界定具体每个参数如何影响了SVM的表现。当gamma的符号变化,或者degree的大小变化时,核函数本身甚至都不是永远单调的。所以如果我们想要彻底地理解这三个参数,我们要先推导出它们如何影响核函数地变化,再找出核函数的变化如何影响了我们的预测函数(可能改变我们的核变化所在的维度),再判断出决策边界随着预测函数的改变发生了怎样的变化。无论是从数学的角度来说还是从实践的角度来 说,这个过程太复杂也太低效。所以,我们往往避免去真正探究这些参数如何影响了我们的核函数,而直接使用学 习曲线或者网格搜索来帮助我们查找最佳的参数组合。
对于高斯径向基核函数,调整gamma的方式其实比较容易,那就是画学习曲线。我们来试试看高斯径向基核函数
rbf的参数gamma在乳腺癌数据集上的表现:
1 score = [] 2 gamma_range = np.logspace(-10, 1, 50) #返回在对数刻度上均匀间隔的数字 3 for i in gamma_range: 4 clf = SVC(kernel="rbf",gamma = i,cache_size=5000).fit(Xtrain,Ytrain) 5 score.append(clf.score(Xtest,Ytest)) 6 7 print(max(score), gamma_range[score.index(max(score))]) 8 plt.plot(gamma_range,score) 9 plt.show()
运行结果:
0.976608187135 0.0120679264064
通过学习曲线,很容就找出了rbf的最佳gamma值。但我们观察到,这其实与线性核函数的准确率一模一样之前的准确率。我们可以多次调整gamma_range来观察结果,可以发现97.6608应该是rbf核函数的极限了。
但对于多项式核函数来说,一切就没有那么容易了,因为三个参数共同作用在一个数学公式上影响它的效果,因此 我们往往使用网格搜索来共同调整三个对多项式核函数有影响的参数。依然使用乳腺癌数据集。
1 gamma_range = np.logspace(-10,1,20) 2 coef0_range = np.linspace(0,5,10) 3 4 param_grid = dict(gamma = gamma_range 5 ,coef0 = coef0_range) 6 7 cv = StratifiedShuffleSplit(n_splits=5, test_size=0.3, random_state=420) 8 grid = GridSearchCV(SVC(kernel = "poly",degree=1,cache_size=5000), param_grid=param_grid, cv=cv) 9 grid.fit(X, y) 10 11 print("The best parameters are %s with a score of %0.5f" % (grid.best_params_, grid.best_score_))
运行结果:
The best parameters are {'coef0': 0.0, 'gamma': 0.18329807108324375} with a score of 0.96959
可以发现,网格搜索为我们返回了参数coef0=0,gamma=0.18329807108324375,但整体的分数是0.96959,虽然比调参前略有提高,但依然没有超过线性核函数核rbf的结果。可见,如果最初选择核函数的时候,你就发现多项式的结果不如rbf和线性核函数,那就不要挣扎了,试试看调整rbf或者直接使用线性。
四、软间隔与重要参数C
当然,不是所有数据都是完全线性可分的。可能存在着一条直线能够将大部分数据点的类别划分正确,但无论如何也无法将全部的点分对,如同下图所展示的图,存在着混杂在红色类中的紫色点,这种情况下没有一条直线能够将两类数据完全分类正确。
关键概念:硬间隔与软间隔
当两组数据是完全线性可分,我们可以找出一个决策边界使得训练集上的分类误差为0,这两种数据就被称为是存在“硬间隔”的。当两组数据几乎是完全线性可分的,但决策边界在训练集上存在较小的训练误差,这两种数据就被称为是存在“软间隔”。

这个时候,我们的决策边界就不是单纯地寻求最大边际了,因为对于软间隔地数据来说,边际越大被分错的样本也 就会越多,因此我们需要找出一个“最大边际”与“被分错的样本数量”之间的平衡。参数C用于权衡“训练样本的正确分类”与“决策函数的边际最大化”两个不可同时完成的目标,希望找出一个平衡点来让模型的效果最佳。
|
参数 |
含义 |
|
C |
浮点数,默认1,必须大于等于0,可不填 松弛系数的惩罚项系数。如果C值设定比较大,那SVC可能会选择边际较小的,能够更好地分类所有训练点的决策边界,不过模型的训练时间也会更长。如果C的设定值较高,那SVC会尽量最大化边界,决策功能会更简单,但代价是训练的准确度。换句话说,C在SVM中的影响就像正则化参数对逻辑回归的影响。 |
在实际使用中,C和核函数的相关参数(gamma,degree等等)们搭配,往往是SVM调参的重点。与gamma不同,C没有在对偶函数中出现,并且是明确了调参目标的,所以我们可以明确我们究竟是否需要训练集上的高精确度来调整C的方向。默认情况下C为1,通常来说这都是一个合理的参数。如果我们的数据很嘈杂,那我们往往减小C。当然,我们也可以使用网格搜索或者学习曲线来调整C的值。
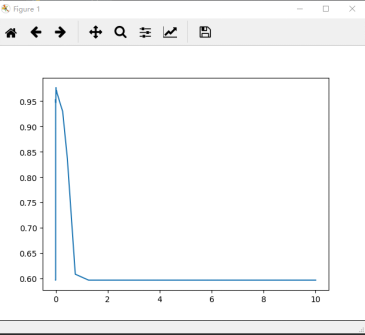
1 #调线性核函数 2 score = [] 3 C_range = np.linspace(0.01,30,50) 4 for i in C_range: 5 clf = SVC(kernel="linear",C=i,cache_size=5000).fit(Xtrain,Ytrain) 6 score.append(clf.score(Xtest,Ytest)) 7 8 print(max(score), C_range[score.index(max(score))]) 9 plt.plot(C_range,score) 10 plt.show()
运行结果:
0.976608187135 1.23408163265
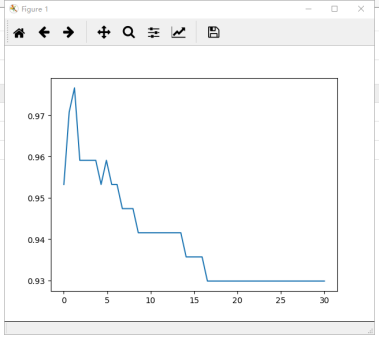
1 #换rbf 2 score = [] 3 C_range = np.linspace(0.01,30,50) 4 for i in C_range: 5 clf = SVC(kernel="rbf",C=i,gamma = 0.012742749857031322,cache_size=5000).fit(Xtrain,Ytrain) 6 score.append(clf.score(Xtest,Ytest)) 7 8 print(max(score), C_range[score.index(max(score))]) 9 plt.plot(C_range,score) 10 plt.show()
运行结果:
0.982456140351 6.13040816327
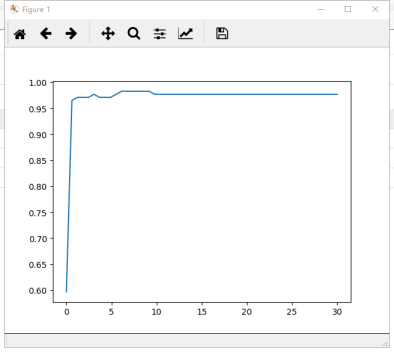
1 #进一步细化 2 score = [] 3 C_range = np.linspace(5,7,50) 4 for i in C_range: 5 clf = SVC(kernel="rbf",C=i,gamma = 0.012742749857031322,cache_size=5000).fit(Xtrain,Ytrain) 6 score.append(clf.score(Xtest,Ytest)) 7 8 print(max(score), C_range[score.index(max(score))]) 9 plt.plot(C_range,score) 10 plt.show()
运行结果:
0.982456140351 5.9387755102
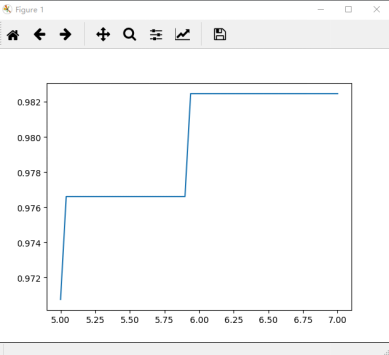
此时,我们找到了乳腺癌数据集上的最优解:rbf核函数下的98.24%的准确率。当然,我们还可以使用交叉验证来改进我们的模型,获得不同测试集和训练集上的交叉验证结果。但上述过程,为大家展现了如何选择正确的核函数,以及如何调整核函数的参数。