IO流的分类:
(1)根据处理单元来分:
字节流:InputStream , OutputStream.
字符流:Reader ,Writer
(2)根据流向来分:
输入流:InputStream , Reader
输出流:OutputStream , Writer
(3)功能是否直接与数据源/目的地相连
节点流 :直接与数据源或目的地相连的称为节点流
处理流 :不直接与数据源或目的相连称为处理流

这么庞大的体系里面,常用的就那么几个,我们把它们抽取出来,如下图:
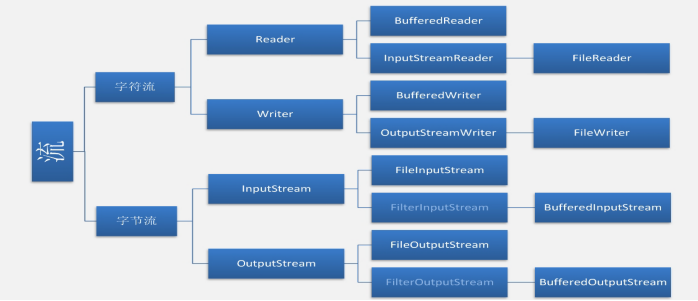
一、字节流
1:字节流
字节输入流的抽象基类是InputStream和OutputStream,常用的子类是 FileInputStream、FileOutputStream和BufferedInputStream、BufferedOutputStream。
1)FileInputStream 和 FileOutputStream
文件字节输入流:一切文件在系统中都是以字节的形式保存的,无论你是文档文件、视频文件、音频文件...,需要读取这些文件都可以用FileInputStream去读取其保存在存储介质(磁盘等)上的字节序列。
FileInputStream在创建时通过把文件名作为构造参数连接到该文件的字节内容,建立起字节流传输通道。
然后通过 read()、read(byte[])、read(byte[],int begin,int len) 三种方法从字节流中读取 一个字节、一组字节。
public static void main(String[] args) throws IOException { InputStream is =new FileInputStream("C:\Users\Administrator\Desktop\jdk api 1.8_google.CHM"); OutputStream os = new FileOutputStream("C:\Users\Administrator\Desktop\software\jdk api 1.8_google.CHM"); byte[] buf = new byte[1024]; int length = 0; long startTime = System.currentTimeMillis(); while((length = is.read(buf)) != -1){ os.write(buf,0,length); } long endTime = System.currentTimeMillis(); System.out.println("复制耗时"+(endTime-startTime)+"毫秒"); os.close(); is.close(); }
2)BufferedInputStream和BufferedOutputStream
带缓冲的字节流:上面我们知道文件字节输入流的读取时,是直接同字节流中读取的。由于字节流是与硬件(存储介质)进行的读取,所以速度较慢。而CPU需要使用数据时通过read()、read(byte[])读取数据时就要受到硬件IO的慢速度限制。我们又知道,CPU与内存发生的读写速度比硬件IO快10倍不止,所以优化读写的思路就有了:在内存中建立缓存区,先把存储介质中的字节读取到缓存区中。CPU需要数据时直接从缓冲区读就行了,缓冲区要足够大,在被读完后又触发fill()函数自动从存储介质的文件字节内容中读取字节存储到缓冲区数组。
BufferedInputStream,BufferedOutputStream 内部有一个缓冲区,默认大小为8M,每次调用read方法的时候,它首先尝试从缓冲区里读取数据,若读取失败(缓冲区无可读数据),则选择从物理数据源 (譬如文件)读取新数据(这里会尝试尽可能读取多的字节)放入到缓冲区中,最后再将缓冲区中的内容返回给用户.由于从缓冲区里读取数据远比直接从存储介质读取速度快,所以BufferedInputStream的效率很高。
/** * 使用BufferedInputStream,BufferedOutputStream复制文件 * @param args * @throws IOException */ public static void main(String[] args) throws IOException { BufferedInputStream bis = new BufferedInputStream(new FileInputStream("C:\Users\Administrator\Desktop\jdk api 1.8_google.CHM")); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("C:\Users\Administrator\Desktop\software\jdk api 1.8_google.CHM")); byte[] buf = new byte[1024]; int length = 0; long startTime = System.currentTimeMillis(); while((length = bis.read(buf)) != -1){ bos.write(buf,0,length); } long endTime = System.currentTimeMillis(); System.out.println("复制耗时"+(endTime-startTime)+"毫秒"); bos.close(); bis.close(); }