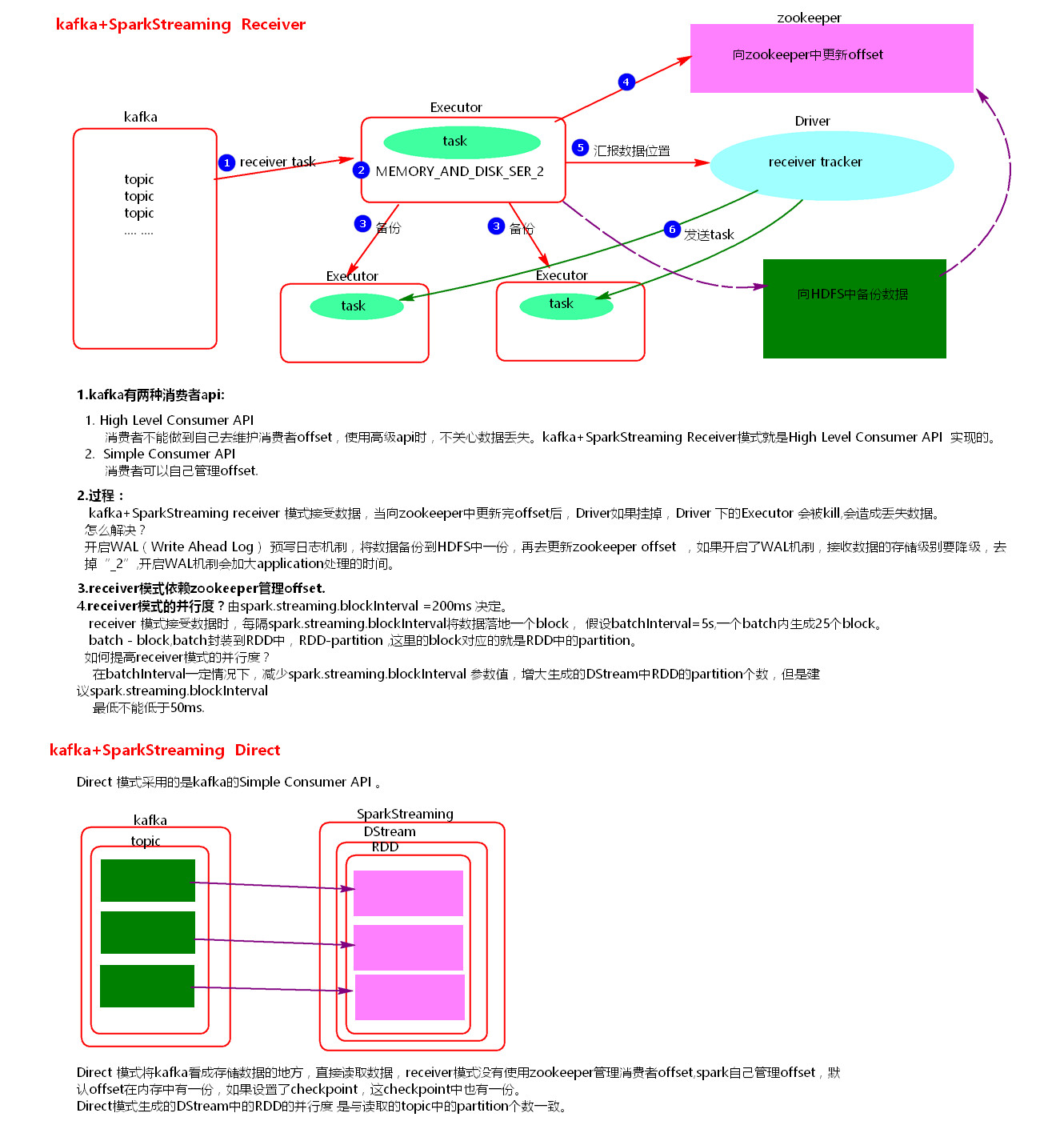
一、receiver模式
1 、receiver模式原理图
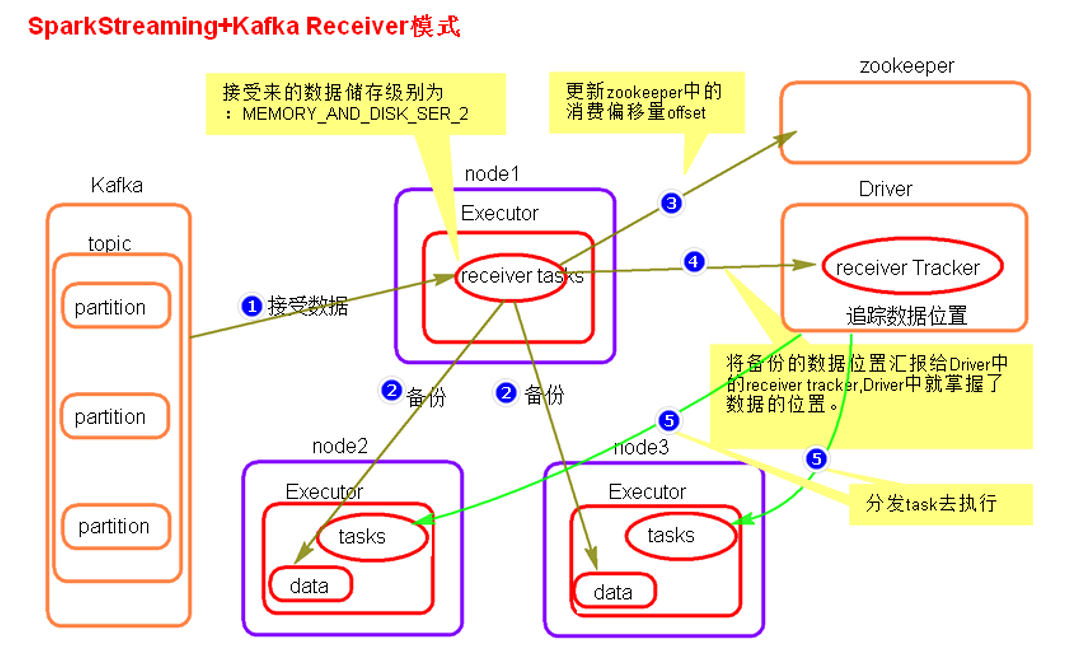
2 receiver模式理解:
在SparkStreaming程序运行起来后,Executor中会有receiver tasks接收kafka推送过来的数据。数据会被持久化,默认级别为MEMORY_AND_DISK_SER_2,这个级别也可以修改。receiver task对接收过来的数据进行存储和备份,这个过程会有节点之间的数据传输。备份完成后去zookeeper中更新消费偏移量,然后向Driver中的receiver tracker汇报数据的位置。最后Driver根据数据本地化将task分发到不同节点上执行。
3 receiver模式中存在的问题
当Driver进程挂掉后,Driver下的Executor都会被杀掉,当更新完zookeeper消费偏移量的时候,Driver如果挂掉了,就会存在找不到数据的问题,相当于丢失数据。
4 如何解决这个问题?
开启WAL(write ahead log)预写日志机制,在接受过来数据备份到其他节点的时候,同时备份到HDFS上一份(我们需要将接收来的数据的持久化级别降级到MEMORY_AND_DISK),这样就能保证数据的安全性。不过,因为写HDFS比较消耗性能,要在备份完数据之后才能进行更新zookeeper以及汇报位置等,这样会增加job的执行时间,这样对于任务的执行提高了延迟度。
- receiver模式代码(见代码)
/** * receiver 模式并行度是由blockInterval决定的 * @author root * */ public class SparkStreamingOnKafkaReceiver { public static void main(String[] args) { SparkConf conf = new SparkConf().setAppName("SparkStreamingOnKafkaReceiver") .setMaster("local[2]"); //开启预写日志 WAL机制 conf.set("spark.streaming.receiver.writeAheadLog.enable","true"); JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5)); jsc.checkpoint("./receivedata"); Map<String, Integer> topicConsumerConcurrency = new HashMap<String, Integer>(); /** * 设置读取的topic和接受数据的线程数 */ topicConsumerConcurrency.put("t0404", 1); /** * 第一个参数是StreamingContext * 第二个参数是ZooKeeper集群信息(接受Kafka数据的时候会从Zookeeper中获得Offset等元数据信息) * 第三个参数是Consumer Group 消费者组 * 第四个参数是消费的Topic以及并发读取Topic中Partition的线程数 * * 注意: * KafkaUtils.createStream 使用五个参数的方法,设置receiver的存储级别 */ JavaPairReceiverInputDStream<String,String> lines = KafkaUtils.createStream( jsc, "node3:2181,node4:2181,node5:2181", "MyFirstConsumerGroup", topicConsumerConcurrency); // JavaPairReceiverInputDStream<String,String> lines = KafkaUtils.createStream( // jsc, // "node3:2181,node4:2181,node5:2181", // "MyFirstConsumerGroup", // topicConsumerConcurrency/*, // StorageLevel.MEMORY_AND_DISK()*/); JavaDStream<String> words = lines.flatMap(new FlatMapFunction<Tuple2<String,String>, String>() { /** * */ private static final long serialVersionUID = 1L; public Iterable<String> call(Tuple2<String,String> tuple) throws Exception { return Arrays.asList(tuple._2.split(" ")); } }); JavaPairDStream<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() { /** * */ private static final long serialVersionUID = 1L; public Tuple2<String, Integer> call(String word) throws Exception { return new Tuple2<String, Integer>(word, 1); } }); JavaPairDStream<String, Integer> wordsCount = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() { //对相同的Key,进行Value的累计(包括Local和Reducer级别同时Reduce) /** * */ private static final long serialVersionUID = 1L; public Integer call(Integer v1, Integer v2) throws Exception { return v1 + v2; } }); wordsCount.print(100); jsc.start(); jsc.awaitTermination(); jsc.close(); } }
- receiver的并行度设置
receiver的并行度是由spark.streaming.blockInterval来决定的,默认为200ms,假设batchInterval为5s,那么每隔blockInterval就会产生一个block,这里就对应每批次产生RDD的partition,这样5秒产生的这个Dstream中的这个RDD的partition为25个,并行度就是25。如果想提高并行度可以减少blockInterval的数值,但是最好不要低于50ms。
二、directed
1 Direct模式理解
SparkStreaming+kafka 的Driect模式就是将kafka看成存数据的一方,不是被动接收数据,而是主动去取数据。消费者偏移量也不是用zookeeper来管理,而是SparkStreaming内部对消费者偏移量自动来维护,默认消费偏移量是在内存中,当然如果设置了checkpoint目录,那么消费偏移量也会保存在checkpoint中。当然也可以实现用zookeeper来管理。
2 Direct模式并行度设置
Direct模式的并行度是由读取的kafka中topic的partition数决定的。
3 Direct模式代码
/** * 并行度: * 1、linesDStram里面封装到的是RDD, RDD里面有partition与读取topic的parititon数是一致的。 * 2、从kafka中读来的数据封装一个DStram里面,可以对这个DStream重分区 reaprtitions(numpartition) * * @author root * */ public class SparkStreamingOnKafkaDirected { public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local").setAppName("SparkStreamingOnKafkaDirected"); // conf.set("spark.streaming.backpressure.enabled", "false"); // conf.set("spark.streaming.kafka.maxRatePerPartition ", "100"); JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(5)); /** * 可以不设置checkpoint 不设置不保存offset,offset默认在内存中有一份,如果设置checkpoint在checkpoint也有一份offset, 一般要设置。 */ jsc.checkpoint("./checkpoint"); Map<String, String> kafkaParameters = new HashMap<String, String>(); kafkaParameters.put("metadata.broker.list", "node1:9092,node2:9092,node3:9092"); // kafkaParameters.put("auto.offset.reset", "smallest"); HashSet<String> topics = new HashSet<String>(); topics.add("t0404"); JavaPairInputDStream<String,String> lines = KafkaUtils.createDirectStream(jsc, String.class, String.class, StringDecoder.class, StringDecoder.class, kafkaParameters, topics); JavaDStream<String> words = lines.flatMap(new FlatMapFunction<Tuple2<String,String>, String>() { //如果是Scala,由于SAM转换,所以可以写成val words = lines.flatMap { line => line.split(" ")} /** * */ private static final long serialVersionUID = 1L; public Iterable<String> call(Tuple2<String,String> tuple) throws Exception { return Arrays.asList(tuple._2.split(" ")); } }); JavaPairDStream<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() { /** * */ private static final long serialVersionUID = 1L; public Tuple2<String, Integer> call(String word) throws Exception { return new Tuple2<String, Integer>(word, 1); } }); JavaPairDStream<String, Integer> wordsCount = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() { //对相同的Key,进行Value的累计(包括Local和Reducer级别同时Reduce) /** * */ private static final long serialVersionUID = 1L; public Integer call(Integer v1, Integer v2) throws Exception { return v1 + v2; } }); wordsCount.print(); jsc.start(); jsc.awaitTermination(); jsc.close(); } }
三、相关配置
预写日志:
|
spark.streaming.receiver.writeAheadLog.enable 默认false没有开启 |
blockInterval:
|
spark.streaming.blockInterval 默认200ms |
反压机制:
|
spark.streaming.backpressure.enabled 默认false |
接收数据速率:
|
spark.streaming.receiver.maxRate 默认没有设置 |
总结: