一、Flume 简述
Flume是什么:通俗地说 Flume 就是一个日志采集工具。官网解释:Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data.
特性:高可用、高可靠、具有分布式处理模式,可对数据进行简单处理。
版本进化过程:分为 Flume-og(0.9x 已停止更新了)、Flume-ng(1.x) 两个版本,Flume-ng最明显的改动就是取消了集中管理配置的 Master 和 Zookeeper,变为一个纯粹的传输工具。Flume-ng另一个主要的不同点是读入数据和写出数据现在由不同的工作线程处理(称为 Runner)。在 Flume-og 中,读入线程同样做写出工作(除了故障重试)。如果写出慢的话(不是完全失败),它将阻塞 Flume 接收数据的能力。
数据处理方面: Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力 。提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统),支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。
二、Flume架构
(1)典型模式
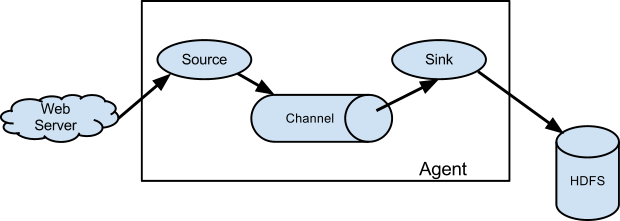
参考:https://blog.csdn.net/u013850277/article/details/77575075
各组件职责
Source :
负责日志流入,比如从文件、网络、Kafka等数据源流入数据,数据流入的方式有两种:轮训拉取和事件驱动。
Channel :
负责数据聚合或暂存,比如暂存到内存、本地文件、数据库、Kafka 等,日志数据不会在管道停留很长时间,很快会被 Sink 消费掉。
Sink :
也叫接收器,负责数据转移存储,比如从Channel拿到日志后直接存储到HDFS、Hbase、ElasticSearch、Kafka 等。
细分 Flume 数据流应该是由5个组件组成:Events、Sources、Channels、Sink、Agent。基中三个如上所述,Events与Agent 如下:
Events :
是使用Flume移动的数据的基本单位。它类似于JMS中的消息,通常很小。它由头和字节数组体组成。
# Name the components on this agent 提前声明定义好source,channel,sink a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = node01 a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel 相互联结channel,source,sink a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
将该段代码写入一个文件中,使用一下代码执行该配置
flume-ng agent --conf-file opertion --name a1 -Dflume.root.logger=INFO,console
(该配置的输入源需要另起一个节点通过 -- telnet 对其进行输入)

可以看到该代理上显示

(2)常见模式
-
Setting multi-agent flow(设置多个agent流)

为了让数据可以流过多个agents或者hops,前面那个agent的sink和当前的hop的source都必须是avro类型并且sink还要指向source的主机名(IP地址)和端口。
这种模式是将多个flume给顺序连接起来了,从最初的source开始到最终sink传送的目的存储系统。此模式不建议桥接过多的flume数量,就像路由器的桥接一样,多了网速会慢,flume过多不仅会影响传输速率,而且一旦传输过程中某个节点flume宕机,会影响整个传输系统。
(1)本模式用到两个节点node01和node02
node01启动配制为
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = node01 a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = node02 a1.sinks.k1.port = 10086 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
node02启动配制为:
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = avro a1.sources.r1.bind =node02 a1.sources.r1.port = 10086 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
-
Consolidation(结合)

这种模式也是我们日常常见的,也非常实用,日常web应用通常分布在上百个服务器,大者甚至上千个、上万个服务器。
产生的日志,处理起来也非常麻烦。用flume的这种组合方式能很好的解决这一问题,每台服务器一个flume采集日志,传送到
一个集中收集日志的flume,再由此flume上传到hdfs、hive、hbase、kafka、或者入到数据库,进行日志分析。
该模式可以去参考:https://www.e-learn.cn/content/qita/788983 实现!
-
Multiplexing the flow(选择分流)
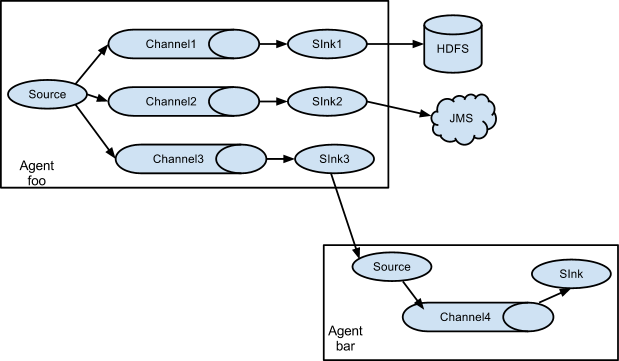
此模式,Flume支持将事件流向一个或者多个目的地。这个可以通过定义一个流的能够复制或者可选路径的多路选择器来将事件导向一个或者多个Channel来实现。
这种模式将数据源复制到多个channel中,每个channel都有相同的数据,sink可以选择传送的不同的目的地。