1、用户界面
1)点击读取文件按钮,读取到的文件如下图所示:
数据聚类系统读取文件

数据聚类系统导入文件
2)设置簇的个数,这里设置成2,并选择K-means聚类算法,显示的结果如下图:
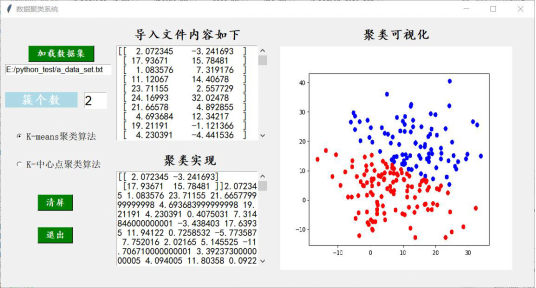
数据聚类系统运行K-means聚类算法
3)设置簇的个数,这里设置成2,并选择K-中心点聚类算法,显示的结果如下图:
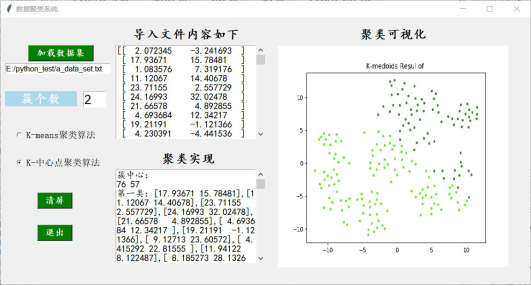
数据聚类系统运行K-中心点聚类算法
4)清屏,显示的结果如下图:

数据聚类系统清屏
2、实验源码
编译环境为Spyder,所用语言及版本为python3.7,GUI环境为tkinter。
1)主运行界面 kmedgui.py
# -*- coding: utf-8 -*-
import sys
import random
import kmeans
import k_medoids_2d as k2d
import numpy as np
import tkinter as tk
from tkinter import filedialog
from tkinter import scrolledtext
from PIL import Image,ImageTk
import matplotlib.pyplot as plt
import sklearn
class GUI(object):
#布局界面
def __init__(self):
#设置初始界面
self.window=tk.Tk()
self.window.title('数据聚类系统')
self.window.geometry('1150x580')
#导入文件按钮
self.botton1=tk.Button(self.window, text='加载数据集',bg='green',fg='white', font=('楷体', 12, 'bold'), width=12, height=1,command=self.openfile)
self.botton1.place(x=60,y=60)
#标签配置
self.label2=tk.Label(self.window, text='簇个数',bg='light blue',fg='white', font=('楷体', 16, 'bold'), width=10, height=1).place(x=10,y=160)
#导入文件内容的输出显示
self.label4=tk.Label(self.window, text='导入文件内容如下',font=('楷体', 16, 'bold'), width=16, height=1).place(x=280,y=20)
#创建结果显示框
self.text1=scrolledtext.ScrolledText(self.window, height=10, width=30,font=('楷体', 12))
self.text1.place(x=250,y=60)
self.text1.bind("<Button-1>",self.clear)
#各个频繁项集和强关联规则的输出显示
self.label5=tk.Label(self.window, text='聚类实现',font=('楷体', 16, 'bold'), width=20, height=1).place(x=255,y=290)
self.label6=tk.Label(self.window, text='聚类可视化',font=('楷体', 16, 'bold'), width=20, height=1).place(x=700,y=20)
#创建结果显示框
self.text2=scrolledtext.ScrolledText(self.window, height=10, width=30,font=('楷体', 12))
self.text2.place(x=250,y=330)
self.text2.bind("<Button-1>",self.clear)
#显示导入文件的路径
self.var0=tk.StringVar()
self.entry1=tk.Entry(self.window, show=None, width='25', font=('Arial', 10), textvariable=self.var0)
self.entry1.place(x=10,y=100)
#自行设置簇个数,个数为2
self.var1=tk.StringVar()
self.var1.set('2')
self.entry2=tk.Entry(self.window, show=None, width='3', font=('Arial', 16), textvariable=self.var1)
self.entry2.place(x=180,y=160)
#选择所需算法
self.btnlist=tk.IntVar()
self.radiobtn1=tk.Radiobutton(self.window, variable=self.btnlist, value=0, text='K-means聚类算法', font=('bold'),command=self.runkmeans)
self.radiobtn1.place(x=30,y=240)
self.radiobtn2=tk.Radiobutton(self.window, variable=self.btnlist, value=1,text='K-中心点聚类算法', font=('bold'), command=self.runkmid)
self.radiobtn2.place(x=30,y=300)
self.btnlist.set(0)
#清空页面按钮
self.btn2=tk.Button(self.window, bg='green',fg='white', text='清屏', font=('楷体', 12,'bold'), width=6, height=1)
self.btn2.place(x=80,y=380)
self.btn2.bind("<Button-1>",self.clear)
#关闭页面按钮
self.btn3=tk.Button(self.window, bg='green',fg='white', text='退出', font=('楷体', 12,'bold'), width=6, height=1)
self.btn3.place(x=80,y=450)
self.btn3.bind("<Button-1>",self.close)
self.pilImage = Image.open("white.png")
img=self.pilImage.resize((500,480))
self.tkImage = ImageTk.PhotoImage(image=img)
self.label = tk.Label(self.window, image=self.tkImage)
self.label.place(x=600,y=60)
#主窗口循环显示
self.window.mainloop()
#清空所填内容
def clear(self,event):
self.text1.delete("1.0",tk.END)
self.text2.delete("1.0",tk.END)
self.pilImage = Image.open("white.png")
img=self.pilImage.resize((500,480))
self.tkImage = ImageTk.PhotoImage(image=img)
self.label = tk.Label(self.window, image=self.tkImage)
self.label.place(x=600,y=60)
self.label.configure(image = img)
self.window.update_idletasks()
#退出系统,对控制台清屏
def close(self,event):
e=tk.messagebox.askokcancel('询问','确定退出系统吗?')
if e==True:
exit()
self.window.destroy()
# 恢复sys.stdout
def __del__(self):
sys.stdout = sys.__stdout__
sys.stderr = sys.__stderr__
#从输入文本框中获取文本并返回数字列表
def getCNUM(self):
entry_num1 = int(self.var1.get())
return entry_num1
def openfile(self):
nameFile = filedialog.askopenfilename(title='打开文件', filetypes=[('txt', '*.txt')])
self.entry1.insert('insert', nameFile)
def getnamefile(self):
namefile=self.var0.get()
return namefile
#加载kmeans所需的数据集
def loadDataSet1(self):
nameFile=self.getnamefile()
data = np.loadtxt(nameFile,delimiter=' ')
self.text1.insert("0.0",data)
return data
#加载k-中点所需的数据集
def loadDataSet2(self):
data = []
for i in range(100):
data.append(0 + i)
for i in range(100):
data.append(1000 + i)
random.shuffle(data)
return data
def runkmeans(self):
dataSet = self.loadDataSet1()
k = self.getCNUM()
c=kmeans.randCent(dataSet, k)
centroids,clusterAssment = kmeans.KMeans(dataSet,k)
self.text2.insert('insert',c)
c1,c2,c3,c4=kmeans.showCluster(dataSet,k,centroids,clusterAssment)
self.text2.insert('insert',c1)
t0='
'
self.text2.insert('insert',t0)
self.text2.insert('insert',c2)
self.text2.insert('insert',t0)
self.text2.insert('insert',c3)
self.text2.insert('insert',t0)
self.text2.insert('insert',c4)
kmeans.showCluster(dataSet,k,centroids,clusterAssment)
self.pilImage = Image.open("kpic.png")
img=self.pilImage.resize((500,480))
self.tkImage = ImageTk.PhotoImage(image=img)
self.label = tk.Label(self.window, image=self.tkImage)
self.label.place(x=600,y=60)
self.label.configure(image = img)
self.window.update_idletasks()
def runkmid(self):
data=k2d.im_txt("a_data_set.txt")
self.text1.insert("0.0",data)
data_TSNE = sklearn.manifold.TSNE(learning_rate=100,n_iter=5000).fit_transform(data)
k=self.getCNUM()
t='簇中心:
'
t1='
'
self.text2.insert('insert',t)
centers,result_clusters = k2d.KMedoids(k,data,10)
self.text2.insert('insert',centers)
self.text2.insert('insert',t1)
color=k2d.randomcolor(k)
colors = ([color[k] for k in result_clusters])
color = ['black']
plt.scatter(data_TSNE[:,0],data_TSNE[:,1],s=10,c=colors)
plt.title('K-medoids Resul of '.format(str(k)))
plt.savefig("kpic1.png")
s1="第一类:"
s2="第二类:"
s3="第三类:"
s4="第四类:"
m=1
for m in range(len(result_clusters)):
if result_clusters[m]==0:
s1=s1+str(data[m])+","
if result_clusters[m]==1:
s2=s2+str(data[m])+","
if result_clusters[m]==2:
s3=s3+str(data[m])+","
if result_clusters[m]==3:
s4=s4+str(data[m])+","
self.text2.insert('insert',s1)
t1='
'
self.text2.insert('insert',t1)
self.text2.insert('insert',s2)
self.text2.insert('insert',t1)
self.text2.insert('insert',s3)
self.text2.insert('insert',t1)
self.text2.insert('insert',s4)
self.pilImage = Image.open("kpic1.png")
img=self.pilImage.resize((500,480))
self.tkImage = ImageTk.PhotoImage(image=img)
self.label = tk.Label(self.window, image=self.tkImage)
self.label.place(x=600,y=60)
self.label.configure(image = img)
self.window.update_idletasks()
if __name__ == '__main__':
GUI()
2)导入的kmeans.py
import numpy as np
import matplotlib.pyplot as plt
# 加载数据
def loadDataSet(fileName):
data = np.loadtxt(fileName,delimiter=' ')
return data
# 欧氏距离计算
def distEclud(x,y):
return np.sqrt(np.sum((x-y)**2)) # 计算欧氏距离
# 为给定数据集构建一个包含K个随机质心的集合
def randCent(dataSet, k):
m, n = dataSet.shape
centroids = np.zeros((k, n))
for i in range(k):
centroids[i, :] = dataSet[i, :]
print('质心:')
print(centroids,end=" ")
return centroids
# k均值聚类
def KMeans(dataSet,k):
m = np.shape(dataSet)[0] #行的数目
# 第一列存样本属于哪一簇
# 第二列存样本的到簇的中心点的误差
clusterAssment = np.mat(np.zeros((m,2)))
clusterChange = True
# 第1步 初始化centroids
centroids = randCent(dataSet,k)
while clusterChange:
clusterChange = False
# 遍历所有的样本(行数)
for i in range(m):
minDist = 100000.0
minIndex = -1
# 遍历所有的质心
#第2步 找出最近的质心
for j in range(k):
# 计算该样本到质心的欧式距离
distance = distEclud(centroids[j,:],dataSet[i,:])
if distance < minDist:
minDist = distance
minIndex = j
# 第 3 步:更新每一行样本所属的簇
if clusterAssment[i,0] != minIndex:
clusterChange = True
clusterAssment[i,:] = minIndex,minDist**2
#第 4 步:更新质心
for j in range(k):
pointsInCluster = dataSet[np.nonzero(clusterAssment[:,0].A == j)[0]] # 获取簇类所有的点
centroids[j,:] = np.mean(pointsInCluster,axis=0) # 对矩阵的行求均值
return centroids,clusterAssment
def showCluster(dataSet,k,centroids,clusterAssment):
m,n = dataSet.shape
if n != 2:
print("数据不是二维的")
return 1
mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr']
if k > len(mark):
print("k值太大了")
return 1
# 绘制所有的样本
for i in range(m):
markIndex = int(clusterAssment[i,0])
plt.plot(dataSet[i,0],dataSet[i,1],mark[markIndex])
clu_1 = []
clu_2 = []
clu_3 = []
clu_4 = []
# 绘制所有的样本
for i in range(m):
markIndex = int(clusterAssment[i, 0])
if markIndex == 0:
clu_1.append(dataSet[i, 0])
if markIndex == 1:
clu_2.append(dataSet[i, 0])
if markIndex == 2:
clu_3.append(dataSet[i, 0])
if markIndex == 3:
clu_4.append(dataSet[i, 0])
plt.plot(dataSet[i, 0], dataSet[i, 1], mark[markIndex])
print("")
print("c1:",clu_1)
print("c2:",clu_2)
print("c3:",clu_3)
print("c4:",clu_4)
mark = ['Dr', 'Db', 'Dg', 'Dk', '^b', '+b', 'sb', 'db', '<b', 'pb']
# 绘制质心
for i in range(k):
plt.plot(centroids[i,0],centroids[i,1],mark[i])
plt.savefig("kpic.png")
return clu_1,clu_2,clu_3,clu_4
3)导入的k_medoid.py
import numpy as np
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import random
def im_txt(file):
"""
读取数据
"""
data=np.loadtxt(file,dtype=np.float32)
return data
def initianlize_centers(n_clusters):
"""初始化,生成随机聚类中心"""
n_data=lendata()
centers=[] #聚类中心位置信息例:[101,205,5,3,7]
i=0
while i<n_clusters:
temp=random.randint(0,n_data-1)
if temp not in centers:
centers.append(temp)
i=i+1
else:
pass
return centers
def clus_process(centers,data):
"""根据聚类中心进行聚类"""
result_clusters=[]
centers=np.array(centers)
"""遍历每个样本"""
for i in range(0,len(data)):
uni_temp=[] #临时存储距离数据
for j in centers:
temp=np.sqrt(np.sum(np.square(data[i]-data[j])))
uni_temp.append(temp)
c_min=min(uni_temp) #距离最小值
result_clusters.append(uni_temp.index(c_min)) #距离最小值所在位置即为归属簇
return result_clusters
def chose_centers(result_clusters,n_clusters):
global c_temp
centers=[]
for i in range(0,n_clusters): #逐个簇进行随机
temp=[] #记录每个簇样本在data中的位置
for j in range(0,len(result_clusters)): #遍历每个样本
if result_clusters[j]==i: #寻找簇i的样本
temp.append(j)
try:
c_temp=random.sample(temp,1) #在样本中随机取一个值作为新的聚类中心
except:
print("sample bug")
print(temp)
centers.append(c_temp[0])
return centers
def count_E(centers_new,data,result_clusters_new):
"""计算价值函数"""
E=0
for i in range(0,len(centers_new)):
for j in range(0,len(data)):
if result_clusters_new[j]==i:
temp=np.sqrt(np.sum(np.square(data[j]-data[centers_new[i]])))
E+=temp
return E
def KMedoids(n_clusters,data,max_iter):
"""初始化"""
centers=initianlize_centers(n_clusters)
"""根据随机中心进行聚类"""
result_clusters=clus_process(centers,data)
"""重新选择聚类中心,并比较"""
xie=0 #计数器
E=5*5000
"""
_old:用来记录上一次的聚类结果
_new:新一次聚类的结果
无old和new:输出结果
"""
while xie<=max_iter:
centers_new=chose_centers(result_clusters,n_clusters) #新的聚类中心
result_clusters_new=clus_process(centers,data) #新的聚类结果
"""计算价值函数E"""
E_new=count_E(centers_new,data,result_clusters_new)
"""价值函数变小,则更新聚类中心和聚类结果"""
if E_new<E:
centers=centers_new
result_clusters=result_clusters_new
E=E_new
t=""
y=""
t=t+"价值函数为:"+str(E)+"
"
# print("价值函数为:%s"%E)
y=y+"聚类中心:"+str(centers)+"
"
# print("聚类中心:%s"%centers)
print(t)
print(y)
xie=0
"""阈值计数器"""
xie=xie+1
return centers,result_clusters
def randomcolor(x):
"""随机生成十六进制编码"""
colors=[]
i=0
while i<x:
colorArr = ['1','7','A','F']
# colorArr = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr']
color = ""
j=0
while j<6:
color += colorArr[random.randint(0,3)]
j=j+1
color="#"+color
if color in colors:
continue
else:
colors.append(color)
i=i+1
return colors
def lendata():
file="a_data_set.txt"
data=im_txt(file)
n_data=len(data)
return n_data