1.冒泡排序
# 冒泡排序在遍历时,每次只比较相邻的两个元素,并把较大的元素放在后面。
# 冒泡排序的每次遍历,得到的较大数的位置都会被确定。
# 是稳定的原地排序算法。
# 最好情况下,要排序的数据已经是有序的,只需要进行一次冒泡操作,最好情况时间复杂度是O(n);最坏的情况是要排序的数据刚好是倒序排列,需要进行n次冒泡操作,时间复杂度是O(n2)。
1 def bubble_sort(alist): 2 """冒泡排序""" 3 n = len(alist) 4 for j in range(0, n-1): 5 sorted_flag = False # 提前退出冒泡循环的标志位,减少不必要的比较,优化算法 6 for i in range(0, n-1-j): 7 if alist[i] > alist[i+1]: 8 alist[i], alist[i+1] = alist[i+1], alist[i] 9 sorted_flag = True 10 if sorted_flag is False: 11 break 12 13 if __name__ == "__main__": 14 li = [12, 4, 32, 45, 333, 234, 23] 15 bubble_sort(li) 16 print(li) # [4, 12, 23, 32, 45, 234, 333]
2.选择排序
# 选择排序算法的实现思路:数据划分已排序区间和未排序区间,选择排序每次会从未排序区间中找到最小的元素,将其与未排序区间的头部交换。
# 具体排序步骤:
A.列表分成:有序序列部分和无序序列部分,每次遍历从无序序列中选出最小的,放在有序的序列中;
B.第一次从位置0开始遍历,选出最小的元素与位置0的元素交换位置;
C.第二次从位置1开始遍历,选出次小的元素与位置1的元素交换位置;
D.第三次从位置2开始遍历,选出再次小的元素与位置2的元素交换位置;
E. ...。
# 是不稳定的原地排序算法。
# 最好、最坏时间复杂度都是O(n2)。
1 def select_sort(alist): 2 """选择排序""" 3 n = len(alist) 4 for j in range(0, n-1): # j是遍历次数,无序序列最后剩下的元素肯定是最大值,不用遍历 5 min_index = j # 记录最小值位置 6 for i in range(j+1, n): # 从无序序列中选最小值 7 if alist[min_index] > alist[i]: 8 min_index = i # 找最小值所在位置 9 alist[min_index], alist[j] = alist[j], alist[min_index] 10 11 if __name__ == "__main__": 12 li = [54, 26, 93, 17, 77, 31, 44, 55, 20] 13 select_sort(li) 14 print(li) # [17, 20, 26, 31, 44, 54, 55, 77, 93]
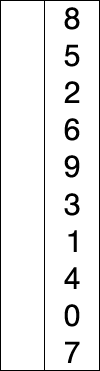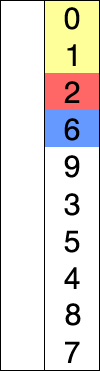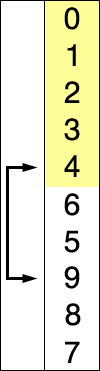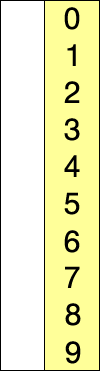
3.插入排序
# 插入排序算法的思想:数据划分已排序区间和未排序区间,初始的已排序区间只有一个元素,即数组的第一个元素。然后取未排序区间的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间数据一直有序,重复这个过程,直到未排序区间中元素为空,算法结束。
# 具体排序步骤:
A.列表分成:有序序列部分和无序序列部分,每次选无序序列的第一个,插入到有序序列中的正确位置;
B.每次选出的无序序列的第一个元素,都从有序序列的最后一个元素往前与之比较;
C.若被选出的无序序列的第一个元素比有序序列的某个元素小,则互换位置(升序排列),反之找到正确的插入位置。
# 是稳定的原地排序算法。
# 最好情况下,要排序的数据已经是有序的,不需要搬移任何数据,只需要从尾到头遍历已经有序的数据,所以最好时间复杂度为
O(n);最坏情况下,数据是倒序的,每次插入都相当于在数据的第一个位置插入新的数据,需要移动大量的数据,所以最坏情况时间复杂度为 O(n2)。
1 def insert_sort(alist): 2 """插入排序""" 3 n = len(alist) 4 for j in range(1, n): # 刚开始时,默认列表位置0的元素为最小值 5 for i in range(j, 0, -1): # 下标在有序序列中前移一位,然后继续比较 6 # j也是有序序列中进行比较的起始位置,因为比较是从后往前进行 7 if alist[i] < alist[i-1]: 8 alist[i], alist[i-1] = alist[i-1], alist[i] 9 else: 10 break # 优化算法,减少不必要的比较 11 12 if __name__ == "__main__": 13 li = [54, 26, 93, 17, 77, 31, 44, 55, 20] 14 insert_sort(li) 15 print(li)
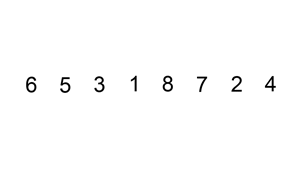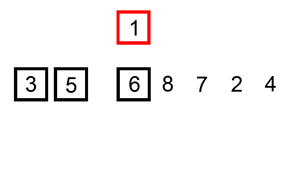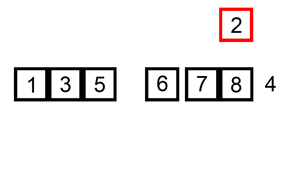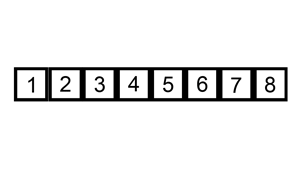
4.快速排序
# 快速排序算法利用的是分治思想:如果要排序数组的下标从p到r,选择p到r之间的任意一个数据作为pivot(分区点),遍历p到r之间的数据,将小于pivot的放到左边,将大于pivot的放到右边,将pivot放到中间。经过这一步骤之后,数组p到r之间的数据就被分成了三个部分,前面p到q-1之间都是小于pivot的,中间是pivot,后面的q+1到r之间是大于pivot的。
# 具体排序步骤:
A.在数据列表中找到一个分区点元素,小于分区点的数据都放在其左边,大于分区点的数据都放在其右边;
B.分区后的数据子列表的最左侧元素,可以保存为该分区子列表下一轮分区操作的分区点;
C.需要一个low游标指向小于分区点的数据,也需要一个high游标指向大于分区点的数据。在每个分区内,low从列表最左侧往右遍历,high从列表最右侧往左遍历;
D.最开始时,low指向第一个分区点,分区点的值被保存下来,然后置空low指向的值;
E.如果选列表最左侧元素作为分区点,则应先从high游标开始比较;
F.如果high所指的值大于分区点,high左移一位,如果low所指的值小于分区点,low右移一位;
G.如果high指向的值小于分区点时,把该值移动至low所在的位置,置空high所指的值,并固定high的位置;此时low所指的值小于分区点,low右移;如果low指向的值大于分区点时,把该值移动至high所在的空位置,置空low所指的值,并固定low的位置;此时high所指的值大于分区点,high左移;
H.当low与high会合时,该位置就是分区点应该所处的正确位置。
# 是不稳定的原地排序算法。
# 最好情况下,如果每次分区操作,选择的分区点都很合适,正好能将大区间对等地一分为二,此时快速排序算法对应的的最好情况时间复杂度是O(nlogn);最坏情况下,如果数组中的数据原来已经是有序的,若每次选择最后一个元素作为分区点,则需要进行大约n次分区操作,才能完成快排的整个过程,每次分区平均要扫描大约n/2个元素,这种情况对应的最坏情况时间复杂度是O(n2)。
1 def quick_sort(alist, first, last): # first是第一个元素的下标,last是最后一个元素的下标 2 """快速排序""" 3 if first >= last: # 递归终止条件:当下标first不小于下标last时,排序结束 4 return 5 mid_value = alist[first] # 保存分区点 6 low, high = first, last 7 8 while low < high: # 控制high与low交替移动 9 while low < high: # 当游标还没有会合的时候,先比较high指向的数据 10 if alist[high] >= mid_value: # '='只需在一边判断即可,以保证相等的数据都在分区点同侧 11 high -= 1 # high左移 12 else: break 13 alist[low] = alist[high] 14 while low < high: # 当游标还没有会合的时候,再比较low指向的数据 15 if alist[low] < mid_value: 16 low += 1 # low右移 17 else: break 18 alist[high] = alist[low] 19 alist[low] = mid_value # 大循环退出时,low=high,需要把保存的分区点放在该位置处 20 21 # 由于快排只在一个数据列表内操作(原地排序),所以递归时不能使用列表切片作为子列表来传递参数 22 quick_sort(alist, first, low-1) # 对分区点左边的子列表排序 23 quick_sort(alist, low+1, last) # 对分区点右边的子列表排序 24 25 if __name__ == "__main__": 26 li = [54, 26, 93, 17, 77, 31, 44, 55, 20] 27 quick_sort(li, 0, len(li)-1) 28 print(li) # [17, 20, 26, 31, 44, 54, 55, 77, 93]

5.归并排序
# 归并排序的核心思想:如果要排序一个数组,先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就全部有序。
# 具体排序步骤:
A.归并排序需要先进行不断地拆分,直至拆分后的数据子序列只包含一个元素;
B.先两两比较并排序,然后两两合并形成新的子序列,接着再两两比较并排序合并后的子序列,然后再合并...;
C.在比较、合并时,需要一个left游标指向一个子序列的最左边,一个right游标指向另一个子序列的最左边;
D.left与right指向的数据进行比较,将较小的值存放进新列表,该值的游标右移一位,然后继续比较。
# 是稳定的非原地排序算法。
# 归并排序的执行效率与要排序的原始数组的有序程度无关,其时间复杂度非常稳定,最好情况时间复杂度、最坏情况时间复杂度都是O(nlogn)。
1 def merge_sort(alist): 2 """归并排序""" 3 n = len(alist) 4 if n <= 1: # 递归拆分的终止条件 5 return alist 6 mid = n // 2 7 left_li = merge_sort(alist[:mid]) # left与right是归并排序后,形成的新的有序子列表 8 right_li = merge_sort(alist[mid:]) 9 10 left_p, right_p = 0, 0 11 result = [] # 存放合并的结果值 12 while left_p < len(left_li) and right_p < len(right_li): # 控制比较的过程 13 if left_li[left_p] <= right_li[right_p]: # 存放较小值,等号保证相等值在同侧 14 result.append(left_li[left_p]) 15 left_p += 1 16 else: 17 result.append(right_li[right_p]) # 存放较小值 18 right_p += 1 19 result += left_li[left_p:] # 将left_li或right_li剩下的元素添加进来 20 result += right_li[right_p:] 21 22 return result 23 24 if __name__ == "__main__": 25 li = [54, 26, 93, 17, 77, 31, 44, 55, 20] 26 sorted_li = merge_sort(li) # 由于算法是非原地算法,排序后的结果存储在了另一个列表中 27 print(sorted_li) # [17, 20, 26, 31, 44, 54, 55, 77, 93]
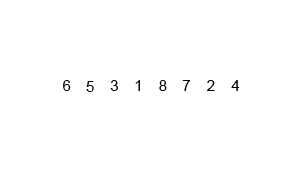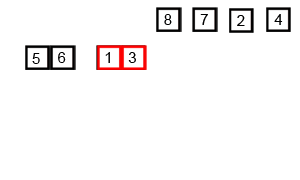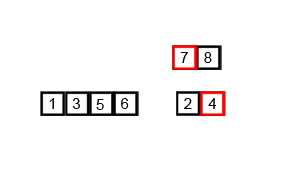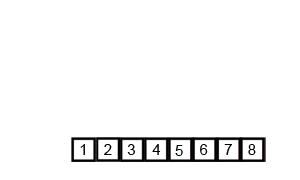
6.计数排序
# 计数排序要求要排序的n个数据所处的范围并不大,比如最大值是k,我们就可以把数据划分成k个桶。
# 每个桶内的数据值都是相同的,省掉了桶内排序的时间(如给高考考生排序)。
# 计数排序跟桶排序非常类似,只是桶的大小粒度不一样。
# 计数排序只能给非负整数排序,如果要排序的数据是其他类型的,要将其在不改变相对大小的情况下,转化为非负整数。
# 是稳定的原地排序。
# 因为计数排序只涉及扫描遍历操作,所以时间复杂度是O(n)。
1 def countingSort(arr, max_value): 2 """计数排序""" 3 bucket_num = max_value+1 # 桶的数量 4 bucket = bucket_num * [0] # 生成空桶 5 6 for i in range(len(arr)): # 数据入桶 7 bucket[arr[i]] += 1 8 9 sorted_count = 0 # 对所有桶内的数据计数 10 for j in range(bucket_num): # 数据出桶 11 while bucket[j] > 0: # 每个桶内的数据 12 arr[sorted_count] = j 13 sorted_count += 1 14 bucket[j] -= 1 15 return arr 16 17 if __name__ == '__main__': 18 array = [0, 2, 5, 5, 5, 6, 3, 1, 10, 9, 9, 7, 7, 7, 8] 19 sorted_arr = countingSort(array, 10) 20 print(sorted_arr) # [0, 1, 2, 3, 5, 5, 5, 6, 7, 7, 7, 8, 9, 9, 10]
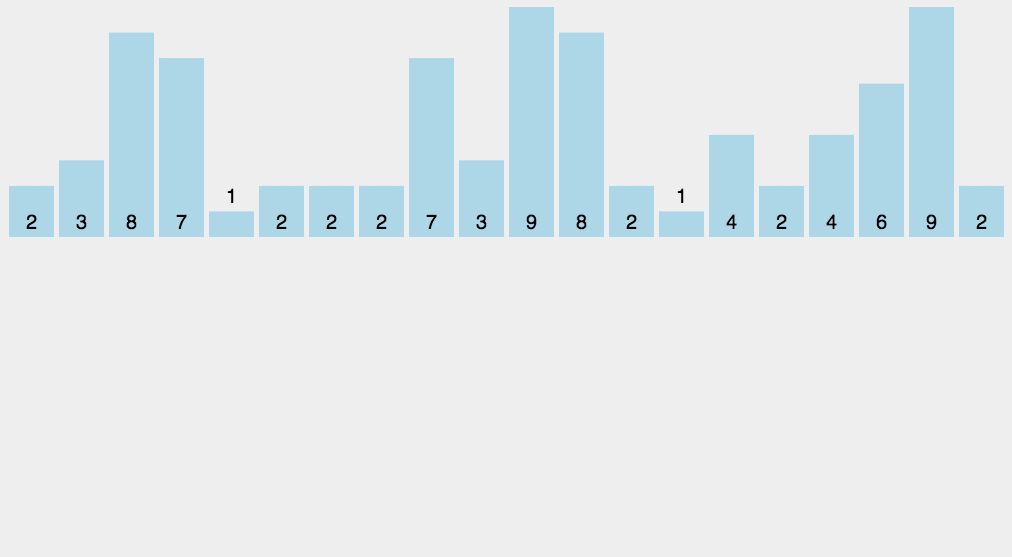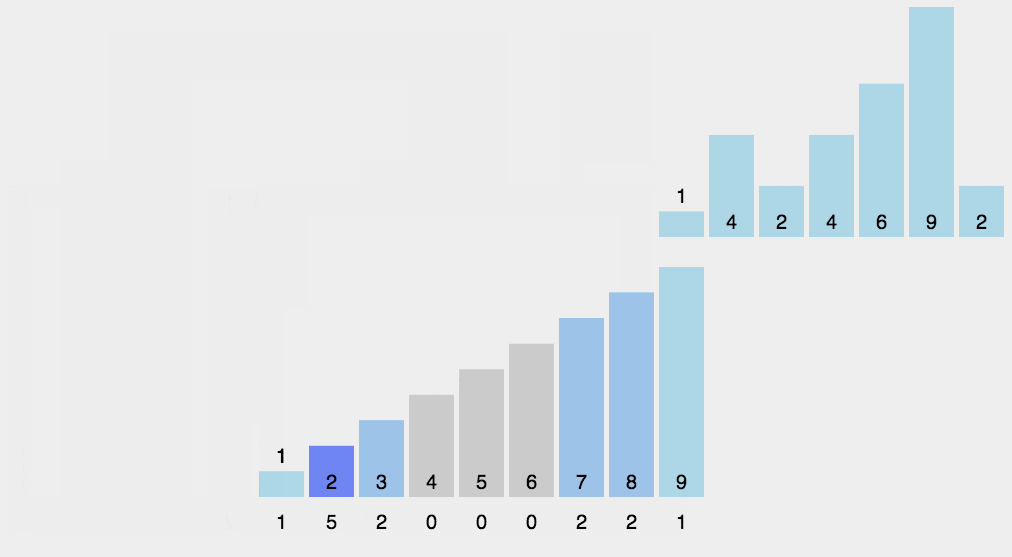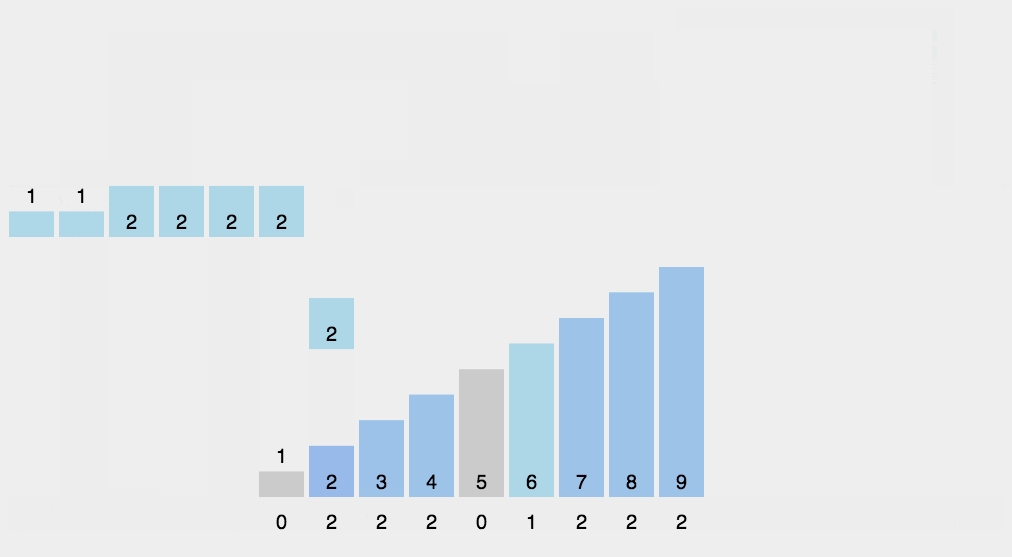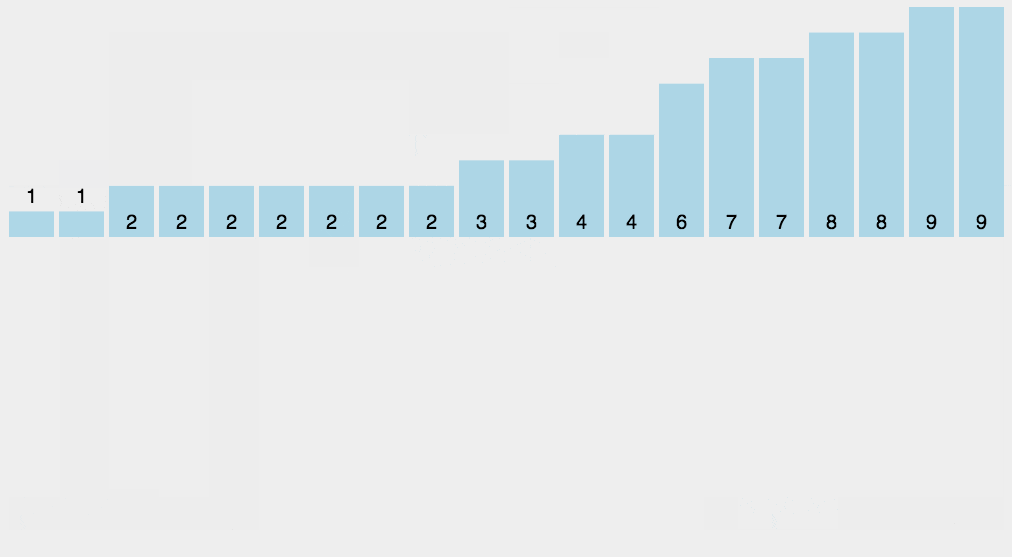
计数排序图片来源:https://www.runoob.com/w3cnote/counting-sort.html