一、理解查准率(precision)& 查全率(recall)
我们在平时常用到的模型评估指标是精度(accuracy)和错误率(error rate),错误率是:分类错误的样本数站样本总数的比例,即E=n/m(如果在m个样本中有n个样本分类错误),那么1-a/m就是精度。除此之外,还会有查准率和查全率,下面举例解释。
按照周志华《机器学习》中的例子,以西瓜问题为例。
错误率:有多少比例的西瓜被判断错误;
查准率(precision):算法挑出来的西瓜中有多少比例是好西瓜;
查全率(recall):所有的好西瓜中有多少比例被算法跳了出来。
继续按照上述前提,对于二分类问题,我们根据真实类别与算法预测类别会有下面四个名词:
在写下面四个名词前,需要给一些关于T(true)、F(false)、P(positive)、N(negative)的解释:P表示算法预测这个样本为1(好西瓜)、N表示算法预测这个样本为0(坏西瓜);T表示算法预测的和真实情况一样,即算法预测正确,F表示算法预测的和真实情况不一样,即算法预测不对。
- TP:正确地标记为正,即算法预测它为好西瓜,这个西瓜真实情况也是好西瓜(双重肯定是肯定);
- FP:错误地标记为正,即算法预测它是好西瓜,但这个西瓜真实情况是坏西瓜;
- FN:错误地标记为负,即算法预测为坏西瓜,(F算法预测的不对)但这个西瓜真实情况是好西瓜(双重否定也是肯定);
- TN:正确地标记为负,即算法标记为坏西瓜,(T算法预测的正确)这个西瓜真实情况是坏西瓜。
所以有:

二、查准率(precision)& 查全率(recall)的关系
- 查准率和查全率是一对矛盾的指标,一般说,当查准率高的时候,查全率一般很低;查全率高时,查准率一般很低。比如:若我们希望选出的西瓜中好瓜尽可能多,即查准率高,则只挑选最优把握的西瓜,算法挑选出来的西瓜(TP+FP)会减少,相对挑选出的西瓜确实是好瓜(TP)也相应减少,但是分母(TP+FP)减少的更快,所以查准率变大;在查全率公式中,分母(所有好瓜的总数)是不会变的,分子(TP)在减小,所以查全率变小。
- 在实际的模型评估中,单用Precision或者Recall来评价模型是不完整的,评价模型时必须用Precision/Recall两个值。这里介绍三种使用方法:平衡点(Break-Even Point,BEP)、F1度量、F1度量的一般化形式。
- BEP是产准率和查全率曲线中查准率=查全率时的取值,如下:

P-R曲线与平衡点
从图中明显看出算法效果:A>B>C
- F1度量的准则是:F1值越大算法性能越好。

- 在一些实际使用中,可能会对查准率或者查全率有偏重,比如:逃犯信息检索系统中,更希望尽量少的漏掉逃犯,此时的查全率比较重要。会有下面F1的一般形式。
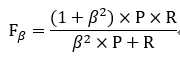
当beta>1时查全率重要,beta<1时查准率重要
参考文献
[1] 周志华 《机器学习》