一个简单的爬虫
#网页状态码
#200 正常
#404 网页找不到
#502 504
import requests
from multiprocessing import Pool
def get(url):
response = requests.get(url)
if response.status_code == 200:
return url, response.content.decode('utf-8')
def call_back(args):
url,content = args #拆包args中传入的参数
print(url,len(content))
if __name__ == '__main__':
url_lst = [
'https://www.cnblogs.com',
'https://www.sogou.com',
'http://www.sohu.com',
'http://www.baidu.com'
]
p = Pool(5)
for url in url_lst:
p.apply_async(get,args=(url,),callback=call_back) #利用callback去用主进程执行Call_back函数中的功能
p.close()
p.join()
爬虫进阶
import re
from urllib.request import urlopen
from multiprocessing import Pool
def get_page(url,pattern):
response=urlopen(url).read().decode('utf-8')
return pattern,response #正则表达式编译结果,网页内容
def parse_page(info):
pattern,page_content=info
res=re.findall(pattern,page_content)
for item in res:
dic={
'index':item[0].strip(),
'title':item[1].strip(),
'actor':item[2].strip(),
'time':item[3].strip(),
}
print(dic)
if __name__ == '__main__':
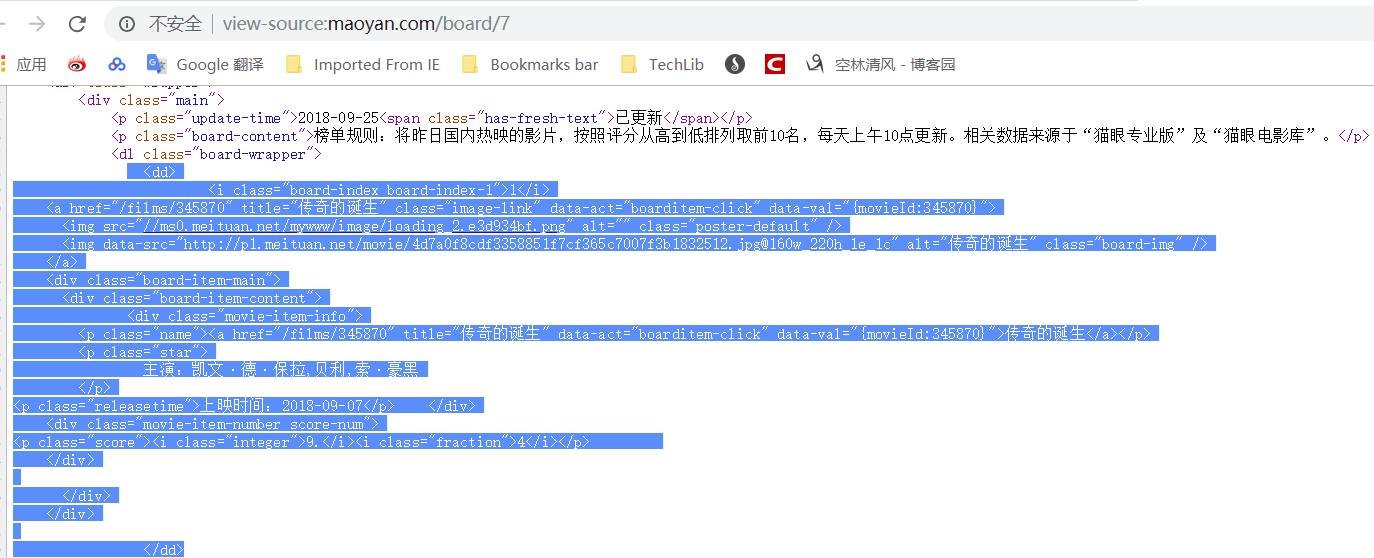
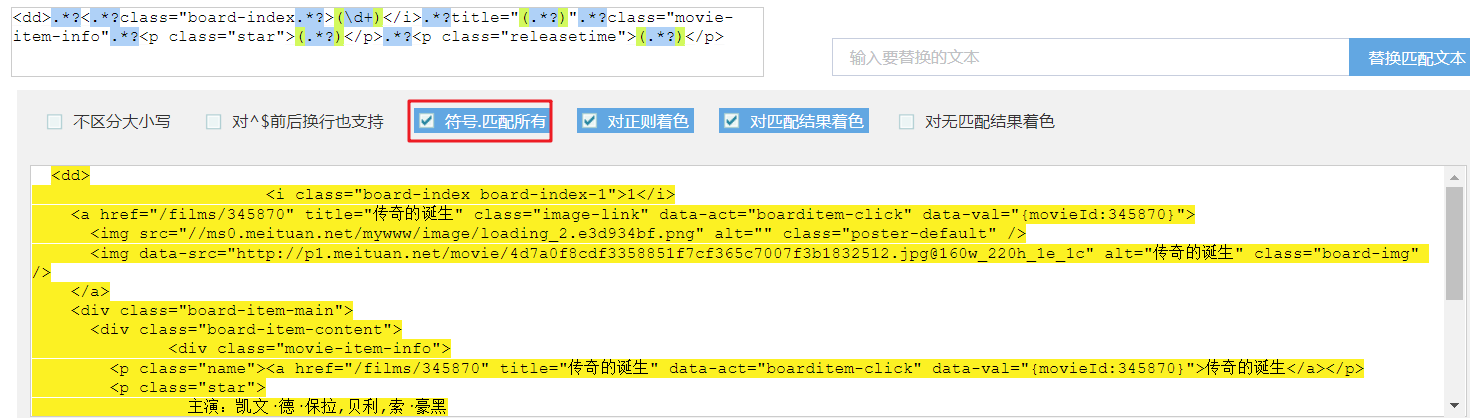
regex = r'<dd>.*?<.*?class="board-index.*?>(d+)</i>.*?title="(.*?)".*?class="movie-item-info".*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>'
pattern1=re.compile(regex,re.S)
url_dic={
'http://maoyan.com/board/7':pattern1,
}
p=Pool()
res_l=[]
for url,pattern in url_dic.items():
res=p.apply_async(get_page,args=(url,pattern),callback=parse_page)
res_l.append(res)
for i in res_l:
i.get()
>>>
{'index': '1', 'title': '传奇的诞生', 'actor': '主演:凯文·德·保拉,贝利,索·豪黑', 'time': '上映时间:2018-09-07'}
{'index': '2', 'title': '大寒', 'actor': '主演:张双兵,鲁园,许薇', 'time': '上映时间:2018-08-14'}
{'index': '3', 'title': '苏丹', 'actor': '主演:萨尔曼·汗,安努舒卡·莎玛,兰迪普·弘达', 'time': '上映时间:2018-08-31'}
{'index': '4', 'title': '爸,我一定行的', 'actor': '主演:郑润奇,郑鹏生,张咏娴', 'time': '上映时间:2018-08-24'}
{'index': '5', 'title': '李宗伟:败者为王', 'actor': '主演:李宗伟,李国煌,杨雁雁', 'time': '上映时间:2018-09-07'}
{'index': '6', 'title': '悲伤逆流成河', 'actor': '主演:赵英博,任敏,辛云来', 'time': '上映时间:2018-09-21'}
{'index': '7', 'title': '碟中谍6:全面瓦解', 'actor': '主演:汤姆·克鲁斯,亨利·卡维尔,文·瑞姆斯', 'time': '上映时间:2018-08-31'}
{'index': '8', 'title': '快把我哥带走', 'actor': '主演:张子枫,彭昱畅,赵今麦', 'time': '上映时间:2018-08-17'}
{'index': '9', 'title': '赛尔号大电影6:圣者无敌', 'actor': '主演:罗玉婷,翟巍,王晓彤', 'time': '上映时间:2017-08-18'}
{'index': '10', 'title': '念念手纪', 'actor': '主演:滨边美波,北村匠海,北川景子', 'time': '上映时间:2018-09-14'}
正则表达式的在线校验网站
http://tool.chinaz.com/regex