ucore lab1 report
这个报告是计算机1班第10组实验报告。
exercise 1: 生成ucore的过程
通过make V=输出的命令研究ucore生成的过程。
下面的命令是make实际执行的命令(23~24行除外)。
1 gcc -Ikern/init/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/init/init.c -o obj/ke
2 gcc -Ikern/libs/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/libs/stdio.c -o obj/k
3 gcc -Ikern/libs/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/libs/readline.c -o ob
4 gcc -Ikern/debug/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/debug/panic.c -o obj
5 gcc -Ikern/debug/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/debug/kdebug.c -o ob
6 gcc -Ikern/debug/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/debug/kmonitor.c -o
7 gcc -Ikern/driver/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/driver/clock.c -o o
8 gcc -Ikern/driver/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/driver/console.c -o
9 gcc -Ikern/driver/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/driver/picirq.c -o
10 gcc -Ikern/driver/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/driver/intr.c -o ob
11 gcc -Ikern/trap/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/trap/trap.c -o obj/ke
12 gcc -Ikern/trap/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/trap/vectors.S -o obj
13 gcc -Ikern/trap/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/trap/trapentry.S -o o
14 gcc -Ikern/mm/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Ikern/debug/ -Ikern/driver/ -Ikern/trap/ -Ikern/mm/ -c kern/mm/pmm.c -o obj/kern/mm
15 gcc -Ilibs/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -c libs/string.c -o obj/libs/string.o
16 gcc -Ilibs/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -c libs/printfmt.c -o obj/libs/printfmt.o
17 ld -m elf_i386 -nostdlib -T tools/kernel.ld -o bin/kernel obj/kern/init/init.o obj/kern/libs/stdio.o obj/kern/libs/readline.o obj/kern/debug/panic.o obj/kern/debug/kdebug.o obj/kern/
18 gcc -Iboot/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Os -nostdinc -c boot/bootasm.S -o obj/boot/bootasm.o
19 gcc -Iboot/ -fno-builtin -fno-PIC -Wall -ggdb -m32 -gstabs -nostdinc -fno-stack-protector -Ilibs/ -Os -nostdinc -c boot/bootmain.c -o obj/boot/bootmain.o
20 gcc -Itools/ -g -Wall -O2 -c tools/sign.c -o obj/sign/tools/sign.o
21 gcc -g -Wall -O2 obj/sign/tools/sign.o -o bin/sign
22 ld -m elf_i386 -nostdlib -N -e start -Ttext 0x7C00 obj/boot/bootasm.o obj/boot/bootmain.o -o obj/bootblock.o
23 'obj/bootblock.out' size: 496 bytes
24 build 512 bytes boot sector: 'bin/bootblock' success!
25 dd if=/dev/zero of=bin/ucore.img count=10000
26 dd if=bin/bootblock of=bin/ucore.img conv=notrunc
27 dd if=bin/kernel of=bin/ucore.img seek=1 conv=notrunc
编译过程
编译ucore和编译应用程序的过程相同,但是:
- 不使用任何外部的库,比如C标准库;
- 不使用动态链接,不生成pic(position-independent code)代码;
- 不查找标准库头文件;
具体参数分析:
- 链接相关
- -no-stdlib: 不链接标准库和C初始化函数
由于ucore是操作系统,不应该使用外部的库,而且应该自己指定程序的入口,所以用这个选项。
- -fno-buitlin: 对于非__buitlin_开头的函数,不使用对应的GCC内置(built in)函数
除了外部的库,GCC内部内嵌的有库libgcc.a,这个库总是自动链接(即使使用了-no-stdlib选项)。大量的标准库函数都有对应的内置版本,比如strcpy,对应有__builtin_strcpy,调用strcpy时GCC实际调用__builtin_strcpy。ucore既需要内置函数实现的C语言特性(比如va_list),又希望自己实现部分标准库函数(比如strcpy),并且在调用时使用自定义版本而非内置版本。
- -no-stdinc: 不搜索系统默认的头文件目录
ucore不使用外部库,只是用libgcc.a和自定义的标准库。如果不开启这个选项,GCC会搜索到系统的标准库头文件,而非自定义的标准库头文件。
- -fno-PIC: 不生成位置无关代码(position-independent code)
GCC默认动态链接,生成pic代码。ucore不进行动态链接,不生成pic代码。
- 调试相关
- -ggdb: 生成GDB专用格式的调试信息
ucore使用GDB调试,生成GDB专用的调试信息可以最大限度的增强GDB的调试能力。
- -gstabs: 生成stabs格式的调试信息
ucore中内置了调试内核的函数,比如联系5完成的print_stackframe()函数,这些函数解析stabs格式的调试信息。
- 目标平台
- -m32: 生成IA-32位代码
ucore是运行在IA-32处理器上的操作系统,所以要用这个选项。
- 代码生成规格
- -fno-stack-protector: 禁用stack-protector
现代GCC编译时会使用stack-protector(在数组末尾添加金丝雀值(哨兵),如果金丝雀值被更改就会终止程序)防止缓冲区溢出。ucore添加这个选项可能是想简化内存布局或者减少运行时的内存消耗。
链接过程
bootloader和kernel都是ucore项目的一部分,但却是两个独立的程序(执行文件),所以分别链接。
ld选项:
- -m: 指定可执行文件格式与目标平台
ucore使用elf_i386格式。
- -nostdlib: 禁止链接标准库和C程序初始函数
ucore是操作系统,不依赖与外部函数库。
- -T: 指定linker script
生成kernel的过程中使用tools/kernel.ld作为linker script,其中包含了设置kernel内部各段的相关信息;生成bootblock的过程中使用tools/boot.ld作为linker scrip,其中包含程序入口点。
- -Ttext: 设置可执行文件的.text节的绝对地址
在生成bootblock的过程中使用了这个选项,使bootloader的.text节起始地址为绝对地址0x7c00。
- -e: 设置可执行文件入口点
在生成bootblock的过程中使用了这个选项,指定start标记为bootloader的入口点。
- -N: 将可执行文件的代码节和数据节设置为读/写、禁止代码节向页大小对齐、禁止动态链接
_
启动扇区的检验和生成
完成了全部的编译链接后,还需要生成启动扇区。使用tools/sign和objdump对目标文件bootblock.o进行修改得到。
在生成了bootblock.o,
- 调用objdump提取了bootblock.o中的代码输出到bootblock.out中;
- 调用tools/sign检查bootblock.out是否小于510字节,如果大于510字节就报错;
- tools/sign将bootblock.out输出到一个bin/bootblock,并将文件最后两个字节设置为0x55,0xAA。
@$(OBJDUMP) -S $(call objfile,bootblock) > $(call asmfile,bootblock)
@$(OBJDUMP) -t $(call objfile,bootblock) | $(SED) '1,/SYMBOL TABLE/d; s/ .* / /; /^$$/d' > $(call symfile,bootblock)
@$(OBJCOPY) -S -O binary $(call objfile,bootblock) $(call outfile,bootblock)
@$(call totarget,sign) $(call outfile,bootblock) $(bootblock)
$(call create_target,bootblock)
通过以上步骤得到的bin/bootblock包含了启动扇区中的全部内容。
虚拟硬盘的制作
通过dd命令制作虚拟硬盘。
先将虚拟硬盘第一个扇区区初始化为0,在把bin/bootblock写入其中制成启动扇区,然后再将bin/kernel写入之后的扇区中。
dd if=/dev/zero of=bin/ucore.img count=10000
dd if=bin/bootblock of=bin/ucore.img conv=notrunc
dd if=bin/kernel of=bin/ucore.img seek=1 conv=notrunc
exercise 2:使用qemu执行并调试lab1中的软件
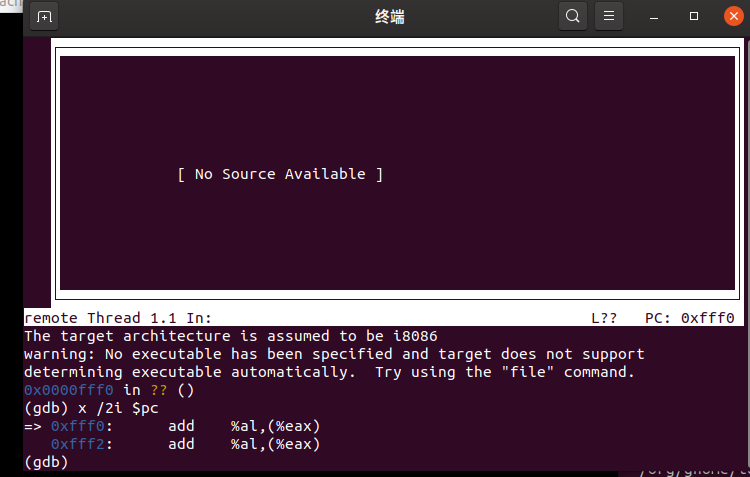
从CPU加电后执行的第一条指令开始,单步跟踪BIOS的执行
修改gdbinit内容为:
set architecture i8086
target remote :1234
在lab1下执行:
make debug
反汇编 :
x /2i $pc
结果如图:
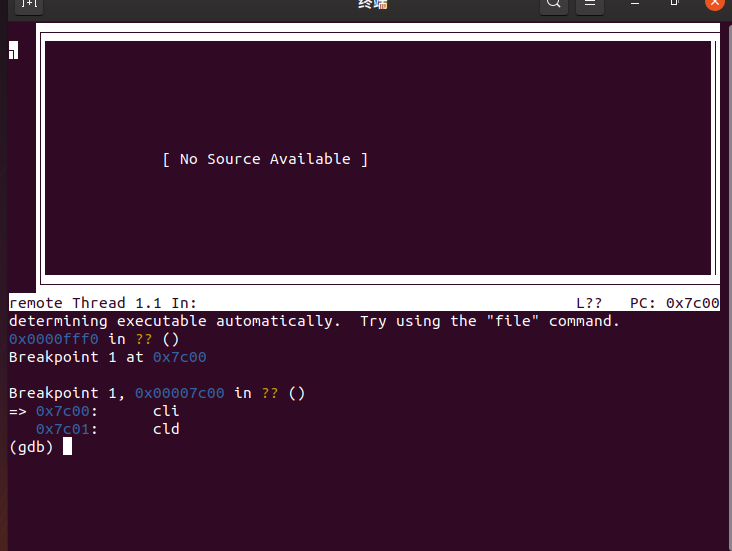
在初始化位置0x7c00设置实地址断点,测试断点
gdbinit文件修改为:
set architecture i8086
target remote :1234
b *0x7c00
c
gdb中执行
x/2i $pc
结果如图
从0x7c00开始跟踪代码运行,将单步跟踪反汇编得到的代码与bootasm.S和 bootblock.asm进行比较
改写makefile文件:
debug: $(UCOREIMG)
$(V)$(TERMINAL) -e "$(QEMU) -S -s -d in_asm -D $(BINDIR)/q.log -parallel stdio -hda $< -serial null"
$(V)sleep 2
$(V)$(TERMINAL) -e "gdb -q -tui -x tools/gdbinit"
执行:
make debug
得到q.log文件

查看bootasm.S文件
查看bootblock.asm文件

查看bootblock.asm文件

从上面结果可以看出bootasm.S文件代码和bootblock.asm是一样的。
找一个bootloader或内核中的代码位置,设置断点并进行测试
在0x7c35设置断点(bootmain函数)。修改gdbinit:
set architecture i8086
target remote :1234
break *0x7c4a
执行make debug,结果如下:
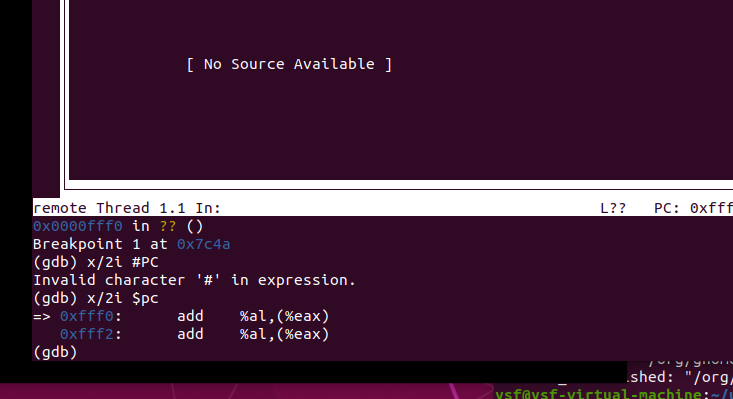
断点正常。
exercise 3: bootloader进入保护模式的过程
练习一要求分析bootloader进入保护模式的过程。bootloader由三个文件实现,分别为asm.h(包含常量,初始值)、bootasm.S(开启A20,设置GDT,并进入保护模式)、bootmain.c(加载kernel并执行)。这个练习仅涉及asm.h和bootasm.S。
bootasm.S完成了A20的开启、GDT的设置、内核栈的设置后进入保护模式,并call到bootmain执行,进行kernel的加载工作。
常量与宏
bootasm.S中定义了三个常量:
.set PROT_MODE_CSEG, 0x8 # kernel code segment selector
.set PROT_MODE_DSEG, 0x10 # kernel data segment selector
.set CR0_PE_ON, 0x1 # protected mode enable flag
CRO_PE_ON作为切换到保护模式时修改CRO的掩码。
PROT_MODE_CSEG和PROT_MODE_DSEG分别作为内核代码段、数据段的选择子,指向GDT[1]和GDT[2],RPL(requested privilege level)均设置为ring 0。
asm.h中定义了描述段描述符的宏。
A20的开启
bootloader最初运行在16位实模式下。
bootloader首先关闭对中断的响应,并将段寄存器ds,es,ss置零,之后开始A20(在8042芯片上)的开启。
开启A20的思路很简单:等到8042芯片空闲时,将A20位设置为1即可。由于8042的设计,向8042写入数据被才分成向0x64端口发送写命令和向0x60端口发送数据两步。
最终操作步骤如下:
- 等待8042芯片空闲
- 向P2端口发送写命令
- 再次等待8042芯片空闲
- 像P2端口写入数据
等待8042芯片空闲
等待8042空闲通过循环读取8042的状态寄存器到CPU寄存器al,判断al是否为0x2(芯片初始系统状态)来实现。
seta20.1:
inb $0x64, %al # read status information into al
testb $0x2, %al
jnz seta20.1
像8042写入数据
向端口0x64发送写命令
movb $0xd1, %al # 0xd1 -> port 0x64
outb %al, $0x64 # 0xd1 means: write data to 8042's P2 port
向端口0x60写入数据
movb $0xdf, %al # 0xdf -> port 0x60
outb %al, $0x60 # 0xdf = 11011111, means set P2's A20 bit(the 1 bit) to 1
经过以上介绍的四步,A20就被开启了,系统可以使用高于1M的线性空间。
设置GDT
GDT被设置为4字节对齐,仅定义了GDT[0]、GDT[1](内核代码段)、GDT[2](内核数据段)。
# Bootstrap GDT
.p2align 2 # force 4 byte alignment
gdt:
SEG_NULLASM # null seg
SEG_ASM(STA_X|STA_R, 0x0, 0xffffffff) # code seg for bootloader and kernel(executable and read-only)
SEG_ASM(STA_W, 0x0, 0xffffffff) # data seg for bootloader and kernel(writable)
gdtdesc:
.word 0x17 # sizeof(gdt) - 1
.long gdt # address gdt
```
其中的的宏定义在asm.h中,asm.h比较短,直接摘抄出来。
```
/* Normal segment */
#define SEG_NULLASM
.word 0, 0;
.byte 0, 0, 0, 0
#define SEG_ASM(type,base,lim)
.word (((lim) >> 12) & 0xffff), ((base) & 0xffff);
.byte (((base) >> 16) & 0xff), (0x90 | (type)),
(0xC0 | (((lim) >> 28) & 0xf)), (((base) >> 24) & 0xff)
/* Application segment type bits */
#define STA_X 0x8 // Executable segment
#define STA_E 0x4 // Expand down (non-executable segments)
#define STA_C 0x4 // Conforming code segment (executable only)
#define STA_W 0x2 // Writeable (non-executable segments)
#define STA_R 0x2 // Readable (executable segments)
#define STA_A 0x1 // Accessed
分析以上两段代码可以发现:
- GDT[0]设置为空,未使用;
- GDT[1],GDT[2]分别作为内核代码段、数据段;
- 内核代码段、数据段都被设置为最长4G,且基地址均为0x00;
内核代码段、数据段被设置成这样是有意削弱(避免)X86分段内存模型的影响,在32位的CPU上实现类似64位上的平坦内存模型,方便页机制的实现。
加载GDT
lgdt gdtdesc
切换到保护模式
开启A20、设置并加载GDT后,bootloader已经完成了切换到保护模式的全部准备工作。
开启保护模式仅需要打开控制寄存器CR0中相应的标志位,通过异或之前定义的掩码CRO_PE_ON实现。
movl %cr0, %eax
orl $CR0_PE_ON, %eax
movl %eax, %cr0
打开模式后,CPU真正进入了32位模式,默认使用分段内存模型,段寄存器中必须存放相应的选择子。
首先设置cs和 eip的值,通过ljmp实现。ljmp仅仅是跳转到了下一条指令(procseg处)
# Jump to next instruction, but in 32-bit code segment.
# Switches processor into 32-bit mode.
ljmp $PROT_MODE_CSEG, $protcseg
.code32
procseg:
设置栈并跳转到bootmain加载kernel
将所有的寄存器设置为PROT_MODE_DSEG(指向内核数据段)。将栈设置为为0x00~0x7c00(bootloader之下都是栈的空间),然后使用call指令执行bootmain,开始加载kernel。
bootmain函数正常情况不会返回,如果返回肯定是bootloader产生错误,进入死循环。
.code32 # Assemble for 32-bit mode
protcseg:
# Set up the protected-mode data segment registers
movw $PROT_MODE_DSEG, %ax # Our data segment selector
movw %ax, %ds # -> DS: Data Segment
movw %ax, %es # -> ES: Extra Segment
movw %ax, %fs # -> FS
movw %ax, %gs # -> GS
movw %ax, %ss # -> SS: Stack Segment
# Set up the stack pointer and call into C. The stack region is from 0--start(0x7c00)
movl $0x0, %ebp
movl $start, %esp
call bootmain
# bootmain should not return. if return, loop forever
spin:
jmp spin
栈和bootloader的位置关系如下:
+--------------------+
+ +
+ +
+ +
+ +
+ not in use +
+ +
+ +
+ +
+ +
+ +
+--------------------+
+ +
+ +
+ +
+ bootloader +
+ +
+ +
+ +
+ +
+--------------------+ <-- 0x7c00 beginning of bootloader
+ | +
+ | +
+ stack | +
+ | +
+ | +
+ V +
+--------------------+ <-- 0x00
至此,bootlader完成了初始化和各种设置,bootasm.S完成任务,剩下的任务交给bootmain函数完成。
execrise 4: bootloader加载ELF格式的OS的过程
在bootmain函数中,bootloader加载kernel到内存中。
先分析bootmain函数如何加载ELF格式的kernel,再分析具体读取磁盘的机制。
加载ELF格式的kernel
为了理解如何加载ELF格式的kernel,就必须知道ELF格式的结构。在这里只涉及到了ELF32格式中的已链接的可执行文件,所以忽略共享目标文件和可重定位目标文件。
实验手册给的资料不足,参考《深入理解计算机系统》第三版第7章《链接》图7-13“典型的ELF可执行目标文件”

图中ELF头和段头部对应的ucore中的数据类型为struct elfhdr和struct proghdr,均定义在libs/elf.h中。这里只摘抄在这里用到的结构体成员。
#define ELF_MAGIC 0x464C457FU // "x7FELF" in little endian
struct elfhdr {
...
uint32_t e_magic; // must equal ELF_MAGIC
...
uint32_t e_entry; // entry point of executable
...
uint16_t e_phnum; // number of entries in program header or 0
...
}
struct proghdr {
...
uint32_t p_offset; // file offset of segment
uint32_t p_va; // virtual address to map segment
...
uint32_t p_memsz; // size of segment in memory (bigger if contains bss)
...
}
知道这些信息后,加载ELF格式的kernel的机制就很清楚了:
- 通过判断ELF_MAGIC是否等于ELF头中的e_magic确定kernel是否是合法的ELF32格式
- 段头部表是struct proghdr的数组,数组元素个数为e_phnum(在ELF头中)
- 内核各段应该加载到对应段头部中记录的p_va处,大小为p_memsz,位于于kernel文件的p_offset处。通过readseg实现。
bootmain逻辑流:
- 读取kernel的ELF头和段头部表加载到ELFHDR(0x10000)处
- 判断kerne是否是合法的ELF格式,如果不是则死循环
- 如果格式合法就根据kernel中的ELF头和段头部表中的信息将kernel各段加载到适当的位置
- 加载完成后,通过函数调用跳转到entry point
具体实现代码如下:
uintptr_t其实就是uint32_t代表32位地址,定义在lib/defs.h中。
/* bootmain - the entry of bootloader */
void
bootmain(void) {
// read the 1st page off disk
/** read SECTSIZE*8 bytes at offset 0 from kernel into virtual address ELFHDR(0x10000) **/
readseg((uintptr_t)ELFHDR, SECTSIZE * 8, 0);
/* if the executable is not ELF, goto bad(infinite loop) */
if (ELFHDR->e_magic != ELF_MAGIC) {
goto bad;
}
struct proghdr *ph, *eph;
// load each program segment (ignores ph flags)
ph = (struct proghdr *)((uintptr_t)ELFHDR + ELFHDR->e_phoff);
/* eph is the position after the end of the last program header */
eph = ph + ELFHDR->e_phnum;
for (; ph < eph; ph ++) {
/** load executable code from kernel into corresponding virtual address according to infomation in program header **/
readseg(ph->p_va & 0xFFFFFF, ph->p_memsz, ph->p_offset);
}
// call the entry point from the ELF header
// note: does not return
/* use function call to transfer control to kernel */
((void (*)(void))(ELFHDR->e_entry & 0xFFFFFF))();
bad:
outw(0x8A00, 0x8A00);
outw(0x8A00, 0x8E00);
/* do nothing */
while (1);
}
ELF格式中记录的地址是链接时设置的,这些地址是虚拟地址,在启动虚拟内存系统之前,ucore设置了虚拟地址与物理地址之间的临时映射,关系为:
virtual address = physical address + 0xC0000000
按位与掩码0xFFFFFF获取链接地址对应的物理地址。
读取硬盘的机制
ucore为了简化硬盘访问的实现,使用的是可编程IO(programed IO)方式,并且假设硬盘使用IDE。一个IDE通道可以接两个硬盘(主盘/从盘),ucore只读取主盘的数据。
基本思路:
- 等待硬盘空闲
- 发送要读取的扇区号为硬盘
- 等待硬盘空闲
- 读取扇区数据到某个内存位置
ucore通过readsg()、readsec()和insl()三个函数实现读取硬盘。readsg()和readsec()定义在bootmain.c中,insl()定义在libs/x86.h头文件中。
/* 从读取扇区号secno的数据到内存dst处 */
static void
readsect(void *dst, uint32_t secno);
/* 从kernel文件偏移offset处读取count字节到内存va处 */
static void
readseg(uintptr_t va, uint32_t count, uint32_t offset);
/* 内联汇编。从prot端口读取cnt*4字节数据到内存addr处 */
static inline
void insl(uint32_t port, void *addr, int cnt) __attribute__((always_inline));
函数调用关系: readsg() --> readsec() --> insl()
insl()实现:
*/当%ecx(cnt)不为0使,从端口%edi(port)处读取4字节到(%edi)(内存addr)处*/
static inline void
insl(uint32_t port, void *addr, int cnt) {
/* edi - addr
ecx - cnt
edi - port
*/
asm volatile (
"cld;"
"repne; insl;"
: "=D" (addr), "=c" (cnt)
: "d" (port), "0" (addr), "1" (cnt)
: "memory", "cc");
}
insl()函数是一个辅助函数,在读取之前还需要像硬盘发送读命令,读取硬盘扇区由readsect()完成。
磁盘IO地址与功能(摘自ucore实验手册)如下:
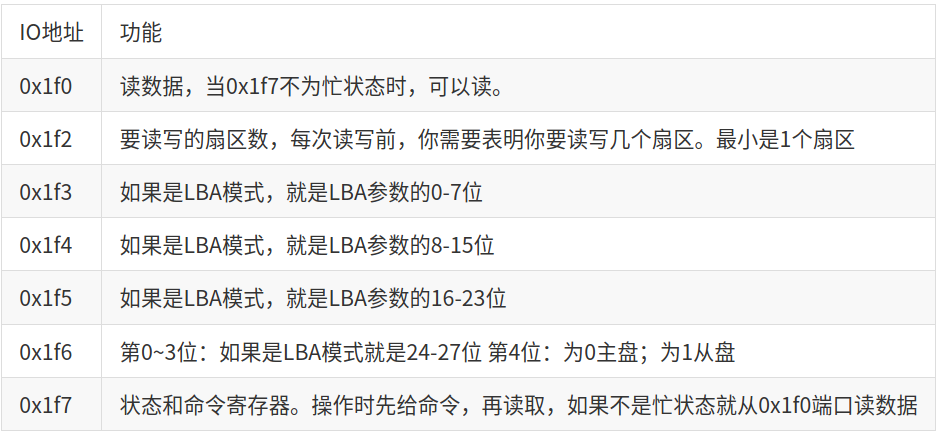
static void
readsect(void *dst, uint32_t secno) {
// wait for disk to be ready
waitdisk();
outb(0x1F2, 1); // count = 1
outb(0x1F3, secno & 0xFF);
outb(0x1F4, (secno >> 8) & 0xFF);
outb(0x1F5, (secno >> 16) & 0xFF);
outb(0x1F6, ((secno >> 24) & 0xF) | 0xE0); /* 掩码0xF将扇区号28~31位置零,仅保留24~27位。
异或0xE0避开了IO端口第4位,目的是读取主盘。*/
outb(0x1F7, 0x20); // cmd 0x20 - read sectors
// wait for disk to be ready
waitdisk();
// read a sector
insl(0x1F0, dst, SECTSIZE / 4); /*SECTISE被定义为512。insl每次读取4字节,所以SECTISE要除4
}
最终bootmain读取磁盘使用的是readseg()函数。
static void
readseg(uintptr_t va, uint32_t count, uint32_t offset) {
/* uintptr_t在/libs/defs.h中定义为uint32_t;
uintprt_t避免了C语言指针运算时的自动伸展;
*/
uintptr_t end_va = va + count;
// round down to sector boundary
va -= offset % SECTSIZE;
// translate from bytes to sectors; kernel starts at sector 1
uint32_t secno = (offset / SECTSIZE) + 1;
// If this is too slow, we could read lots of sectors at a time.
// We'd write more to memory than asked, but it doesn't matter --
// we load in increasing order.
for (; va < end_va; va += SECTSIZE, secno ++) {
readsect((void *)va, secno);
}
}
readseg()函数提供的功能是从磁盘读取count字节数据,但是读取硬盘却以512字节的扇区为为单位,所以实际读入的字节数很可能大于要求读入的字节数。
readseg()函数实际写入的内存地址是地址参数向下舍入到512字节的边界,所以实际写入的内存地址很可能低于要求写入的内存地址。
execrise 5:完成函数调用跟踪函数
这个练习要求我们kern/debug/kdebug.c中的print_stackframe()函数。在print——stackframe()函数中,注释已经给出了完整的步骤,难度不大,只要理解x86函数调用过程就可以做出来。
栈的设置是在启动阶段(跳转到bootmain函数之前完成的),所以初始时栈结构如下:
+--------------------+ <-- 0x7c00
+ bootmain frame + |g
+--------------------+ |r
+ + |o
+ + |w
+ + V
+ +
+ +
+--------------------+ <-- 0x00
bootmain函数是不会返回的,所有的函数栈帧都在bootmain函数下面。在调用bootmain()之前,%ebp被设置了0,这个值被压入了函数栈中,这个特殊的%ebp是跟踪函数栈帧的结束标志。
x86函数调用的具体过程(同特权级):
- 把函数参数压入栈中
- 把函数返回地址(%es,%eip)压入栈中
- 把旧的%ebp压入栈中,并把%ebp的值改为当前%esp
跟踪函数堆栈就是利用了x86函数调用后堆栈的结构。
/* stack */
high address
+ %cs +
+ %eip +
+--------------------+<----------------------------------------------+
+ ... + local variables of calling function +
+--------------------+ +
+ parameters + parameters passed by calling function +
+--------------------+ <-----+ +
+ %cs + + +
+--------------------+ +---- return address +
+ %eip + + +
+--------------------+ <-----+ +
+ old %ebp +-----------------------------------------------+
+--------------------+<----------------------------------------------+
+ ... + local variables of calling function +
+--------------------+ +
+ parameters + parameters passed by calling function +
+--------------------+ <-----+ +
+ %cs + + +
+--------------------+ +---- return address +
+ %eip + + +
+--------------------+ <-----+ +
+ old %ebp +-----------------------------------------------+
+--------------------+ <----- current %ebp
+ ... +
+ +
low address
在上面的图示是某时刻堆栈的布局。
每次函数调用,%ebp都被压入栈中,并修改为当时栈顶指针%esp的值。栈中保存的%ebp总是指向上一次保存的%ebp处,而且栈中保存的%ebp上面4字节处就是调用函数的返回地址,返回地址之上就是被调用函数的参数。
利用当前的%ebp值和栈中保存的%ebp值就可以实现跟踪堆栈的功能。
print_stackframe(void)函数要求了实现的具体步骤,所以最终补全的代码跟答案结构是完全一样的,这里直接给出了去掉步骤要求的答案代码。
void
print_stackframe(void) {
uint32_t ebp = read_ebp(), eip = read_eip();
int i, j;
for (i = 0; ebp != 0 && i < STACKFRAME_DEPTH; i ++) {
cprintf("ebp:0x%08x eip:0x%08x args:", ebp, eip);
uint32_t *args = (uint32_t *)ebp + 2;
for (j = 0; j < 4; j ++) {
cprintf("0x%08x ", args[j]);
}
cprintf("
");
print_debuginfo(eip - 1);
eip = ((uint32_t *)ebp)[1];
ebp = ((uint32_t *)ebp)[0];
}
}
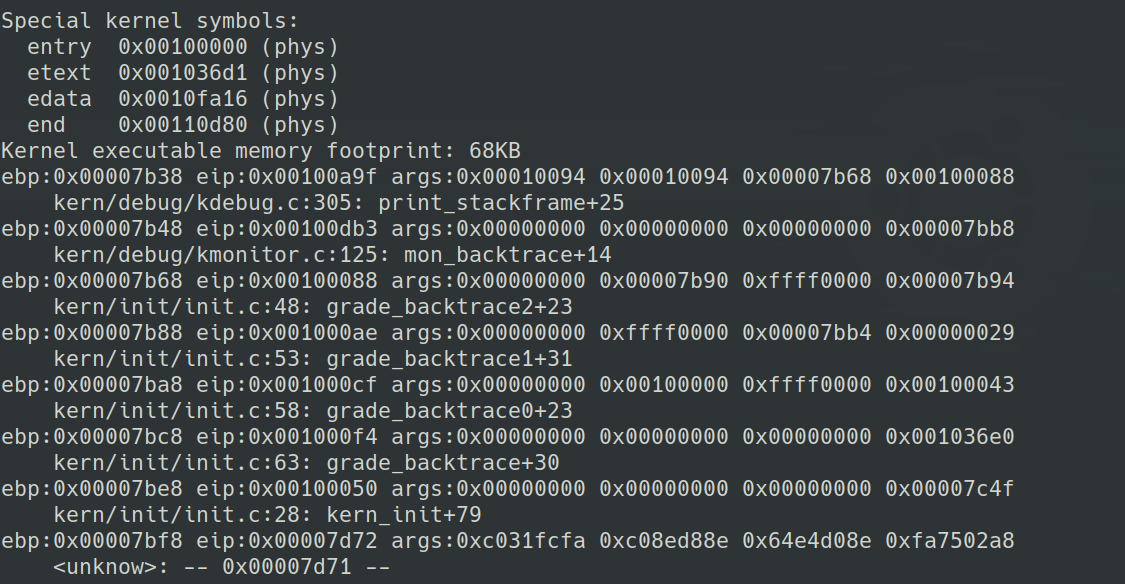
在print_stackframe中对调试信息的解析和显示由print_debuginfo()函数完成。这个函数接受一个代码段中地址,并显示相应的调试信息。
这个函数似乎有bug,只要把print_stackframe()函数的实现稍作改变,%eip的值偏移几个字节,就会无法正确分析出代码在kdebug.c文件中的位置,其他栈帧中函数所在文件似乎不受影响。
execrise 6:完善中断初始化和处理
发生中断后,x86根据终端去IDT中查找相应的描述符,并跳转到描述符指向的中断处理例程执行。
进行中断初始化和处理,就相当于设置IDT中的描述符和描述符指向的中断处理例程。
IDT描述符结构(摘自intel开发手册)如下:
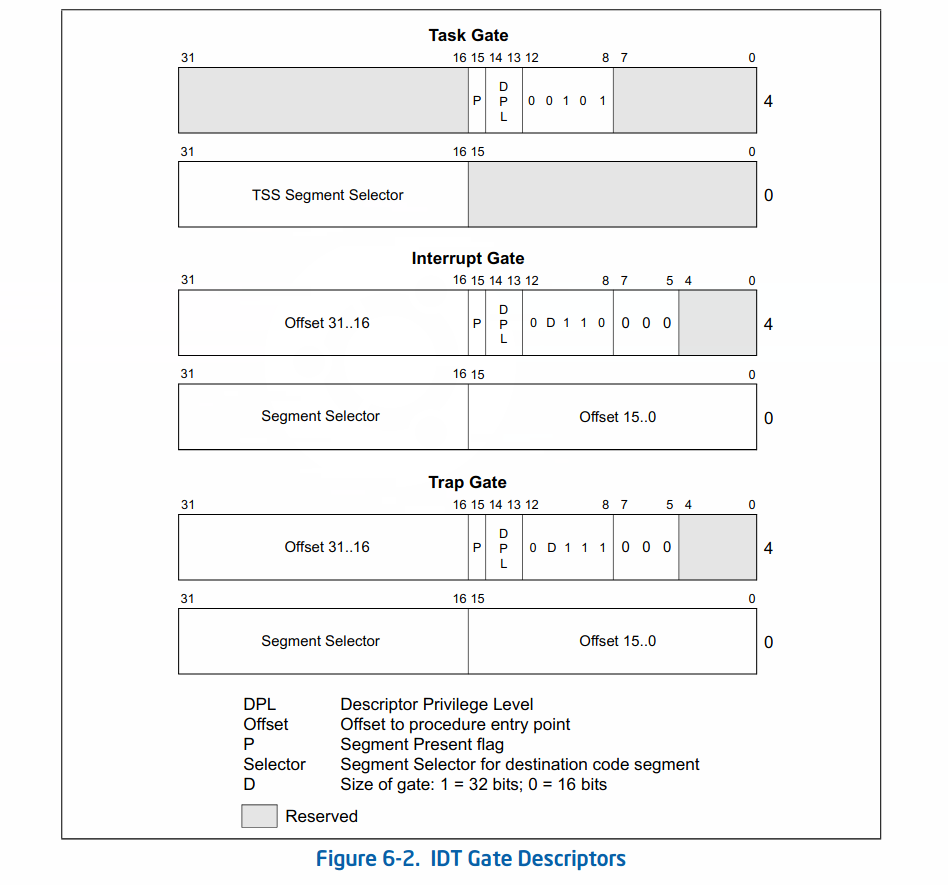
IDT表项占8个字节,其中031位、4763位代表中断处理例程的入口。
中断的设置
在kern/trap/vector.S中设置了256个中断处理例程,并定义了一个指向函数的指针数组__vector。利用kern/mm/mmu.h中定义的SET_GATE函数宏就可以轻易的设置好IDT。
与初始化IDT相关的结构和宏如下:
/*
* Set up a normal interrupt/trap gate descriptor
* - istrap: 1 for a trap (= exception) gate, 0 for an interrupt gate
* - sel: Code segment selector for interrupt/trap handler
* - off: Offset in code segment for interrupt/trap handler
* - dpl: Descriptor Privilege Level - the privilege level required
* for software to invoke this interrupt/trap gate explicitly
* using an int instruction.
*/
/** defined in kern/mm/mmu.h **/
#define SETGATE(gate, istrap, sel, off, dpl) {
(gate).gd_off_15_0 = (uint32_t)(off) & 0xffff;
(gate).gd_ss = (sel);
(gate).gd_args = 0;
(gate).gd_rsv1 = 0;
(gate).gd_type = (istrap) ? STS_TG32 : STS_IG32;
(gate).gd_s = 0;
(gate).gd_dpl = (dpl);
(gate).gd_p = 1;
(gate).gd_off_31_16 = (uint32_t)(off) >> 16;
}
/** defined in kern/mm/memlayout.h **/
#define SEG_KTEXT 1
#define GD_KTEXT ((SEG_KTEXT) << 3) // kernel text
#define DPL_KERNEL (0)
#define DPL_KERNEL (0)
#define USER_CS ((GD_UTEXT) | DPL_USER)
#define KERNEL_CS ((GD_KTEXT) | DPL_KERNEL)
/** defined in kern/mm/mmu.h **/
/* Gate descriptors for interrupts and traps */
struct gatedesc {
unsigned gd_off_15_0 : 16; // low 16 bits of offset in segment
unsigned gd_ss : 16; // segment selector
unsigned gd_args : 5; // # args, 0 for interrupt/trap gates
unsigned gd_rsv1 : 3; // reserved(should be zero I guess)
unsigned gd_type : 4; // type(STS_{TG,IG32,TG32})
unsigned gd_s : 1; // must be 0 (system)
unsigned gd_dpl : 2; // descriptor(meaning new) privilege level
unsigned gd_p : 1; // Present
unsigned gd_off_31_16 : 16; // high bits of offset in segment
};
/** defined in kern/trap/trap.c **/
static struct gatedesc idt[256] = {{0}};
/** defined in kern/trap/trap.h **/
#define T_SYSCALL 0x80 // SYSCALL, ONLY FOR THIS PROJ
/** defined in libs/x86.h **/
/* Pseudo-descriptors used for LGDT, LLDT(not used) and LIDT instructions. */
struct pseudodesc {
uint16_t pd_lim; // Limit
uint32_t pd_base; // Base address
} __attribute__ ((packed));
设置IDT在/kern/trap/trap.c中的idt_init函数中完成:
void idt_init()
{
int intrno = 0;
/* ucore don't use task gate.*/
for(; intrno < 256; intrno++)
SETGATE(idt[intrno], 0, KERNEL_CS, __vectors[intrno], DPL_KERNEL);
SETGATE(idt[T_SYSCALL], 1, KERNEL_CS, __vectors[T_SYSCALL], DPL_USER);
ldt(&ldt_pd);
}
因为程序在调用中断处理例程时,必须要满足CPL<=中断处理例程的DPL,把系统调用DPL设置为用户态保证了用户可以通过int指令使用系统调用,把其他中断处理例程DPL设置为内核态确保了用户态程序无法通过int指令调用中断例程。
中断的处理
中断处理过程的调用链如下:
发生中断N --> __vectors[N] --> __alltraps --> trap --> trap_dispatch
IDT中设置中断处理程序仅仅是将中断错误码/0和中断号压入栈中,然后跳转到__alltraps将其他寄存器压栈,之后调用trap(trap_dispatch的包装函数)将指向栈帧的指针传递给trap_dispatch,trap_dispatch根据栈帧中保存的中断号对相应中断进行处理。
__vectors[N]
- 对于有错误码的中断,压入中断号(错误码由处理器压入),跳转到__alltraps。
- 对于无错误码的中断,压入0和中断号,跳转到__alltraps。
__vectors[N]的这种处理方式同一了带错误码的中断和不带中断码的终端的堆栈布局,为统一两种终端的处理过程提供了可能。
/** interrupt without error code **/
vector1:
pushl $0
pushl $1
jmp __alltraps
/** interrupt with error code **/
.globl vector8
vector8:
pushl $8
jmp __alltraps
__alltraps
_alltraps对堆栈的布局进行进一步处理:
- 中断发生时,将所有段寄存器、通用寄存器压入栈中。
- 中断处理完成后将传递给trap的指针出栈。
ucore使用struct trapframe描述堆栈的结构,定义如下:
/* registers as pushed by pushal */
struct pushregs {
uint32_t reg_edi;
uint32_t reg_esi;
uint32_t reg_ebp;
uint32_t reg_oesp; /* Useless */
uint32_t reg_ebx;
uint32_t reg_edx;
uint32_t reg_ecx;
uint32_t reg_eax;
};
struct trapframe {
struct pushregs tf_regs;
uint16_t tf_gs;
uint16_t tf_padding0;
uint16_t tf_fs;
uint16_t tf_padding1;
uint16_t tf_es;
uint16_t tf_padding2;
uint16_t tf_ds;
uint16_t tf_padding3;
uint32_t tf_trapno;
/* below here defined by x86 hardware */
uint32_t tf_err;
uintptr_t tf_eip;
uint16_t tf_cs;
uint16_t tf_padding4;
uint32_t tf_eflags;
/* below here only when crossing rings, such as from user to kernel */
uintptr_t tf_esp;
uint16_t tf_ss;
uint16_t tf_padding5;
} __attribute__((packed)); /* disable align */
因为C语言中的结构体在内存中时连续存储的,从低地址向高地址增长,代码块中的结构体没有进行内存对齐,所以代码中的结构体就可以看成是栈帧。
在reg_edi上方(更低地址)因为调用trap而压入了指向trapframe的%sp指针,这个指针在中断处理完成后由__alltraps出栈。
trap和trap_dispatch
trap作为trap_dispatch的包装函数,功能仅仅是将指向栈帧的指针传递给trap_dispatch,trap_dispatch完成具体处理过程。
trap定义如下:
void
trap(struct trapframe *tf) {
// dispatch based on what type of trap occurred
trap_dispatch(tf);
}
trap_distrap接收到指向栈帧的指针后,使用switch语句根据栈帧中保存的中断号对中断进行针对性的处理。在ucore lab1中,trap_dispatch的的功能还很简单,只有对少数几种硬件中断的处理能力。
我的时钟中断处理过程实现如下:
case IRQ_OFFSET + IRQ_TIMER:
ticks = (ticks + 1) % 100;
if (ticks == 0)
print_ticks();
break;
执行结果:

拓展练习1
ucore的内核代码段在boot/bootmain.c中被设置为可执行、可读、非一致的,只有当CPL等于代码段DPL且RPL小于等于RPL时才能够成功访问,所以不能够通过直接修改CS的特权位实现特权级的切换。数据段也存在类似问题。
可行的方法是通过额外设置与内核代码段指向相同、DPL不同的用户态代码段,与内核数据段指向相同、DPL不同的用户态数据段来实现特权级切换。
当从用户态切换到内核态时,程序的段寄存器指向对应的内核态段,偏移地址不变;当从内核态切换到用户态时,程序的段寄存器指向对应的应用态段,偏移地址不变。
特权级切换时会发生堆栈切换,还必须设置好ring 3和ring 0的堆栈并记录在TSS中。幸运的是,ucore在初始化过程中已经替我们完成了这些工作。
具体的设置在kern/mm/pmm.c中完成:
static struct taskstate ts = {0};
/*
* Global Descriptor Table:
*
* The kernel and user segments are identical (except for the DPL). To load
* the %ss register, the CPL must equal the DPL. Thus, we must duplicate the
* segments for the user and the kernel. Defined as follows:
* - 0x0 : unused (always faults -- for trapping NULL far pointers)
* - 0x8 : kernel code segment
* - 0x10: kernel data segment
* - 0x18: user code segment
* - 0x20: user data segment
* - 0x28: defined for tss, initialized in gdt_init
*/
static struct segdesc gdt[] = {
SEG_NULL,
[SEG_KTEXT] = SEG(STA_X | STA_R, 0x0, 0xFFFFFFFF, DPL_KERNEL),
[SEG_KDATA] = SEG(STA_W, 0x0, 0xFFFFFFFF, DPL_KERNEL),
[SEG_UTEXT] = SEG(STA_X | STA_R, 0x0, 0xFFFFFFFF, DPL_USER),
[SEG_UDATA] = SEG(STA_W, 0x0, 0xFFFFFFFF, DPL_USER),
[SEG_TSS] = SEG_NULL,
};
代表选择子和特权级的常量定义在kern/mm/memlayout.h中:
/* global segment number */
#define SEG_KTEXT 1
#define SEG_KDATA 2
#define SEG_UTEXT 3
#define SEG_UDATA 4
#define SEG_TSS 5
/* global descriptor numbers */
#define GD_KTEXT ((SEG_KTEXT) << 3) // kernel text
#define GD_KDATA ((SEG_KDATA) << 3) // kernel data
#define GD_UTEXT ((SEG_UTEXT) << 3) // user text
#define GD_UDATA ((SEG_UDATA) << 3) // user data
#define GD_TSS ((SEG_TSS) << 3) // task segment selector
#define DPL_KERNEL (0)
#define DPL_USER (3)
#define KERNEL_CS ((GD_KTEXT) | DPL_KERNEL)
#define KERNEL_DS ((GD_KDATA) | DPL_KERNEL)
#define USER_CS ((GD_UTEXT) | DPL_USER)
#define USER_DS ((GD_UDATA) | DPL_USER)
为了使用中断,还应该修改T_SWITCH_TOK和T_SWITCH_TOU两个中断的中断门DPL,idt_init修改如下:
void
idt_init(void) {
int intrno = 0;
/* ucore don't use task gate.*/
for(; intrno < 256; intrno++)
SETGATE(idt[intrno], 0, KERNEL_CS, __vectors[intrno], DPL_KERNEL);
SETGATE(idt[T_SYSCALL], 1, KERNEL_CS, __vectors[T_SYSCALL], DPL_USER);
SETGATE(idt[T_SWITCH_TOK], 0, KERNEL_CS, __vectors[T_SWITCH_TOK], DPL_USER);
SETGATE(idt[T_SWITCH_TOU], 0, KERNEL_CS, __vectors[T_SWITCH_TOU], DPL_KERNEL);
lidt(&idt_pd);
}
练习6理清了中断处理的完整流程,中断发生时会有大量的寄存器被保存到栈上,在执行IRET指令时恢复保存的寄存器。特权级的切换就利用了这个原理,在中断处理过程中篡改相应的寄存器,欺骗IRET指令将这些值保存到寄存器中。
IRET的执行过程伪代码如下:
PROTECTED-MODE:
IF NT = 1
THEN GOTO TASK-RETURN; (* PE = 1, VM = 0, NT = 1 *)
FI;
IF OperandSize = 32
THEN
EIP ← Pop();
CS ← Pop(); (* 32-bit pop, high-order 16 bits discarded *)
tempEFLAGS ← Pop();
ELSE (* OperandSize = 16 *)
EIP ← Pop(); (* 16-bit pop; clear upper bits *)
CS ← Pop(); (* 16-bit pop *)
tempEFLAGS ← Pop(); (* 16-bit pop; clear upper bits *)
FI;
IF tempEFLAGS(VM) = 1 and CPL = 0
THEN GOTO RETURN-TO-VIRTUAL-8086-MODE;
ELSE GOTO PROTECTED-MODE-RETURN;
FI;
PROTECTED-MODE-RETURN: (* PE = 1 *)
IF CS(RPL) > CPL
THEN GOTO RETURN-TO-OUTER-PRIVILEGE-LEVEL;
ELSE GOTO RETURN-TO-SAME-PRIVILEGE-LEVEL; FI;
END;
RETURN-TO-OUTER-PRIVILEGE-LEVEL:
IF OperandSize = 32
THEN
ESP ← Pop();
SS ← Pop(); (* 32-bit pop, high-order 16 bits discarded *)
ELSE IF OperandSize = 16
THEN
ESP ← Pop(); (* 16-bit pop; clear upper bits *)
SS ← Pop(); (* 16-bit pop *)
ELSE (* OperandSize = 64 *)
RSP ← Pop();
SS ← Pop(); (* 64-bit pop, high-order 48 bits discarded *)
FI;
IF new mode = 64-Bit Mode
THEN
IF EIP is not within CS limit
THEN #GP(0); FI;
ELSE (* new mode = 64-bit mode *)
IF RIP is non-canonical
THEN #GP(0); FI;
FI;
EFLAGS (CF, PF, AF, ZF, SF, TF, DF, OF, NT) ← tempEFLAGS;
IF OperandSize = 32 or or OperandSize = 64
THEN EFLAGS(RF, AC, ID) ← tempEFLAGS; FI;
IF CPL ≤ IOPL
THEN EFLAGS(IF) ← tempEFLAGS; FI;
IF CPL = 0
THEN
EFLAGS(IOPL) ← tempEFLAGS;
IF OperandSize = 32 or OperandSize = 64
THEN EFLAGS(VIF, VIP) ← tempEFLAGS; FI;
FI;
CPL ← CS(RPL);
FOR each SegReg in (ES, FS, GS, and DS)
DO
tempDesc ← descriptor cache for SegReg (* hidden part of segment register *)
IF (SegmentSelector == NULL) OR (tempDesc(DPL) < CPL AND tempDesc(Type) is (data or non-conforming code)))
THEN (* Segment register invalid *)
SegmentSelector ← 0; (*Segment selector becomes null*)
FI;
OD;
END;
RETURN-TO-SAME-PRIVILEGE-LEVEL: (* PE = 1, RPL = CPL *)
IF new mode ≠ 64-Bit Mode
THEN
IF EIP is not within CS limit
THEN #GP(0); FI;
ELSE (* new mode = 64-bit mode *)
IF RIP is non-canonical
THEN #GP(0); FI;
FI;
EFLAGS (CF, PF, AF, ZF, SF, TF, DF, OF, NT) ← tempEFLAGS;
IF OperandSize = 32 or OperandSize = 64
THEN EFLAGS(RF, AC, ID) ← tempEFLAGS; FI;
IF CPL ≤ IOPL
THEN EFLAGS(IF) ← tempEFLAGS; FI;
IF CPL = 0
THEN
EFLAGS(IOPL) ← tempEFLAGS;
IF OperandSize = 32 or OperandSize = 64
THEN EFLAGS(VIF, VIP) ← tempEFLAGS; FI;
FI;
END;
其中弹出错误码是程序员手动完成的,在kern/trap/trapentry.S中的__trapret中已经完成了错误码和堆栈上所有寄存器值的出栈。所以我们只需要关注硬件自动检查的堆栈结构。
X86中断发生时的堆栈结构:
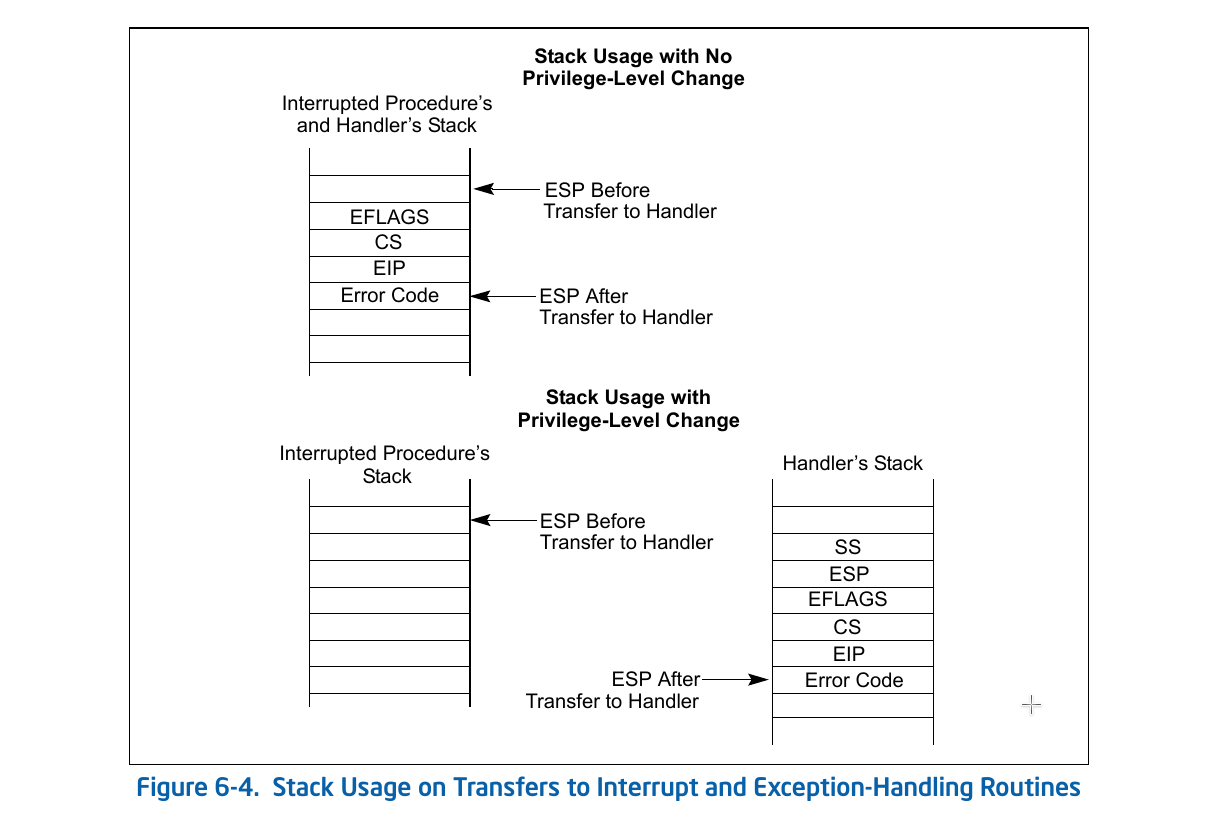
从内核态到用户态
中断处理例程处于ring 0,所以内核态发生的中断不发生堆栈切换,因此SS、ESP不会自动压栈;但是是否弹出SS、ESP确实由堆栈上的CS中的特权位决定的。当我们将堆栈中的CS的特权位设置为ring 3时,IRET会误认为中断是从ring 3发生的,执行时会按照发生特权级切换的情况弹出SS、ESP。
利用这个特性,只需要手动地将内核堆栈布局设置为发生了特权级转换时的布局,将所有的特权位修改为DPL_USER,保持EIP、ESP不变,IRET执行后就可以切换为应用态。
因为从内核态发生中断不压入SS、ESP,所以在中断前手动压入SS、ESP。中断处理过程中会修改tf->tf_esp的值,中断发生前压入的SS实际不会被使用,所以代码中仅仅是压入了%eax占位。
为了在切换为应用态后,保存原有堆栈结构不变,确保程序正确运行,栈顶的位置应该被恢复到中断发生前的位置。SS、ESP是通过push指令压栈的,压入SS后,ESP的值已经上移了4个字节,所以在trap_dispatch将ESP下移4字节。为了保证在用户态下也能使用I/O,将IOPL降低到了ring 3。
static void
lab1_switch_to_user(void) {
//LAB1 CHALLENGE 1 : TODO
__asm__ __volatile__ (
"pushl %%eax
"
"pushl %%esp
"
"int %0
"
:
:"i" (T_SWITCH_TOU)
);
}
case T_SWITCH_TOU:
if ((tf->tf_cs & 3) == 0) {
tf->tf_cs = USER_CS;
tf->tf_ss = tf->tf_ds = tf->tf_es = tf->tf_gs = tf->tf_fs = USER_DS;
tf->tf_esp += 4;
tf->tf_eflags |= FL_IOPL_MASK;
}
break;
堆栈结构如下:
kernel stack
+ . +
+ . +
+ . + low address
+--------------------+
+ EIP +
+ +
+--------------------+
+ CS +
+--------------------+
+ padding1 +
+--------------------+
+ EFLAGS +
+ +
+--------------------+------------------------------------+
+ ESP +-----------+ +
+ + | +
+--------------------+<----------+ +
+ SS + +
+--------------------+ +------ push by hand
+ padding0 + +
+--------------------+<-- original stack pointer +
+ . + | +
+ . + | +
+ . + ++++++++++++++++++++++++++++++++++++
+ +
high address
从用户态到内核态
在用户态发生中断时堆栈会从用户栈切换到内核栈,并压入SS、ESP等寄存器。在篡改内核堆栈后IRET返回时会误认为没有特权级转换发生,不会把SS、ESP弹出,因此从用户态切换到内核态时需要手动弹出SS、ESP。
实现如下:
static void
lab1_switch_to_kernel(void) {
__asm__ __volatile__ (
"int %0
"
"popl %%esp
"
:
:"i" (T_SWITCH_TOK)
);
}
case T_SWITCH_TOK:
if ((tf->tf_cs & 3) != 0) {
tf->tf_cs = KERNEL_CS;
tf->tf_ss = tf->tf_ds = tf->tf_es = tf->tf_gs = tf->tf_fs = KERNEL_DS;
tf->tf_eflags &= ~FL_IOPL_MASK;
}
break;
中断处理过程中内核栈结构与上图相同,但是tf->tf_esp指向发生中断前用户栈栈顶,IRET执行后程序仍处于内核态,内核堆栈结构如下:
kernel stack
+ . + low address
+ . +
+ . +
+--------------------+<-- stack pointer after IRET user stack
+ ESP +---------------------------->+--------------------+
+ + + +
+--------------------+ + +
+ SS + + +
+--------------------+ + +
+ padding0 + + +
+--------------------+ + +
+ . +
+ . +
+ . +
+ + high address
执行结果:

make grade结果:

拓展练习2
拓展练习2使用的技术与拓展练习1相同,通过篡改堆栈来欺骗IRET实现希望实现的功能。但是拓展练习1是在某个特定的函数中切换特权级,给了我们足够的空间去篡改、修复堆栈。但是在拓展练习2中,中断可以在任何时候发生,我们没有从中断处理返回后修复堆栈的机会,所有的操作都必须要在中断处理的过程中完成。
从内核态切换到用户态
按照拓展练习1中的思路,在中断发生前要手动压入SS、ESP,但在这里中断可以在任意时刻发生,没有机会提前压入SS、ESP,所以实现从内核态切换到用户态的关键就是如何在中断处理过程补齐8个字节。这里的思路是:
- 将trapframe上保存的%esp(指向trapframe)减8字节
- 将trapframe及其上面(低地址)的全部堆栈内容向低地址平移8字节
- 修改%esp指向平移后的栈顶
- 修改堆栈中的%ebp,确保程序正确执行
- 设置堆栈中的SS、ESP
当trap函数返回时,__alltraps会将堆栈保存的%esp恢复到%esp寄存器中,使得栈顶指针指向trapframe。
case IRQ_OFFSET + IRQ_KBD:
c = cons_getc();
cprintf("kbd [%03d] %c
", c, c);
switch (c) {
case '0' :
/* codes */
break;
case '3' :
if (trap_in_kernel(tf)) {
__asm__ __volatile__ (
"pushl %%esi
"
"pushl %%edi
"
"pushl %%ebx
"
/* set %esp(upon trapframe) to correct position */
"subl $8, -4(%%edx)
"
/* move space opon trapframe and trapframe to low address */
"movl %%esp, %%esi
"
/* %eax - the highest bound of trapframe */
"movl %%eax, %%ecx
"
"subl %%esi, %%ecx
"
"incl %%ecx
"
"movl %%esp, %%edi
"
"subl $8, %%edi
"
"cld
"
"rep movsb
"
/* correct %esp and %ebp */
"subl $8, %%esp
"
"subl $8, %%ebp
"
"movl %%ebp, %%ebx
"
"loop:
"
"subl $8, (%%ebx)
"
"movl (%%ebx), %%ebx
"
"cmpl %%ebx, %%eax
"
"jg loop
"
/* set esp and ss */
"movl %%eax, -8(%%eax)
"
"movl %2, -4(%%eax)
"
"popl %%ebx
"
"popl %%edi
"
"popl %%esi
"
:
:"a" ((uint32_t)(&tf->tf_esp)),
"d" ((uint32_t)(tf)),
"i" ((uint16_t)USER_DS)
:"%ecx", "memory"
);
correct_tf->tf_cs = USER_CS;
correct_tf->tf_ds = tf->tf_es = tf->tf_gs = tf->tf_fs = USER_DS;
correct_tf->tf_eflags |= FL_IOPL_MASK;
}
break;
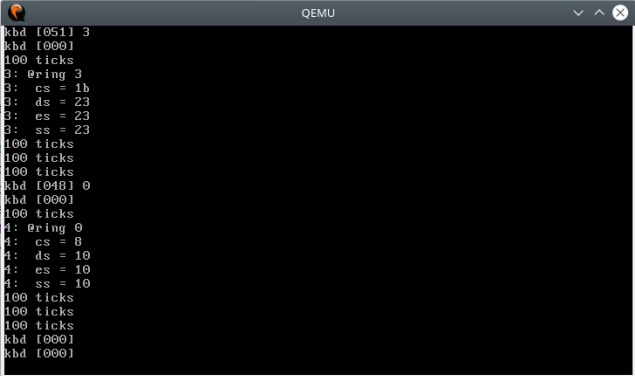
为了观察执行结果,修改了kern/init/init.c中的循环,让ucore定期显示程序的特权级。
long cnt = 0;
while (1) {
if ((++cnt) % 10000000 == 0)
lab1_print_cur_status();
}
运行结果如下:

从用户态切换到内核态
安装拓展练习1的思路,要在IRET后修改ESP的值,但在这里没有这个机会,所以关键就在于在中断处理过程中修改堆栈的结构,使得IRET后ESP被修改到合适的值。思路如下:
- 修改内核堆栈中的各寄存器值
- 将trapframe中tf->tf_esp之上(更低地址)的部分复制到用户堆栈上,确保使用用户堆栈IRET后ESP指向中断发生前的栈顶
- 将内核堆栈trapframe上面保存的%esp指向用户态堆栈上的trapframe,确保IRET返回时使用的时用户栈。
具体步骤图示如下:
kernel stack
+--------------------+
+ ESP +-----+
+ + |
+--------------------+-----+------+ +--------------------+ <--stack pointer
+ + | | + + after IRET
+ + | | + +
+ + | | + +
+ + | | + +
+ + | | + +
+ + | | + +
+ + | | + +
+ + | | + +
+ + | | copy + +
+ + | |=====> + +
+ + | | + +
+ + | | + +
+ + +------+--+ + +
+ + | | + +
+ + | | + +
+--------------------+ | +-->+-+--------------------+ <---original
+ ESP + +-+------+ + + user stack
+ + | | + + pointer
+--------------------+ copy | | + +
+ SS + <========| | + +
+--------------------+ | | + +
+ padding 0 + +-------+-+ + +
+--------------------+--+ +----------+ +
+ +
+ +
+ +
具体实现如下:
case IRQ_OFFSET + IRQ_KBD:
c = cons_getc();
cprintf("kbd [%03d] %c
", c, c);
switch (c) {
case '0' :
if (!trap_in_kernel(tf)) {
tf->tf_cs = KERNEL_CS;
tf->tf_ds = tf->tf_es = tf->tf_gs = tf->tf_fs = KERNEL_DS;
tf->tf_eflags &= ~FL_IOPL_MASK;
uintptr_t user_stack_ptr = (uintptr_t)tf->tf_esp;
tf->tf_esp = *((uint32_t *) user_stack_ptr);
tf->tf_ss = *((uint16_t *) (user_stack_ptr + 4));
tf->tf_padding0 = *((uint16_t *) (user_stack_ptr + 6));
user_stack_ptr -= (uintptr_t) (sizeof(struct trapframe) - 8);
*((struct trapframe *) user_stack_ptr) = *tf;
__asm__ __volatile__ (
"movl %%ebx, -4(%%eax)
"
:
:"a" ((uint32_t) tf),
"b" ((uint32_t) user_stack_ptr)
);
}
break;
...
运行截图: