泰坦尼克数据集描述:
案例数:1309
特征数:14个,包括年龄,性别,舱位等
总存活率:38%
整个分析分为两部分:一是根据性别和舱位进行统计描述推断,二是对幸存进行预测
统计描述部分只详细看仓位和性别这两个特征值,以及它们的联合起来对幸存率的影响,我们通过简单的三张统计表格就可以发现数据具有欺骗与真实的双面性。
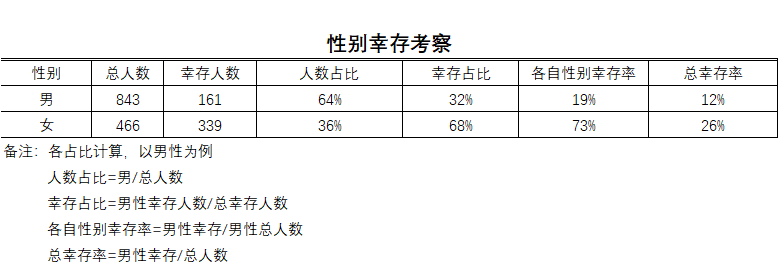
从男女各自的总幸存率看,男女幸存比大约为1:2,单从这点看男女幸存的比例并不是很悬殊。但是结合人数占比,男性大约占了6.5成,就可以看出总幸存比并不能很好的描述泰坦尼克中男女幸存的真实情况,最能反映性别幸存差异的是男女在各自性别中的幸存比例,可以看到男性的死亡率超过了八成!女性的幸存率达到了73%!接下来我们继续看舱位的情况。
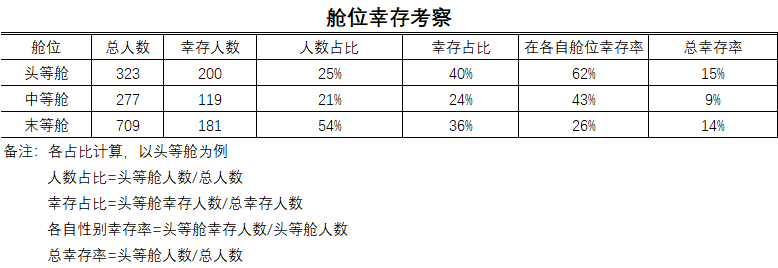
从总幸存率来看,头等舱和末等舱的存活率几乎是相同的,死亡率最高的是中等舱。但是真实情况真的是这样吗?再看幸存占比,幸存占比的反映的情况跟总存活率差不多,但是我们再看人数占比,就会发现前面两者反映出来并不是正真的事实,因为如果按照人数占比去推算幸存人数,那末等舱的幸存率应该超过5成才是合理的,但是统计出来的数据却只有不到4成!真正能反映事实的是各自舱位的幸存率,可以很明显的看到所谓中等舱死亡率最高只是一种假象,恰恰相反的是中等舱的幸存率接近了5成!而看似生存率跟头等舱一样的末等舱才是真正的死亡深渊!接着我们来看看舱位和性别对存活有怎么样的影响。

从舱位与性别的联合来看,头等舱的女性的幸存率是最高的,接近了100%,于此同时头等舱的男性的幸存率也是所有舱位中男性幸存率最高的。但是很惊人的一点是,与另外两个舱位相比,末等舱的女性幸存率相差非常之悬殊,只有差不多五成!但是末等舱男性的各自性别幸存率并没有高过于其他两个舱位,与中等舱几乎是一致的。究竟是什么原因导致了末等舱的女性幸存率如此之低?
统计推断结论:
1.不管任何舱位女性的幸存率远远都高于男性
2.头等舱是所有舱位中不管是男性还是女性幸存率都是最高的
3.中等舱总幸存率居于第二,但是男性的幸存率和三等舱男性的幸存率是几乎一致的
4.末等舱中女性幸存率是所有舱位中女性幸存率最低的
生存预测:
预测模型选择:二分类问题,采用逻辑回归进行预测
特征值选择:舱位、性别、年龄、兄弟姐妹数/配偶数、父母数/子女数
目标值:是否幸存
步骤:
1.数据清洗,缺失值等处理
2.分割数据成训练集和测试集
3.特征工程处理,将字符型变量转化为one-hot编码
4.进行标准化处理
5.进行预测
6.模型调优
7.模型输出
导入相关库
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.feature_extraction import DictVectorizer from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.model_selection import GridSearchCV
读入数据
titanic = pd.read_csv(r"E:360DownloadsSoftware ableauTableaudata itanic_passenger_list.csv")
查看是否存在缺失值
print(titanic.isnull().any())
pclass False
survived False
name False
sex False
age True
sibsp False
parch False
ticket False
fare True
cabin True
embarked True
boat True
body True
home.dest True
可以观察到所需特征值中sex存在缺失值,需要进行处理
提取需要的特征和目标值
# 提取需要的特征值和目标值 x = titanic[['pclass', 'age', 'sex', 'sibsp', 'parch']] y = titanic['survived']
对年龄中的缺失值进行平均年龄的填充
# 对特征值中的年龄缺失值进行处理 x['age'].fillna(x['age'].mean(), inplace=True)
为了更好的查看,这里将列重命名
x.columns = ["仓位等级", "年龄", "性别", "乘客在船上的兄弟姐妹/配偶数量", "乘客在船上的父母/孩子数量"]
检查年龄中的缺失值是否已经处理
print(x.isnull().any())
仓位等级 False
年龄 False
性别 False
乘客在船上的兄弟姐妹/配偶数量 False
乘客在船上的父母/孩子数量 False
可以看到年龄中的缺失值已经处理好了
现在将数据集分割为训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
因为特征中性别是分类型的字符串变量,所以需要将其转换成one-hot编码
# 进行特征处理,将分类型数据转换成one-host编码 dictv = DictVectorizer(sparse=False) x_train = dictv.fit_transform(x_train.to_dict(orient="records")) x_test = dictv.fit_transform(x_test.to_dict(orient="records"))
接下来对特征值进行标准化处理,去除量纲的影响
# 进行标准化处理 x_std = StandardScaler() x_train = x_std.fit_transform(x_train) x_test = x_std.fit_transform(x_test)
进行回归预测
lg = LogisticRegression() lg.fit(x_train, y_train) y_predict = lg.predict(x_test)
print("准确率:", lg.score(x_test, y_test))
准确率: 0.7835365853658537
使用交叉验证和网格搜索对模型进行调优,调优参数是逻辑回归的正则化力度
# 构造网格搜索需要调优的参数 param = {"C":[i/1000 for i in range(1, 4000)]} # 进行网格搜索 gcv = GridSearchCV(estimator=lg, param_grid=param, cv=10) gcv.fit(x_train, y_train) print('在测试集上的准确率:', gcv.score(x_test, y_test)) print('在交叉验证中最好的结果:', gcv.best_score_) print('选择的最好的模型是:', gcv.best_estimator_)
在测试集上的准确率: 0.801829268292683
在交叉验证中最好的结果: 0.7858895073180787
选择的最好的模型是: LogisticRegression(C=0.002, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
可以看到调优给出的最佳正则化力度是0.002,给出的预测准确率是:0.801829268292683,比原来提高了大约2个百分点,如果模型的预测准确率没有达到预期,那么考虑对特征工程进行重新优化,或者考虑纳入更多的特征进行预测,或者考虑替换算法
最后保存模型
# 导入保存模型API from sklearn.externals import joblib # 保存模型 joblib.dump(lg, "./test.pkl")