把nutch的源代码导入到eclipse工程自定义抓取任务。
下载源码:
http://svn.apache.org/repos/asf/nutch/
从svn下载想要的nutch源码,这里选择nutch-1.1
编译源码:
使用ant编译源代码,编译成功,可以看到多了一个build目录,其中有plugins目录及nutch-1.1.job文件
新建WEB工程
新建web工程org.apache.nutch.web,执行以下操作
1、 把nutch源代码的src/java 目录复制到web工程的src目录
2、 把nutch源代码的src/conf目录复制到web工程的src目录
3、 把nutch源代码的src/lib目录复制到web工程的WEB-INF/lib目录
4、 把编译的plugins目录复制到web工程的src目录
5、 在web工程src新建目录job,把编译的nutch-1.1.job文件复制到src/job
6、 在web工程src新建目录test,建立测试类,用这个类去调用crawl的main()
package org.apache.nutch; import org.apache.nutch.crawl.Crawl; public class Main { public static void main(String[] args) { String[] arg = { "/urls/url.txt", "-dir", "crawled", "-depth", "10", "-topN", "50" }; try { Crawl.main(arg); } catch (Exception e) { e.printStackTrace(); } } }
Note:
1、 Nutch使用hadoop调度任务,使用前要编辑conf目录下的core-site.xml、hdfs-site.xml、mapred-site.xml等hadoop配置文件。
2、 Nutch-1.1中没有hbase的jar文件,需另下载并设置hbase的配置文件,这里用hbase-0.94.jar
FAQ:
这是一位网友收集的hadoop,hbase,zookeeper错误日志及部分解决办法,以备以后遇到问题作为参考之用。
1、 hadoop-0.20.2 & hbase-0.90.4集群启动错误问题解决:
问题如下:org.apache.hadoop.ipc.RPC$VersionMismatch: Protocol org.apache.hadoop.hdfs.protocol.ClientProtocol version mismatch. (client = 43, server = 41)
at org.apache.hadoop.ipc.RPC.getProxy(RPC.java:364)
at
org.apache.hadoop.hdfs.DFSClient.createRPCNamenode(DFSClient.java:113)
at
org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:215)
at
org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:177)
是hadoop-0.20.2 & hbase-0.90.4版本问题造成的,讲hbaselib引入的包替换为hadoop-0.20.2-core.jar即可
2、 org.apache.hadoop.security.AccessControlException: Permission denied: user=pc2000, access=WRITE
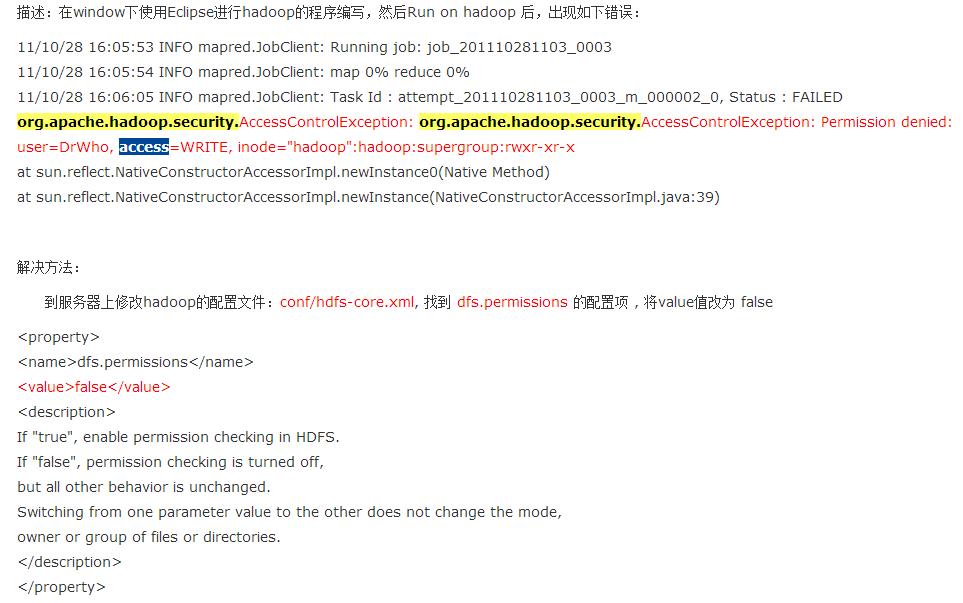
因为Eclipse使用hadoop插件提交作业时,会默认以 pc2000(计算机名) 身份去将作业写入hdfs文件系统中,对应的也就是 HDFS 上的/user/xxx , 由于 pc2000 用户对hadoop目录并没有写入权限,所以导致异常的发生。