一、Zookeeper工作机制
分布式和集中式系统相比,有很多优势,比如更强的计算能力,存储能力,避免单点故障等问题。但是由于在分布式部署的方式遇到网络故障等问题的时候怎么保证各个节点数据的一致性和可用性是比较关键的问题。
那么,对于分布式集群来说,我们需要一个能够在各个服务和节点之间进行协调和服务的中间人——Zookeeper。
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的回应。
二、数据结构
Zookeeper的数据结构和linux的目录结构类似,也像数据结构中的树,如下图:
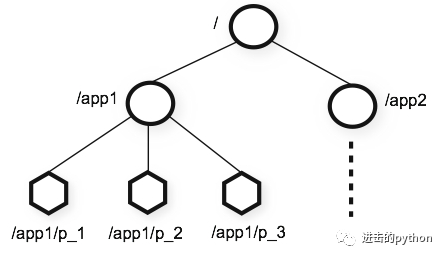
Zookeeper的数据存储基于节点,这种节点称为Znode。Znode的引用方式是路径的引用,每个Znode都可以通过其路径唯一标识。
其中Znode中包含有:数据,子节点引用,访问权限等,如下图:
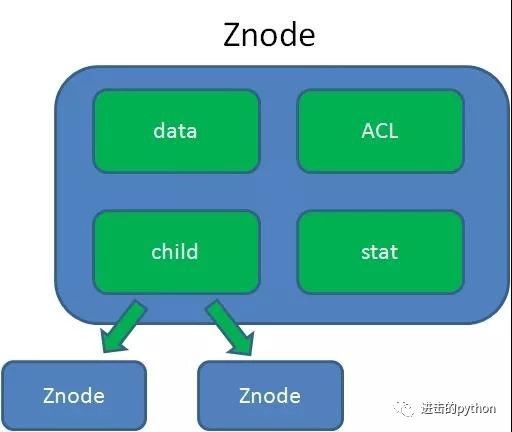
- data:Znode存储的数据信息
- ACL:记录Znode的访问权限,即哪些人或哪些IP可以访问本节点
- child:当前节点的子节点引用,类似于二叉树的左孩子右孩子
- stat:包含Znode的各种元数据,比如事务ID、版本号、时间戳、大小等等
stat 查看根目录的详细信息:
[zk: localhost:2181(CONNECTED) 0] stat /
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = -1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
三、选举机制
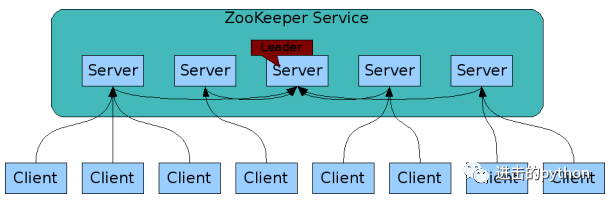
Zookeeper集群是一主多从的模式,主为leader,从为follower,其中leader是通过选举得到。
Zookeeper集群有如下特点:
- Zookeeper:一个领导者(leader),多个跟随者(follower)组成的集群
- Leader负责进行投票的发起和决议,更新系统状态
- Follower用于接收客户请求并向客户端返回结果,在选举Leader过程中参与投票
- 集群中只要有半数以上节点存活,Zookeeper集群就能正常服务,所以Zookeeper适合安装奇数台服务器
- 全局数据一致:每个server保存一份相同的数据副本,client无论连接到哪个server,数据都是一致的
- 更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行
- 数据更新原子性,一次数据更新要么成功,要么失败
- 实时性,在一定时间范围内,client能读到最新数据
Leader选举是保证分布式数据一致性的关键所在,当Zookeeper进入以下两种状态时,需要进入leader选举:
- 服务器初始化启动
- leader宕机挂掉
- 服务器初始化启动时的选举
(1)以三台服务器组成的集群为例,在集群的初始化阶段,当server1启动时,其单独无法完成选举;当server2启动时,此时两台机器可以互相通信,每台机器都试图找到leader,于是进入选举状态
(2)每个server首先给自己投票:初始阶段,每个服务器都将自己作为leader来投票,每次投票包含的信息有(myid,ZXID,epoch),此时Server1的投票为(1, 0),Server2的投票为(2, 0),然后各自将这个投票发给集群中其他机器
其中epoch用来判断多个投票是否在同一轮选举周期中,该值在服务端是一个自增序列,每次进入新一轮的投票后,都会对该值进行加1操作
(3)每个server接受来自各个服务器的投票:集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票、是否来自LOOKING状态的服务器
(4)处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行PK,PK规则如下:
- 优先检查ZXID。ZXID比较大的服务器优先作为Leader
- 如果ZXID相同,那么就比较myid。myid较大的服务器作为Leader服务器
对于Server1而言,它的投票是(1, 0),接收Server2的投票为(2, 0),首先会比较两者的ZXID,均为0,再比较myid,此时Server2的myid最大,于是更新自己的投票为(2, 0),然后重新投票,对于Server2而言,其无须更新自己的投票,只是再次向集群中所有机器发出上一次投票信息即可
(5)统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于Server1、Server2而言,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,此时便认为已经选出了Leader,一旦选出leader,后边的机器不管myid和ZXID多大,都自动成为leader的小弟
(6)改变服务器状态。一旦确定了Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为FOLLOWING,如果是Leader,就变更为LEADING
- leader服务器挂掉的投票机制
与启动时不同的就是,每个服务器上都有历史数据,在选举之前,首先非leader的服务器改变状态为LOOKING状态,因为运行期间每个服务器ZXID不同,会和启动时的选举一样进行重新投票选举。
四、监听机制

- 首先要有一个main()线程
- 在main线程中创建Zookeeper客户端,这时就会创建两个线程,一个负责网络连接通信(connet),一个负责监听(listener)
- 通过connect线程将注册的监听事件发送给Zookeeper
- 在Zookeeper的注册监听器列表中将注册的监听事件添加到列表中
- Zookeeper监听到有数据或路径变化,就会将这个消息发送给listener线程
- listener线程内部调用了process()方法
五、API应用
Zookeeper常用的API如下:
create
创建节点
delete
删除节点
exists
判断节点是否存在
getData
获得一个节点的数据
setData
设置一个节点的数据
getChildren
获取节点下的所有子节点
这其中,exists,getData,getChildren属于读操作。Zookeeper客户端在请求读操作的时候,可以选择是否设置Watch。
Watch是什么意思呢?
我们可以理解成是注册在特定Znode上的触发器。当这个Znode发生改变,也就是调用了create,delete,setData方法的时候,将会触发Znode上注册的对应事件,请求Watch的客户端会接收到异步通知。
具体交互过程如下:
- 客户端调用getData方法,watch参数是true。服务端接到请求,返回节点数据,并且在对应的哈希表里插入被Watch的Znode路径,以及Watcher列表。
- 当被Watch的Znode已删除,服务端会查找哈希表,找到该Znode对应的所有Watcher,异步通知客户端,并且删除哈希表中对应的Key-Value
六、应用场景
Zookeeper提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。