前言
数据库的查询执行,毋庸置疑是程序员必备技能之一,然而数据库查询执行的过程绚烂多彩,却是很少被人了解,今天哥哥要带你装逼带你飞,深入一下这sql查询的来龙去脉,为查询的性能优化处理打个基础,或许面试你也会遇到,预防不跪还是看看吧。
这篇博客,摒弃查询优化性能,作为其基础,只针对查询流程讲解剖析。
本片博客阐述的过程为
1、上一个标识过的sql语句,展示查询执行的流程
2、上一个流程图
3、做一个例子逐步深入分析,帮助理解
4、做一个装逼的总结
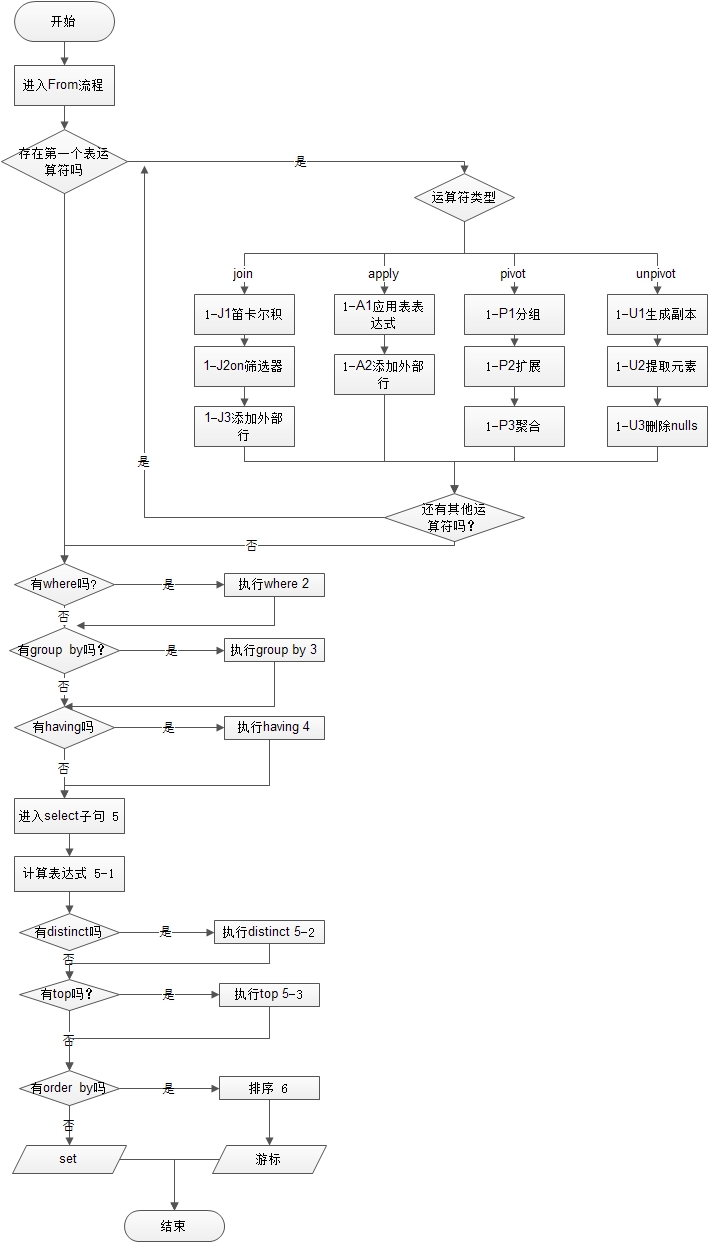
sql查询语句的处理步骤,代码清单
--查询组合字段 (5)select (5-2) distinct(5-3) top(<top_specification>)(5-1)<select_list> --连表 (1)from (1-J)<left_table><join_type> join <right_table> on <on_predicate> (1-A)<left_table><apply_type> apply <right_table_expression> as <alias> (1-P)<left_table> pivot (<pivot_specification>) as <alias> (1-U)<left_table> unpivot (<unpivot_specification>) as <alias> --查询条件 (2)where <where_pridicate> --分组 (3)group by <group_by_specification> --分组条件 (4)having<having_predicate> --排序 (6)order by<order_by_list>
说明:
1、顺序为有1-6,6个大步骤,然后细分,5-1,5-2,5-3,由小变大顺序,1-J,1-A,1-P,1-U,为并行次序。如果不够明白,接下来我在来个流程图看看。
2、执行过程中也会相应的产生多个虚拟表(下面会有提到),以配合最终的正确查询。
sql查询语句的处理步骤,流程图
实例准备,创建表,插入数据,写要分析的实例查询语句
1、首先创建2各表

2、创建两个表,并插入表数据,脚本如下


USE [test] GO /****** Object: Table [dbo].[Member] Script Date: 2014/12/22 14:05:17 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO SET ANSI_PADDING ON GO CREATE TABLE [dbo].[Member]( [id] [int] IDENTITY(1,1) NOT NULL, [Name] [nvarchar](30) NULL, [phone] [varchar](15) NULL, CONSTRAINT [PK_MEMBER] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO SET ANSI_PADDING OFF GO /****** Object: Table [dbo].[Order] Script Date: 2014/12/22 14:05:17 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[Order]( [id] [int] IDENTITY(1,1) NOT NULL, [member_id] [int] NULL, [status] [int] NULL, [createTime] [datetime] NULL, CONSTRAINT [PK_ORDER] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO SET IDENTITY_INSERT [dbo].[Member] ON GO INSERT [dbo].[Member] ([id], [Name], [phone]) VALUES (1, N'张龙豪', N'18501733702') GO INSERT [dbo].[Member] ([id], [Name], [phone]) VALUES (2, N'Jim', N'15039512688') GO INSERT [dbo].[Member] ([id], [Name], [phone]) VALUES (3, N'Tom', N'15139512854') GO INSERT [dbo].[Member] ([id], [Name], [phone]) VALUES (4, N'Lulu', N'15687425583') GO INSERT [dbo].[Member] ([id], [Name], [phone]) VALUES (5, N'Jick', N'13528567445') GO SET IDENTITY_INSERT [dbo].[Member] OFF GO SET IDENTITY_INSERT [dbo].[Order] ON GO INSERT [dbo].[Order] ([id], [member_id], [status], [createTime]) VALUES (1, 1, 3, CAST(0x0000A40900B3BBFB AS DateTime)) GO INSERT [dbo].[Order] ([id], [member_id], [status], [createTime]) VALUES (2, 2, 1, CAST(0x0000A40900B3CEF2 AS DateTime)) GO INSERT [dbo].[Order] ([id], [member_id], [status], [createTime]) VALUES (3, 3, 4, CAST(0x0000A40900B3D2D0 AS DateTime)) GO INSERT [dbo].[Order] ([id], [member_id], [status], [createTime]) VALUES (4, 4, 0, CAST(0x0000A40900B3D660 AS DateTime)) GO INSERT [dbo].[Order] ([id], [member_id], [status], [createTime]) VALUES (5, 5, 1, CAST(0x0000A40900B3D9B9 AS DateTime)) GO INSERT [dbo].[Order] ([id], [member_id], [status], [createTime]) VALUES (6, 6, 2, CAST(0x0000A40900B3DFEA AS DateTime)) GO INSERT [dbo].[Order] ([id], [member_id], [status], [createTime]) VALUES (7, NULL, 0, CAST(0x0000A40900E34971 AS DateTime)) GO SET IDENTITY_INSERT [dbo].[Order] OFF GO ALTER TABLE [dbo].[Order] ADD DEFAULT (getdate()) FOR [createTime] GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'编号' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Member', @level2type=N'COLUMN',@level2name=N'id' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'姓名' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Member', @level2type=N'COLUMN',@level2name=N'Name' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'电话' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Member', @level2type=N'COLUMN',@level2name=N'phone' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'会员表' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Member' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'编号' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Order', @level2type=N'COLUMN',@level2name=N'id' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'会员编号' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Order', @level2type=N'COLUMN',@level2name=N'member_id' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'订单状态' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Order', @level2type=N'COLUMN',@level2name=N'status' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'下单日期' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Order', @level2type=N'COLUMN',@level2name=N'createTime' GO EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'订单表' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Order' GO
3、编写咱们要解析的查询语句,即本篇要查询的实例语句。
select top(4) status , max(m.id) as maxMemberID from [dbo].[Member] as m right outer join [dbo].[Order] as o on m.id=o.member_id
where m.id>0 group by status having status>=0 order by maxMemberID asc
实例语句分步骤分析
第一步,从from开始。
1.1、加载左表
from [dbo].[Member] as m
查询结果:member表中的所有数据
1.2、这里应该是 right outer join ,但是这里在sql中被定义分解为2个步骤,即join ,right outer join 。表达式关键字从左到右,依次执行。
join [dbo].[Order] as o
查询结果:存入虚拟表vt1,为两个表的笛卡尔集合。这里你或许不明白什么叫笛卡尔集合,我打个比方给说说,还望不要嫌弃,就是小朋友握手问题,A班里有3个学生(看作一个表的三条数据),B班里有2个学生(看作另外一个表的2条数据).B班小朋友跟A班小朋友搞联欢晚会,首先要每个人都要确保跟另外一个班的同学我一下手,那么交叉出来的集合就是(2*3=6)有6条不同的轨迹。这个轨迹的集合就是笛卡尔集合。如果你还不明白,我再说下,就是m(5条数据)表中的第一条数据跟o(7条数据)表中的所有数据握下手,有7条,然后依次类推共有35条不同的数据。这里的null值也是要加进来的。
1.3、on 筛选器
on m.id=o.member_id
查询结果: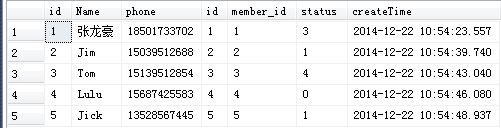 从上一步的笛卡尔集合35条数据中删除掉不匹配的行,就得到啦5条数据,存入虚拟表Vt2
从上一步的笛卡尔集合35条数据中删除掉不匹配的行,就得到啦5条数据,存入虚拟表Vt2
1.4、添加外部行(outer row)
right outer join [dbo].[Order] as o
查询结果为: 右表(order)作为保留表,把剩余的数据重新添加到上一步的虚拟表中vt2,生成虚拟表vt3.
右表(order)作为保留表,把剩余的数据重新添加到上一步的虚拟表中vt2,生成虚拟表vt3.
第二部,进入where阶段
where m.id>0
查询结果:存入虚拟表vt4,为筛选的条件为true的结果集,这里加入一个记忆点,就是,where的筛选删除为永久的,而on的筛选删除为暂时的,因为on筛选过后,有可能会经过outer添加外部行,重新把数据加载回来,而where则不能。
第三部,group by分组
group by status
查询结果:存入vt5,以status列的数值开始分组,即status列,值一样的分为一组,这里的两个null在三值逻辑中被视为true。三值逻辑:true,false,null。此三值,null为未知,是数据的逻辑特色,有的地方两个null相等为ture,在有些地方则为false。这个你百度下看看有很多讲解。
第四步,having筛选器
having status>=0
查询结果:筛选分好组的组数据,把不满足条件的删除掉
第五步,select查询挑拣计算列
5.1、计算表达式
select status , max(m.id)
查询结果:从分过组的数据中计算各个组中的最大m.id,列出要筛选显示的列。
5.2、distinct过滤重复
5.3、top 结合order by 筛选 多少行,但这里的数据没有排序只是把多少行数据列出来而已。
第六部,order by 排序显示。
蛋疼的总结,装逼是有依据的
本篇博客参考:《Microsoft SQL Server 2008技术内幕:T-SQL查询》,感谢阅读,(C#).NET技术分享QQ群: 232458226,欢迎加入。