安装scrapy-redis
pip install scrapy-redis
从GitHub 上拷贝源码:
clone github scrapy-redis源码文件 git clone https://github.com/rolando/scrapy-redis.git
scrapy-redis的工作流程
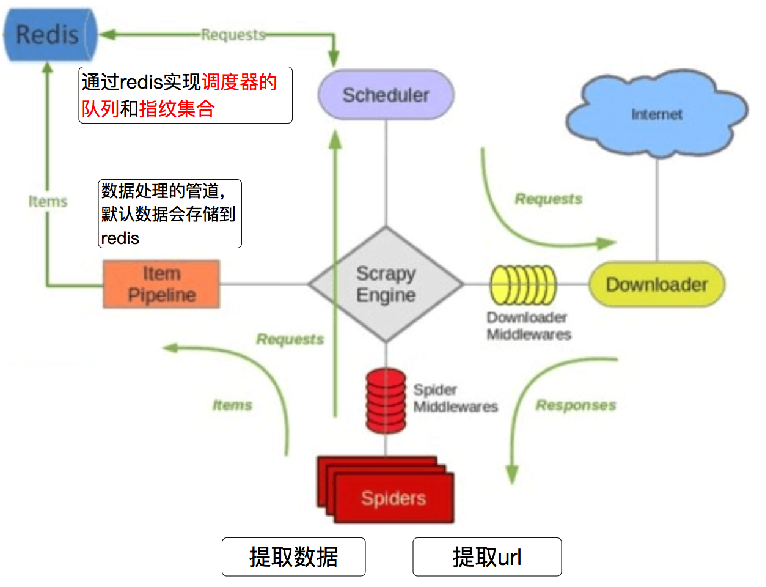
Scrapy_redis之domz 例子分析
1.domz爬虫:

2.配置中:

3.执行domz的爬虫,会发现redis中多了一下三个键

redispipeline中仅仅实现了item数据存储到redis的过程,我们可以新建一个pipeline(或者修改默认的ExamplePipeline),可以让数据存储到任意地方。
scrapy-redis 的源码分析
1.Scrapy_redis之RedisPipeline

2.Scrapy_redis之RFPDupeFilter

3.Scrapy_redis之Scheduler

domz相比于之前的spider多了持久化和request去重的功能,setting中的配置都是可以自己设定的,
意味着我们的可以重写去重和调度器的方法,包括是否要把数据存储到redis(pipeline)
1.Scrapy_redis之RedisSpider

2. Scrapy_redis之RedisCrawlSpider

scrapy-redis 配置:
在爬虫项目的settings.py文件中,可以做一下配置
# ####################### redis配置文件 ####################### REDIS_HOST = '192.168.11.81' # 主机名 REDIS_PORT = 6379 # 端口 # REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于以上配置) # REDIS_PARAMS = {} # Redis连接参数 默认:REDIS_PARAMS = {'socket_timeout': 30,'socket_connect_timeout': 30,'retry_on_timeout': True,'encoding': REDIS_ENCODING,}) # REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient' # 指定连接Redis的Python模块 默认:redis.StrictRedis REDIS_ENCODING = "utf-8" # redis编码类型 默认:'utf-8' # df DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 也可以自定义自己的去重规则 from scrapy_redis.scheduler import Scheduler SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 调度器 from scrapy_redis.queue import PriorityQueue from scrapy_redis import picklecompat SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表) SCHEDULER_QUEUE_KEY = '%(spider)s:requests' # 调度器中请求存放在redis中的key SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 对保存到redis中的数据进行序列化,默认使用pickle SCHEDULER_PERSIST = True # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空 SCHEDULER_FLUSH_ON_START = False # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空 SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。 SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter' # 去重规则,在redis中保存时对应的key SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' # 去重规则对应处理的类 from scrapy_redis.pipelines import RedisPipeline ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline': 300, } REDIS_ITEMS_KEY = '%(spider)s:items' REDIS_ITEMS_SERIALIZER = 'json.dumps'
Crontab爬虫定时执行


Scrapy-redis 中的知识总结
request对象什么时候入队
-
dont_filter = True ,构造请求的时候,把dont_filter置为True,该url会被反复抓取(url地址对应的内容会更新的情况)
-
一个全新的url地址被抓到的时候,构造request请求
-
url地址在start_urls中的时候,会入队,不管之前是否请求过
-
构造start_url地址的请求时候,dont_filter = True
-
def enqueue_request(self, request):
if not request.dont_filter and self.df.request_seen(request):
# dont_filter=False Ture True request指纹已经存在 #不会入队
# dont_filter=False Ture False request指纹已经存在 全新的url #会入队
# dont_filter=Ture False #会入队
self.df.log(request, self.spider)
return False
self.queue.push(request) #入队
return True
scrapy_redis去重方法
-
使用sha1加密request得到指纹
-
把指纹存在redis的集合中
-
下一次新来一个request,同样的方式生成指纹,判断指纹是否存在reids的集合中
生成指纹
fp = hashlib.sha1()
fp.update(to_bytes(request.method)) #请求方法
fp.update(to_bytes(canonicalize_url(request.url))) #url
fp.update(request.body or b'') #请求体
return fp.hexdigest()
判断数据是否存在redis的集合中,不存在插入
added = self.server.sadd(self.key, fp) return added != 0