对于任何一门语言而言,在运行过程中都会创建许多对象,继而需要为这些对象分配内存地址,当这些对象不需要使用的时候,需要释放其占用的内存地址,以供新的对象使用。关于对象内存释放的这一机制就叫做垃圾回收机制(GC)。
Java中垃圾回收是自动化的,但其可控性差,内存容易溢出。内存溢出是因为JVM内存分配的对象过多,这些对象所需内存超出了JVM内存大小。虽然Java中是自动的。但是程序员仍可调用System.gc( )来进行手动回收,调用此方法会尝试释放被丢弃的对象占用的内存,但结果无法保证,因此附带一个免责声明。
确定回收对象有两个算法:引用计数法与可达性分析法。
引用计数法
系统会为对象添加一个计数器,当有新的引用时加1,引用失效时减1。但是此方法无法解决两个对象循环引用的问题。
可达性分析法
通过对象的引用链来判断该对象是否需要被回收,通过一系列的GC Roots的对象作为起始点,从这些根节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链相连时,则证明此对象是不可用的,就需要回收此对象。
参考: https://blog.csdn.net/seriousboy/article/details/81913799
标准C++没有垃圾回收机制的原因:
1) 没有共同基类
C++是从C发展而成,同意直接操作指针,同意将一个类型转换为还有一个类型,对于一个指针无法知道它真正指向的类型;而Java或C#都有一个共同基类
2) 系统开销
垃圾回收所带来的系统开销,不符合C++高效的特性,使得不适合做底层工作
3) 耗内存
C++产生的年代内存非常少,垃圾回收机制须要占用很多其它的内存
4) 替代方法
C++有析构函数、智能指针、引用计数去管理资源的释放,对GC的需求不迫切
C++实现垃圾回收机制
在Java、C#、AS这些语言中,上面的代码是没有任何问题的,因为你借了这些内存空间,在程序结束后,虚拟机会帮你还,也就是说,它们自带有垃圾回收机制,而C++?必须得手动delete,如果只是new出来一两个,手动delete还不觉得这么麻烦,但是如果你new出来很多东西,那怎么办,你得一个个记住,然后一个个delete?就像你借了很多人的钱,你必须记住谁谁借了钱给我,你这时会感叹,如果能有个人帮我还钱,那该多好啊,那样的话,你就只管借而不用担心钱没还而惹来的麻烦了。那在C++里,怎么实现呢?
智能指针可以解决问题
编译器说std里没有auto_ptr的话,#include<memory>就可以了,这就是智能指针的好处,只要你这个智能指针不是new创建出来的,它会答应帮你delete掉,如果你是new出来的,那么也得delete,否则它无法完成它的承诺。
这里需要注意的是,在使用new和delete时的一些事情,当使用new实例化时,编译器做了两件工作:
(1)首先在堆内存开辟了该类大小的空间,也就是说会先调用operator new(std::size_t)函数开辟空间,至于调用全局的还是这个类的,就要看这个类是否重载了operator new(std::size_t),如果这个类重载了,便调用该类提供的,编译器会调用sizeof(Human)计算出这个类的内存大小,然后作为实参传入到这个函数中,这个函数分配好空间了,返回这个内存空间的首地址。
(2)分配好内存空间后,调用这个类的构造函数,上面调用的是默认构造函数。
那么当delete的时候,编译器也做了两件事,是new相反顺序的,
(1)首先调用这个对象的析构函数
(2)再调用void operatordelete(void*)函数进行回收空间,至于调用全局
还是这个类提供的,就看这个类是否重载了这个函数。
关于operator new 与operator delete的信息,可以研究一下C++ Primer第四版,那里会有更详细的说明。
还得注意的是,这里采用的是vector顺序表来存储指针,如果你担心内存,可以采用list链表才存储,因为vector的erase移除操作并非是真正的释放空间,虽然你delete掉了pHuman的指针所指的内存,但是vector内部并没有收回掉那4个字节的内存,因为它要预留着下次来使用,那样就不需要再分配内存了。当然,你可以调用vector的析构函数来释放vector保存指针的那4个字节内存。
还有个问题是,如果自定义一个新类型时,必须得继承Object,不然得自行提供operator new和operator delete,否则无法自动回收内存。
————————————————
参考:https://blog.csdn.net/u012611878/article/details/78947267
C++中垃圾回收机制中几种经典的垃圾回收算法
垃圾(Garbage)就是程序需要回收的对象,如果一个对象不在被直接或间接地引用,那么这个对象就成为了「垃圾」,它占用的内存需要及时地释放,否则就会引起「内存泄露」。有些语言需要程序员来手动释放内存(回收垃圾),有些语言有垃圾回收机制(GC)。本文就来讨论GC实现的三种基本方式。
其实这三种方式也可以大体归为两类:跟踪回收,引用计数。一个理论:任何垃圾回收的思路,无非以上两种的组合,其中一种的改善和进步,必然伴随着另一种的改善和进步。
跟踪回收
跟踪回收的方式独立于程序,定期运行来检查垃圾,需要较长时间的中断。
标记清除
标记清除的方式需要对程序的对象进行两次扫描,第一次从根(Root)开始扫描,被根引用了的对象标记为不是垃圾,不是垃圾的对象引用的对象同样标记为不是垃圾,以此递归。所有不是垃圾的对象的引用都扫描完了之后。就进行第二次扫描,第一次扫描中没有得到标记的对象就是垃圾了,对此进行回收。
复制收集
复制收集的方式只需要对对象进行一次扫描。准备一个「新的空间」,从根开始,对对象进行扫,如果存在对这个对象的引用,就把它复制到「新空间中」。一次扫描结束之后,所有存在于「新空间」的对象就是所有的非垃圾对象。
这两种方式各有千秋,标记清除的方式节省内存但是两次扫描需要更多的时间,对于垃圾比例较小的情况占优势。复制收集更快速但是需要额外开辟一块用来复制的内存,对垃圾比例较大的情况占优势。特别的,复制收集有「局部性」的优点。
在复制收集的过程中,会按照对象被引用的顺序将对象复制到新空间中。于是,关系较近的对象被放在距离较近的内存空间的可能性会提高,这叫做局部性。局部性高的情况下,内存缓存会更有效地运作,程序的性能会提高。
对于标记清除,有一种标记-压缩算法的衍生算法:
对于压缩阶段,它的工作就是移动所有的可达对象到堆内存的同一个区域中,使他们紧凑的排列在一起,从而将所有非可达对象释放出来的空闲内存都集中在一起,通过这样的方式来达到减少内存碎片的目的。
引用计数
引用计数是指,针对每一个对象,保存一个对该对象的引用计数,该对象的引用增加,则相应的引用计数增加。如果对象的引用计数为零,则回收该对象。
优点:引用计数最大的优点就是容易实现,C++程序员应该都实现过类似的机制。二是成本小,基本上引用计数为0的时候垃圾会被立即回收,而其他方法难以预测对象的生命周期,垃圾存在的时间都会比这个方法高。另,这种垃圾回收方式产生的中断时间最短。
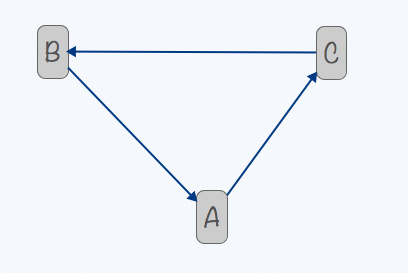
缺点:最著名的缺点就是如果对象中存在循环引用,就无法被回收。例如,下面三个对象互相引用,但是不存在从根(Root)指向的引用,所以已经是垃圾了。但是引用计数不为0.
还有一个缺点就是,引用计数不适合在并行中使用,多个线程同时操作引用计数,会引起数值不一样的问题从而导致内存错误。所以引用计数必须采用独占方式,如果引用操作频繁,那么加锁等并发控制机制的开销是相当大的。
Perl和Python采用了这种GC机制。
它们的衍生算法
分代回收
这种回收方式用了程序的一种特性:大部分对象会从产生开始在很短的时间内变成垃圾,而存在的很长时间的对象往往都有较长的生命周期。高频对新生成的对象进行回收,称为「小回收」,低频对所有对象回收,称为「大回收」。每一次「小回收」过后,就把存活下来的对象归为「老生代」,「小回收」的时候,遇到老生代直接跳过。大多数分代回收算法都采用的「复制收集」方法,因为小回收中垃圾的比例较大。
这种方式存在一个问题:如果在某个新生代的对象中,存在「老生代」的对象对它的引用,它就不是垃圾了,那么怎么制止「小回收」对其回收呢?这里用到了一中叫做写屏障的方式。
程序对所有涉及修改对象内容的地方进行保护,被称为「写屏障」(Write Barrier)。写屏障不仅用于分代回收,也用于其他GC算法中。
在此算法的表现是,用一个记录集来记录从新生代到老生代的引用。如果有两个对象A和B,当对A的对象内容进行修改并加入B的引用时,如果①A是「老生代」②B是「新生代」。则将这个引用加入到记录集中。「小回收」的时候,因为记录集中有对B的引用,所以B不再是垃圾。
增量回收
上面的算法缩短了「GC平均中断时间」,但是在对实时性要求很高的程序中,对「GC最高中断时间」的要求更高。比如,自动驾驶软件,如果某次GC中断了0.1s,那么损失可能是致命的。
增量回收就是将GC分成几部分来执行。设置「GC最多中断10ms」这样的条件限制来使GC的终端时间视作可预测的。
但是,在两段的GC程序之间,引用关系可能发生了变化。所以,这种GC算法也要写屏障,来记录引用关系的变化。虽然这种方式控制了中断最高时间,但是由于中断次数增加,GC总时间是增加的。
并行回收
基本原理是,在程序运行的同时进行GC工作,最大化CPU的性能。但是这种方式也要面对增量回收的问题,所以也要进行写屏障操作。
然而这种方式也并未做到完全不暂停原程序的运行,在某些特定的GC阶段还是要暂停原程序。多核化迅速发展的今天,这种算法也在不断优化。不间断原程序实现并行回收这个领域是相当值得期待的。
参考:https://www.cnblogs.com/semi-sub/p/13062796.html