PyTorch分布式训练详解教程 scatter, gather & isend, irecv & all_reduce & DDP
本文将从零入手,简单介绍如何使用PyTorch中的多种方法进行分布式训练。
具体而言,我们将使用四种方法,分别是: (1)scatter, gatter; (2)isend, irecv; (3)all_reduce; (4)DataDistributedParallel (DDP).
其简单原理是将数据集分区(partition data),之后分别发送到不同的节点进行训练,再将所获得的数据,例如梯度,发送到同一个节点进行运算如相加求和,再重新将参数分发到不同的结点。
本文将以VGG11模型和Cifar10数据集为例,具体介绍如何使用这四种方法进行分布式训练。
本文的实验环境为4节点Ubuntu18环境,分别为node0, node1, node2, node3,其中node0作为master节点,负责发送数据到其他节点,收集其他节点的数据,以及计算。请注意,本文中master节点特指node0,slave节点指node1, node2, node3(即便它们之间并非master和slave的关系)。Python环境为Anaconda下3.8版本,Pytorch 1.4版本。
本文不使用GPU,而是直接用CPU进行训练。但本文的代码只需要修改device参数即可移植到GPU上。master ip为10.10.1.1, port为29501。不同节点之间通过该端口进行通信。
请注意,为了使得每次跑得结果类似,本文中设置了PyTorch和Numpy的随机数,从而使得每次的结果相同,方便比较。
单机训练VGG11模型
首先,我们先来在单一节点上训练VGG模型以作为对比,数据集为Cifar10。代码在此:单机训练VGG模型
接下来,我们主要关注train_model函数的写法,这个函数用于训练模型。通过更改这个函数的内容,我们可以实现分布式模型训练。
训练包括三步,根据输入数据得出输出数据,将输出与真值对比以计算loss,根据loss更新权值。请注意,在单机上batch_size=256。
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
# 获取数据
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
# 计算loss
train_loss = criterion(output, target)
# 更新权值
train_loss.backward()
optimizer.step()
多节点训练VGG11模型:总述
接下来,将在多节点进行训练。PyTorch多节点训练可参考PyTorch分布式官方文档和写PyTorch分布式程序。
第一步,首先运行 torch.distributed.is_available() 以确保安装了相对应的package。
接下来, 对于多节点训练,首先需要初始化多节点进程init_process_group.
这需要3个参数, backend是不同的通讯方式,在本文中,我们将使用gloo进行后端通讯。rank, world_size代表了本机的级别和节点数,因为我们是四个节点的cluster,所以rank分别为0,1,2,3,其中master设置为0, world_size设置为4.
代码如下:
def init_process(master_ip, rank, size, vgg_model, backend='gloo'):
""" 初始化环境 """
os.environ['MASTER_ADDR'] = master_ip
os.environ['MASTER_PORT'] = '29501'
dist.init_process_group(backend, rank=rank, world_size=size)
# 跑模型
vgg_model(rank, size)
可以看到,首先设置了master节点的ip和port,之后初始化了process group。
接下来,我们需要将数据集分成四份(data partition),并分别发送到四台机器上。
具体的方法是使用DistributedSampler, 并将data_loader中的sampler改成所对应的DistributedSampler:
from torch.utils.data.distributed import DistributedSampler
sampler_d = DistributedSampler(training_set) if torch.distributed.is_available() else None
train_loader = torch.utils.data.DataLoader(training_set, num_workers=2, batch_size=batch_size, sampler=sampler_d, pin_memory=True)
之后就可以跑模型了。
请注意,要想在各个节点都跑起来模型,需要将代码、数据等在每一个机子上都有一份,其内容可以有略微不同,例如,在node0的代码需要设置为rank=0,node1的代码需要设置为rank=1, 以此类推。接下来会对此进行详细解说。
此外,在运行时,需要将所有的代码在所有的节点运行之后,整个训练才会开始。例如,如果world_size=4,也就是四个节点,那么需要分别在四个机子上执行代码,当第四个机子的代码执行后,全部训练才会开始。
多节点训练VGG11模型:使用scatter和gather
接下来就进入正题,如何用不同的方法多节点训练模型。具体而言,我们将分别用多种方法,分布式计算和更新梯度。
首先,因为单机上batch_size=256,而我们现在有4个节点,也就是四台机器,所以我们设置每台机子上的batch_size=256/4=64,这样每一个epoch仍然等价于batch_size=256
接下来,应该新建一个组,以确保通信发生在组内:
group = dist.new_group([0, 1, 2, 3])
分布式实现训练的思路如下,我们将数据分成四份并分别发送到不同的机子上,接下来,在每一台机子上,根据输入数据得出输出数据,将输出与真值对比以计算loss,以上两步与单机版的思路基本相同。接下来,需要将四台机子的parameters梯度发送到master节点,并计算平均值,以获得统一的权值,再发送到各个节点进行更新,这样就能确保所训练的模型在各个机子上相同。
在这里,我们使用scatter和gather来发送和收集信息。其中,scatter可以将信息从master节点传到所有的其他节点,gather可以将信息从别的节点获取到master节点。

用法如下:
# master node
var_list = [torch.zeros_like(var) for _ in range(4)]
dist.gather(var, var_list, group=group, async_op=False)
# slave node
dist.gather(var, group=group, async_op=False)
对于gather, 首先需要在master node新建一个空的list来存储tensor,如果有4个节点则list长度为4,分别存储rank 0, 1, 2, 3节点的这个变量的值。
接下来,dist.gather()第一个参数指明了需要获取的每个节点的具体变量名。
而slave node只需要将tensor传出即可,不需要新建list存储tensor。
以上这个例子就是在master node用var_list这个list分别收集了node 0~3每个节点var的值。
# master node
var_list = [var for _ in range(4)]
dist.scatter(var, var_list, group=group, src=0, async_op=False)
# slave node
dist.scatter(var, group=group, src=0, async_op=False)
对于scatter, 首先需要在master node新建一个list来存储tensor,如果有4个节点则list长度为4,分别存储需要发送到rank 0, 1, 2, 3节点的变量。
接下来,dist.scatter()第一个参数指明了每个节点接收数据的具体变量名。
而slave node只需要将tensor接收即可,接收的变量为var。
以上这个例子就是在master node用var_list这个list分别复制了四个var,再分别发送到了所有node 0~3.
接下来我们看具体的代码。对于vgg11模型训练而言,我们首先将四个节点的梯度发送到master节点,求平均值后再分别发送到四个节点。
故master代码和其他node的代码不同。代码在此:scatter, gather on master node, scatter, gather on other nodes
具体代码master(node0)如下:
# 新建组
group = dist.new_group([0, 1, 2, 3])
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
train_loss = criterion(output, target)
train_loss.backward()
# 以上均和单机版代码相同。接下来遍历本机模型的parameters,并采集其他节点的grad梯度,计算平均值并发送到其他节点
for p in model.parameters():
# 新建一个list存储各个节点的梯度
grad_list = [torch.zeros_like(p.grad) for _ in range(4)]
# 获取所有节点的梯度
dist.gather(p.grad, grad_list, group=group, async_op=False)
# 计算所有节点的平均梯度
grad_sum = torch.zeros_like(p.grad)
for i in range(4):
grad_sum += grad_list[i]
grad_mean = grad_sum / 4
# 新建一个list存储将要发到各个节点的平均梯度
scatter_list = [grad_mean for _ in range(4)]
# 将所有的值发送到各个节点
dist.scatter(p.grad, scatter_list, group=group, src=0, async_op=False)
optimizer.step()
简单而言,master node首先获取了所有节点的梯度并计算了平均值,接下来将该平均值分发到了各个slave nodes。
具体代码slave(node1~3)如下:
# 新建组
group = dist.new_group([0, 1, 2, 3])
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
train_loss = criterion(output, target)
train_loss.backward()
# 以上均和单机版代码相同。接下来遍历本机模型的parameters,并获取grad梯度,发送到master node,并从master node获取平均值后更新grad
for p in model.parameters():
# 将grad值发送到master node
dist.gather(p.grad, group=group, async_op=False)
# 接收master node发送过来的grad值
dist.scatter(p.grad, group=group, src=0, async_op=False)
optimizer.step()
slave node首先将该节点的梯度发送到了master node, 之后接收了master node计算的梯度平均值.
多节点训练VGG11模型:使用isend和irecv
除了scatter和gather, 另一种方法是使用isend和irecv。
isend和irecv属于点对点通讯,可以指定发送和接收的目标。因此,不需要新建组。
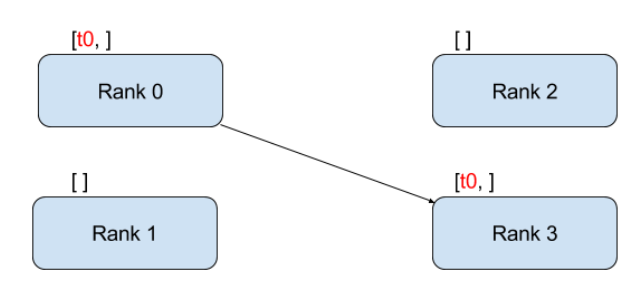
具体思路仍然是将四台机子的parameters梯度发送到master节点,并计算平均值,获得统一的梯度,再从master node发送到各个节点进行更新.
isend可以将信息从一个节点传到另一个节点,同时对应的另一个节点需要使用irecv进行接收。
用法如下:
req = dist.isend(tensor=var, dst=rank)
req.wait()
req = dist.irecv(tensor=var, src=rank)
req.wait()
isend和irecv的第一个参数即为需要传输和需要接收的变量名var。对于isend,dst指定了发送时的目标(rank),而对于irecv,src指定了接受时数据的来源(rank)。
在发送和接收后,需要req.wait()以确保目标或者来源机器已经收到或者已经发送了数据,以确保各个机器同步。
接下来我们看具体的代码。对于vgg11模型训练而言,我们首先将四个节点的梯度发送到master节点,求平均值后再分别发送到四个节点。
故master代码和其他node的代码不同。代码在此:isend, irecv on master node, isend, irecv on other nodes
具体代码master(node0)如下:
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
train_loss = criterion(output, target)
train_loss.backward()
# 以上均和单机版代码相同。接下来遍历本机模型的parameters,并采集其他节点的grad梯度,计算平均值并发送到其他节点
for p in model.parameters():
# 采集其他节点的grad梯度
grad_1 = torch.zeros_like(p.grad)
grad_2 = torch.zeros_like(p.grad)
grad_3 = torch.zeros_like(p.grad)
req = dist.irecv(tensor=grad_1, src=1)
req.wait()
req = dist.irecv(tensor=grad_2, src=2)
req.wait()
req = dist.irecv(tensor=grad_3, src=3)
req.wait()
# 计算所有节点的梯度平均值
grad_mean = (p.grad + grad_1 + grad_2 + grad_3)/4
p.grad = grad_mean
# 将梯度平均值发送到其他节点
req = dist.isend(tensor=grad_mean, dst=1)
req.wait()
req = dist.isend(tensor=grad_mean, dst=2)
req.wait()
req = dist.isend(tensor=grad_mean, dst=3)
req.wait()
optimizer.step()
具体代码slave(node1~3)如下:
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
train_loss = criterion(output, target)
train_loss.backward()
# 以上均和单机版代码相同。接下来遍历本机模型的parameters,并获取grad梯度,发送到master node,并从master node获取平均值后更新grad
for p in model.parameters():
# 将本机的梯度发送到master node
req = dist.isend(tensor=p.grad, dst=0)
req.wait()
# 从master node接收平均梯度
req = dist.irecv(tensor=p.grad, src=0)
req.wait()
optimizer.step()
多节点训练VGG11模型:使用all_reduce
以上方法虽然完成了不同节点之间的通讯,但由于master node和其他node之间代码不同,所以仍然比较麻烦。PyTorch提供了一种简便且高效的方法。具体而言就是all_reduce函数,该函数使用了ring通讯方法,使得通讯效率得到了提升。同时,也完成了组内变量的共享和计算。
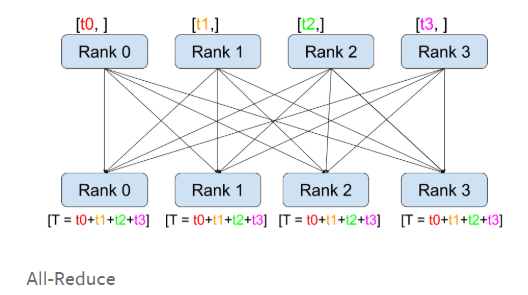
用法如下:
dist.all_reduce(var, op=dist.reduce_op.SUM, group=group, async_op=False)
与gather(), scatter()相似,首先需要建立一个组。all_reduce()第一个参数为需要进行运算的变量,第二个参数op则包含了一些方法,例如求和SUM,此外还有MIN, MAX等,可参见这里.
所以以上代码的意思是计算组内所有节点var变量的总和,且返回该var.
具体思路仍然是将四台机子的parameters梯度发送到master节点,并计算平均值,获得统一的梯度,再从master node发送到各个节点进行更新.
isend可以将信息从一个节点传到另一个节点,同时对应的另一个节点需要使用irecv进行接收。
req = dist.isend(tensor=var, dst=rank)
req.wait()
req = dist.irecv(tensor=var, src=rank)
req.wait()
接下来我们看具体的代码。对于vgg11模型训练而言,我们首先将四个节点的梯度分布除以4,再全部相加,即可获得平均梯度值。在这里,所有机器的代码均相同。代码在此:all_reduce.
具体代码如下:
# 新建组
group = dist.new_group([0, 1, 2, 3])
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
train_loss = criterion(output, target)
train_loss.backward()
# 以上均和单机版代码相同。接下来遍历本机模型的parameters,并计算组内所有机器的梯度平均值
for p in model.parameters():
p.grad = p.grad / 4
dist.all_reduce(p.grad, op=dist.reduce_op.SUM, group=group, async_op=False)
optimizer.step()
多节点训练VGG11模型:使用Distributed Data Parallel
PyTorch还提供了最新的Distributed Data Parallel (DDP) API,通过Gradient Bucketing更高效和方便地实现了以上方法。
在这里,所有机器的代码均相同。代码在此:DDP.
具体用法如下:
from torch.nn.parallel import DistributedDataParallel as DDP
ddp_model = DDP(model)
optimizer = optim.SGD(ddp_model.parameters(), lr=0.1,
momentum=0.9, weight_decay=0.0001)
也就是将model转换为ddp_model,之后即可和单机模型类似进行训练。
以上就是使用多种方法进行PyTorch分布式训练的内容了。所有代码可以参考:GitHub.
同时,本文基于威斯康星大学麦迪逊分校CS744课程作业改编而成,在此感谢Prof.Shivaram Venkataraman. 同时,本项目由饶锦蒙和我共同完成。