作业1
天气预报
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDB:
def openDB(self):
self.con = sqlite3.connect("weathers.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute(
"create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values(?,?,?,?)",
(city, date, weather, temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city", "data", "weather", "temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US;rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + "code cannot be found")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
self.db.insert(city, date, weather, temp)
except Exception as err:
# 这边会抛出一个list index out of range的异常,结果还是可以正常输出
pass
# print(err)
except Exception as err:
print(err)
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
self.db.show()
self.db.closeDB()
ws = WeatherForecast()
ws.process(["北京", "上海", "广州", "深圳"])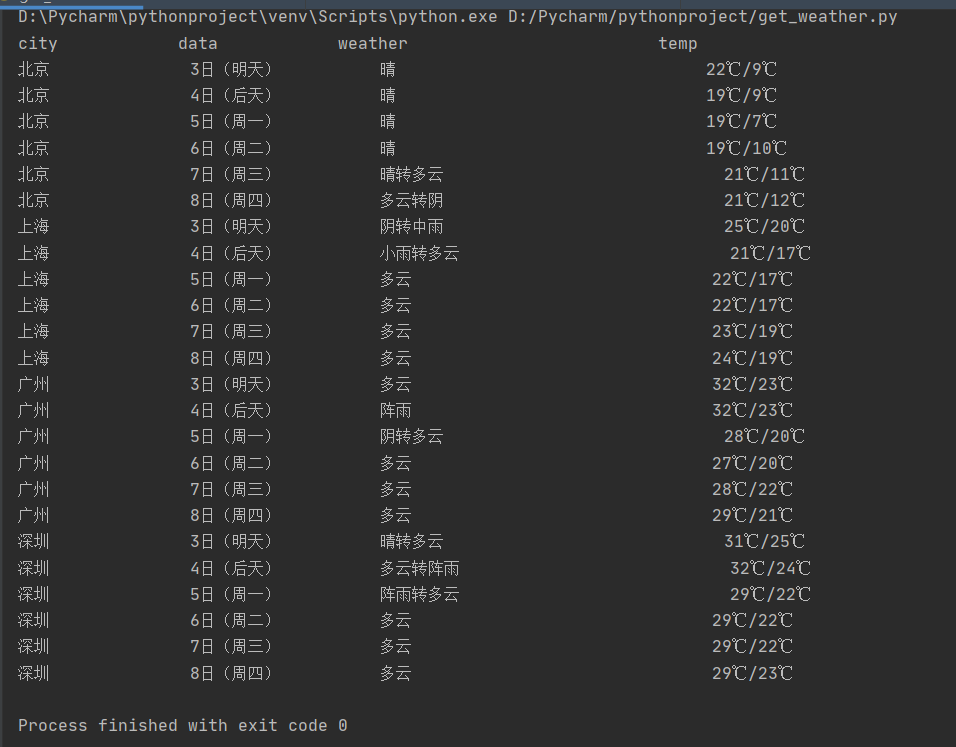
心得体会
这次的实验代码是参考书本的,大致能理解函数的调用以及各种参数的作用,但是实际操作时会抛出书本没有出现的异常,努力解决这个问题中。。。
作业2
股票信息
import requests
import re
def get_html(url):
r = requests.get(url)
r.encoding = r.apparent_encoding
data = re.findall(r'"diff":[(.*?)]', r.text)
return data
# 将股票信息输入一个列表中
def get_stock(data):
# 将data中的不同股票的信息划分开来
datas = data[0].strip('{').strip('}').split('},{')
# 创建一个空表来存储股票信息
stocks = []
for i in range(len(datas)):
# 将每支股票的不同信息划分开来
stock = datas[i].replace('"', "").split(",")
stocks.append(stock)
return stocks
# 对列表中的股票信息进行处理,方便输出
def data_dispose(stock_info):
# 创建一个二维列表来存储每一支股票的不同信息
arrays = [[0 for i in range(12)] for j in range(len(stock_info))]
for i in range(len(stock_info)):
for j in range(len(stock_info[i])):
# 此时的数据格式是"f_:__",利用冒号进行分隔,取第二个数据
array = stock_info[i][j].split(":")
arrays[i][j] = array[1]
return arrays
# 输出股票信息
def stock_list(arrays):
template = "{0:^5} {1:^9} {2:^8} {3:^9} {4:^7} {5:^7} {6:^8} {7:^13} {8:^6} {9:^9} {10:^9} {11:^9} {12:^9}"
print(template.format('序号', '代码', '名称', '最新价', '涨跌幅', '跌涨额', '成交量', '成交额', '涨幅', '最高', '最低', '今开', '昨收'))
count = 0
for i in range(0, len(arrays)):
count = count + 1
# 此时数组的数据顺序为{'最新价', '涨跌幅', '跌涨额', '成交量', '成交额', '涨幅','代码', '名称', '最高', '最低', '今开', '昨收'}
print(template.format(count, arrays[i][6], arrays[i][7], arrays[i][0], arrays[i][1], arrays[i][2],
arrays[i][3], arrays[i][4], arrays[i][5], arrays[i][8], arrays[i][9],
arrays[i][10], arrays[i][11]))
def main():
# page代表页数
page = 4
# f12:代码,f14:名称,f2:最新价,f3:涨跌幅,f4:跌涨额,f5:成交量,f6:成交额,f7:涨幅,f15:最高,f16:最低,f17:今开,f18:昨收
url = "http://36.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124023699367386040748_1601445755722&pn=" + str(
page) + "&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:1+t:2,m:1+t:23&fields=f12,f14,f2,f3,f4,f5,f6,f7,f15,f16,f17,f18&_=1601445756033"
html = get_html(url)
stock_info = get_stock(html)
arrays = data_dispose(stock_info)
stock_list(arrays)
if __name__ == '__main__':
main()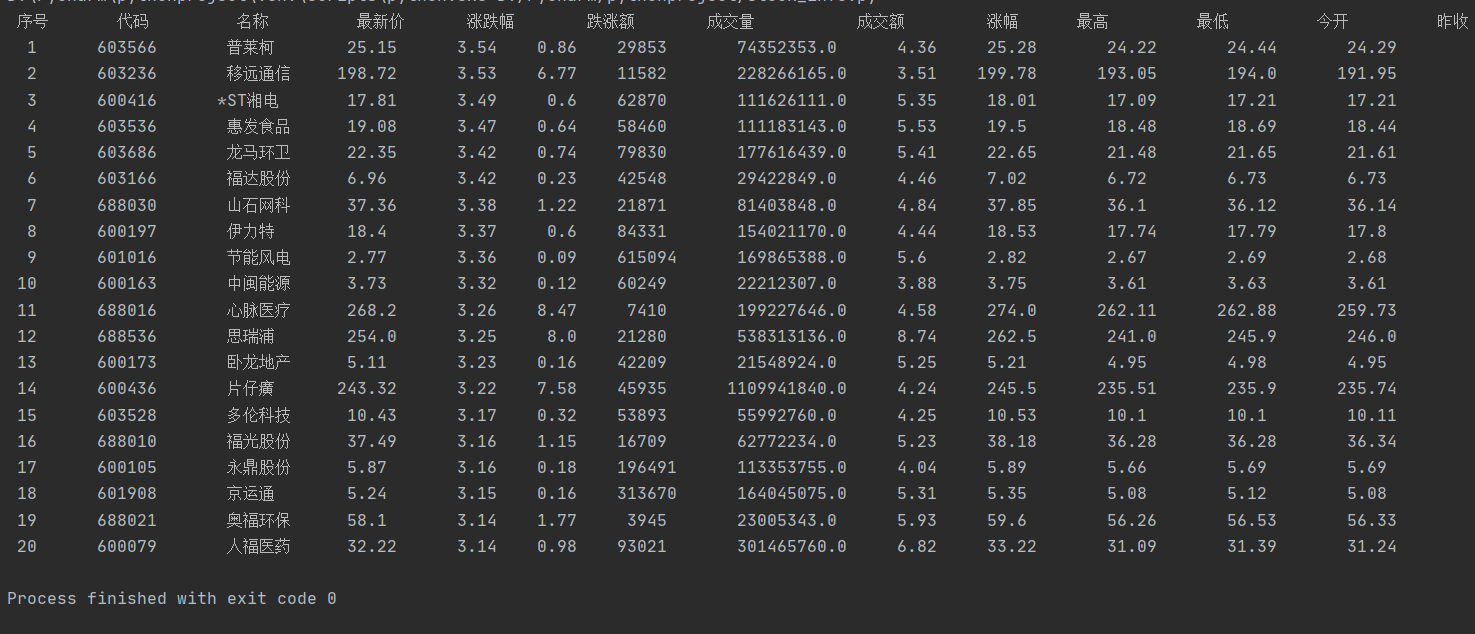
心得体会
这次实验与以往实验最大不同就是这次爬取的网页数据是实时刷新的,在网页源代码中抓取不到数据,这时就需要在股票网页界面进入F12调试模式进行抓包,查找股票列表加载使用的url,通过对比网页上的数据确定参数所代表的意义,然后就能按照同样的方法获取到股票信息了。
作业3
特定股票信息
import requests
import re
from prettytable import PrettyTable
def get_html(url):
r = requests.get(url)
r.encoding = r.apparent_encoding
data = re.findall(r'"data":{(.*?)}', r.text)
return data
# 将股票信息输入一个列表中
def get_stock(data):
datas = data[0].replace('"', "").split(',')
# 创建一个空表来存储股票信息
stock_info = []
for data in datas:
# 此时的数据格式是"f_:__",利用冒号进行分隔,取第二个数据
array = data.split(':')
stock_info.append(array[1])
return stock_info
# 打印出股票信息
def stock_list(info_list):
# 采用pretttable的方法显示股票信息
x = PrettyTable(["代码", "名称", "今开", "今日最高", "今日最低"])
x.add_row([info_list[3], info_list[4], info_list[2], info_list[0], info_list[1]])
print(x)
def main():
# stock_code代表所选取的股票代码
stock_code = 600119
# f44:今日最高,f45:今日最低,f45:今开,f57:股票代码,f58:股票名称
url = "http://push2.eastmoney.com/api/qt/stock/get?ut=fa5fd1943c7b386f172d6893dbfba10b&invt=2&fltt=2&fields=f46,f44,f45,f57,f58&secid=1."+str(stock_code)+"&cb=jQuery112403234351520302483_1601639886921&_=1601639886943"
data = get_html(url)
stock_info = get_stock(data)
stock_list(stock_info)
if __name__ == '__main__':
main()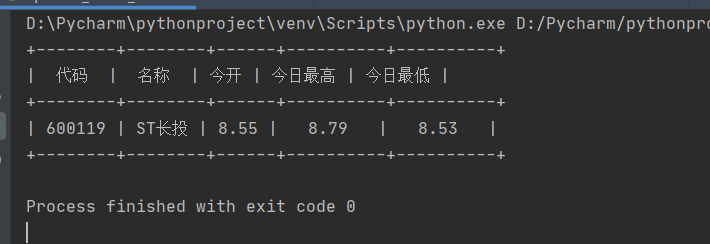
心得体会
这次的实验和上一个实验差不多,个人认为难点在于url的选取,因为是自定义查找股票,而不同版面的股票的url可能格式上有所差异,举个例子,将我代码中的url的stock_code(600119)替换成600118是可以运行的,可是当替换成300119就会发现报错,根据url访问页面时发现"data"=null,所以在爬取不同版面的股票信息要重新定义url格式。