- 0. paper link
- 1. Overview
- 2. Four General Design Principles
- 3. Factorizing Convolutions with Large Filter Size
- 4. Utility of Auxiliary Classifiers
- 5. Efficient Grid Size Reduction
- 6. Inception-v2
- 7. Model Regularization via Label Smoothing
- 8. Training Methodology
- 9. Performance on Lower Resolution Input
- 10. Experiment
0. paper link
1. Overview
这篇文章很多“经验”性的东西,因此会写的比较细,把文章里的一些话摘取出来,多学习一下,希望对以后自己设计网络有帮助。
2. Four General Design Principles
这里文章介绍了四种设计网络设计原则,这是作者利用各种卷积网络结构,通过大量的实验推测的。
- 避免特征表示瓶颈,尤其是在网络的前面。要避免严重压缩导致(pooling,卷积等操作)的瓶颈。特征表示尺寸应该温和的减少,从输入端到输出端。特征表示的维度只是一个粗浅的信息量表示,它丢掉了一些重要的因素如相关性结构
- 高维的信息(representations)更适合在网络的局部处理。在卷积网络中逐步增加非线性激活响应可以解耦合更多的特征(独立更多特征),那么网络就会训练的更快。
- 空间聚合可以在较低维度嵌入上完成,而不会在表示能力上造成许多或任何损失。例如,在执行更多展开(例如3×3)卷积之前,可以在空间聚合之前减小输入表示的维度,没有预期的严重不利影响。我们假设,如果在空间聚合上下文中使用输出,则相邻单元之间的强相关性会导致维度缩减期间的信息损失少得多。鉴于这些信号应该易于压缩,因此尺寸减小甚至会促进更快的学习(inception-v1中提出的用1x1卷积先降维再作特征提取就是利用这点。不同维度的信息有相关性,降维可以理解成一种无损或低损压缩,即使维度降低了,仍然可以利用相关性恢复出原有的信息。)
- 平衡好网络的深度和宽度。通过平衡网络每层滤波器的个数和网络的层数可以是网络达到最佳性能。增加网络的宽度和深度都会提升网络的性能,但是两者并行增加获得的性能提升是最大的。
3. Factorizing Convolutions with Large Filter Size
这里作者开始 Factorizing Convolutions,GoogLeNet 网络优异的性能主要源于大量使用降维处理。这种降维处理可以看做通过分解卷积来加快计算速度的手段。在一个计算机视觉网络中,相邻激活响应的输出是高度相关的,所以在聚合前降低这些激活影响数目不会降低局部表示能力。因此可以利用这些省下来的计算跟存储资源来增加卷积核的尺寸同时保持可以在一台电脑训练每一个模型的能力。
3.1 Factorization into smaller convolutions
大的空间滤波器虽然可以在更前面的层有更大的感受野,获得更远的单元激活之间,信号之间的依赖关系,但是在计算量方面很大。
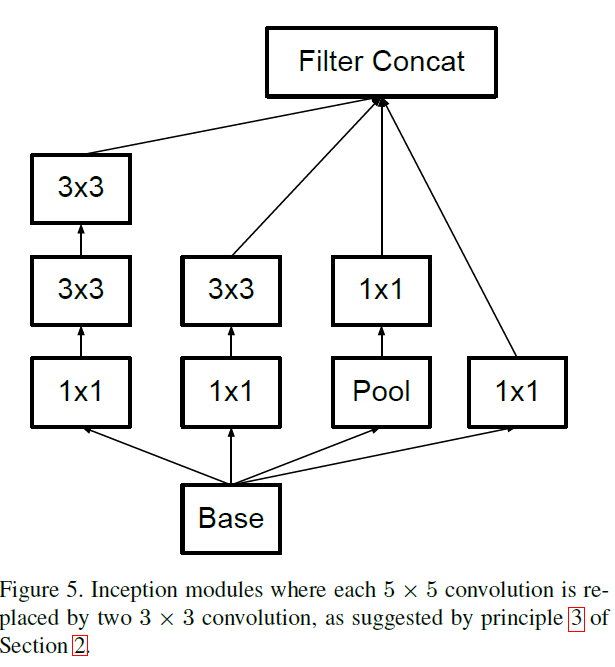
如果放大5×5卷积的计算图,我们看到每个输出看起来像一个小的完全连接的网络,在其输入上滑过5×5的块(见图1)。由于我们正在构建视觉网络,所以通过两层的卷积结构再次利用平移不变性来代替全连接的组件似乎是很自然的:第一层是3×3卷积,第二层是在第一层的3×3输出网格之上的一个全连接层(下图)。通过在输入激活网格上滑动这个小网络,用两层3×3卷积来替换5×5卷积,同时都用RELU激活得到的性能比较好。

3.2. Spatial Factorization into Asymmetric Convolutions
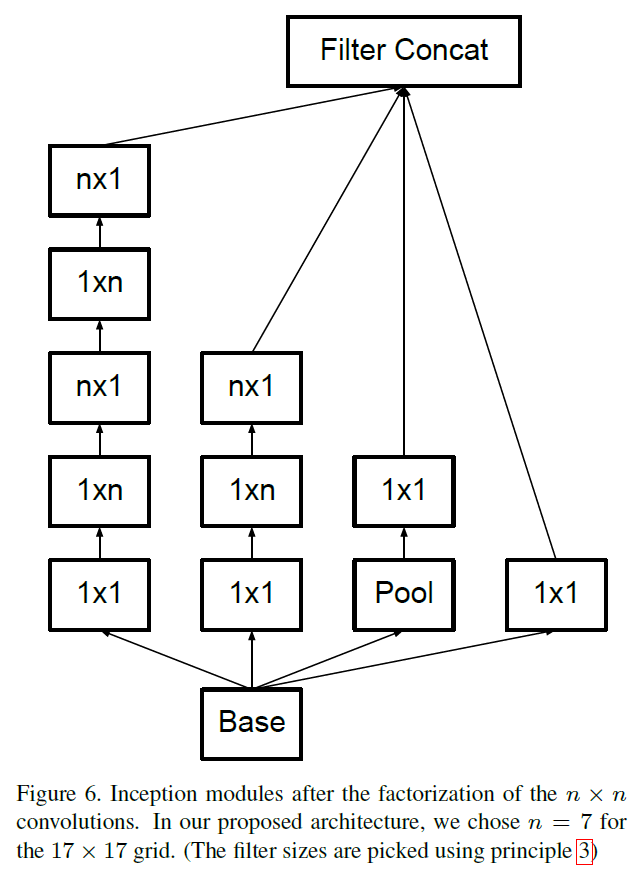
文章提到大于3x3的卷积核可能不是一直有用的,因为他总可以变成几个3x3的卷积核, 那么是不是可以把3x3分解成更小的?文章提出了非对称卷积: nx1 后面 接一个 1xn, 可以减少比2x2更少的计算量,而且随着n上升,计算成本节省显著增加。下图是把3x3的变成3x1 + 1x3.
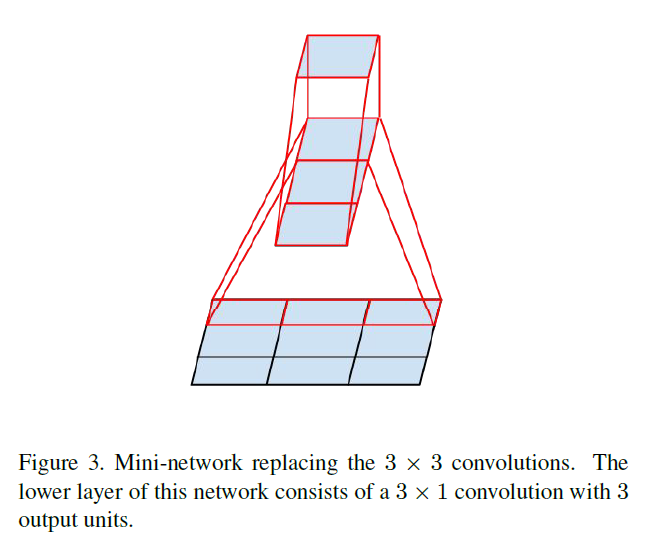
但是实际上,作者发现采用这种分解在前面的层次上不能很好地工作,但是对于中等网格尺寸(在m×m特征图上,其中m范围在12到20之间),其给出了非常好的结果。在这个水平上,通过使用1×7卷积,然后是7×1卷积可以获得非常好的结果。
4. Utility of Auxiliary Classifiers
GoogLeNet-v1引入辅助分类器为了防止梯度消失加快收敛用的,作者通过实验发现辅助分类器在训练前期没什么用,后期会比没有分类器得高一点。最下面的辅助分类器去掉也没什么影响,作者猜测辅助分类器主要用来增强模型正则化,因为辅助分类器加上BN层以及dropout也会增强主分类器性能。
5. Efficient Grid Size Reduction
为了避免第一条准则中提到的计算瓶颈所造成的的信息损失,一般会通过增加滤波器的数量来保持表达能力,但是计算量会增加,如下图:

作者提出了一种并行的结构,使用两个并行的步长为2的模块,P 和 C。P是一个池化层,C是一个卷积层,然后将两个模型的响应组合到一起:

6. Inception-v2
把7x7卷积替换为3个3x3卷积。包含3个Inception部分。第一部分是35x35x288,使用了2个3x3卷积代替了传统的5x5;第二部分减小了feature map,增多了filters,为17x17x768,使用了nx1->1xn结构;第三部分增多了filter,使用了卷积池化并行结构。网络有42层,但是计算量只有GoogLeNet的2.5倍,另外inception-v3是加上了辅助分类器,并且辅助分类器也加入了BN层。具体参数如下图:
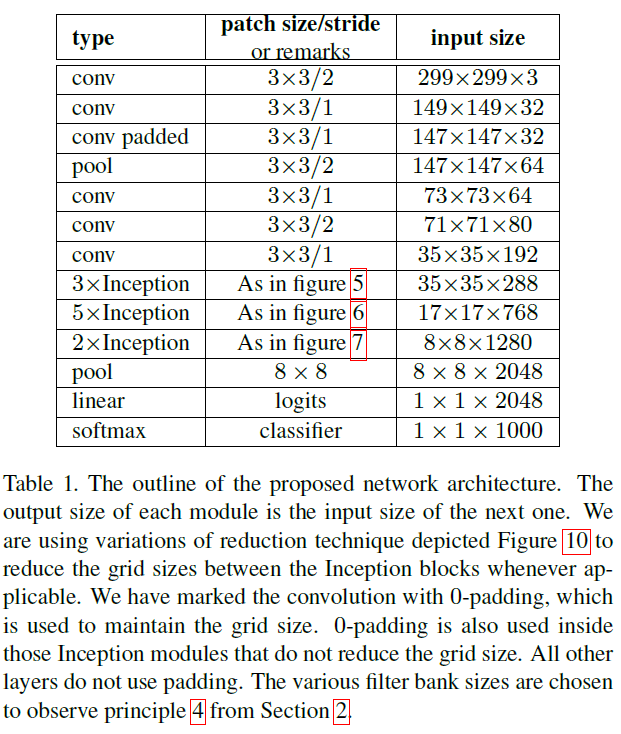
图5.6.7如下图

7. Model Regularization via Label Smoothing
这里作者写了一个新的loss,其实也不难理解,但不想敲latex了,copy一下翻译

8. Training Methodology
TensorFlow 。
batch-size=32,epoch=100。SGD+momentum,momentum=0.9。
RMSProp,decay=0.9,ϵ=0.1。
lr=0.045,每2个epoch,衰减0.94。
梯度最大阈值=2.0。
9. Performance on Lower Resolution Input
对于低分辨率的图像,一个比较方法是使用更高分辨率的感受野,如果我们仅仅改变输入的分辨率而不改模型性能会比较低。

299x299:步长为2,然后接max pooling
151x151:步长为1,然后接max pooling
79x79:步长为1,没有接max pooling
三者的参数是相同的,但感受野不同,最终的结果表明感受野越大,效果越好,但是差别不大。但是,如果单纯的根据输入分辨率减少网络的大小,则最终的效果要差很多。
10. Experiment
实验结果如下:


