看到一段对主题模型的总结,感觉很精辟:
如何找到文本隐含的主题呢?常用的方法一般都是基于统计学的生成方法。即假设以一定的概率选择了一个主题,然后以一定的概率选择当前主题的词。最后这些词组成了我们当前的文本。所有词的统计概率分布可以从语料库获得,具体如何以“一定的概率选择”,这就是各种具体的主题模型算法的任务了。lda也是采取的这种思想。
大部分对LDA的解释都是通过LDA生成文档的思路,而我们一般是给定文档,利用LDA推测该文档的话题分布。我在这里先讲一下生成文档的过程,再讲我们普遍用到的代码中推测话题的过程:
1.文档生成
我比较关注实用性,又不是很喜欢那么多的数学公式,所以主要先把个人感觉最方便理解的解释分享给大家看看~反正我看了下边的解释脑子里可以有LDA原理的整个思路。
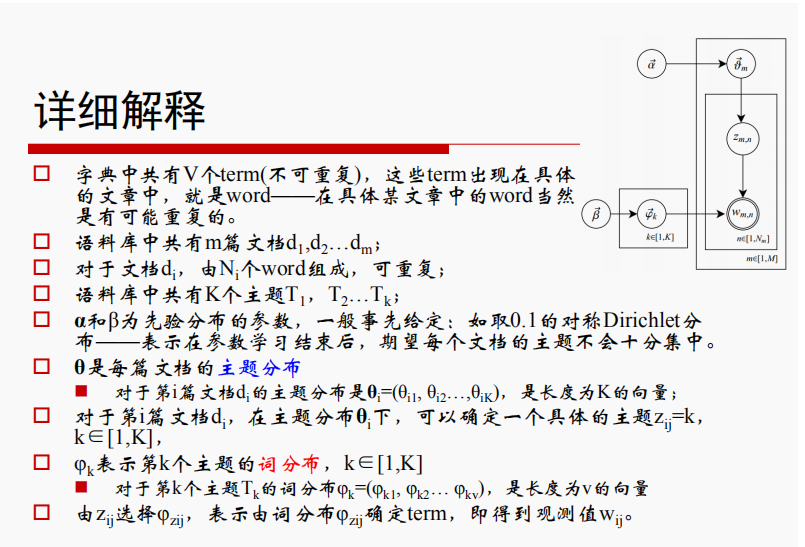
联系右上角给出的图,步骤为从上到下、从左到右,先得到一个主题Zij=k,再得到第k个主题的词分布φk,继而生成文档的词汇w,循环该图流程,生成整篇文档。
过程中涉及到多种分布;
共轭分布:在贝叶斯的理论体系中,如果先验概率分布和后验概率分布满足同样的分布律的话,就说先验分布和后验分布是共轭分布,同时,先验分布又叫做似然函数的共轭先验分布。大白话来说就是:如果一个概率分布Z乘以一个分布Y之后的分布仍然是Z,那么就是共轭分布。二项分布的共轭先验分布是Beta分布,多项分布的共轭先验分布是Dirichlet分布。
LDA中涉及的 多项分布和Dirichlet分布,LDA中词和主题服从多项式分布,两者的参数服从Dirichlet分布。我认为引入共轭分布主要是为了方便计算整个过程中的参数。
2.通过已知文档推测所含话题分布
通过LDA推测话题分布时,
1)初始先随机给文本中的每个词(喂进去的词需要经过分词、通过dictionary每个词对应一个id,再将id与该词对应的tf-idf值或词频关联存储为一个矩阵)分配主题z0(初始设置了要得到的话题个数k,为每个词分配话题id),也给定了α和β,控制了主题分布和词分布;
2)然后统计词t属于主题z的数量以及每个文档m下出现的主题z的数量;通过除了当前词w以外其他所有词所属的主题分布估计当前词分配各个主题的概率,即计算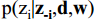 得到词w对应各主题的概率p(1,2,....k)=(p1,p2,.....pk)
得到词w对应各主题的概率p(1,2,....k)=(p1,p2,.....pk)
3)当得到当前词属于所有主题z的概率分布后,根据这个概率分布为该词采样(不是取最大值)一个新的主题。
4)用同样方法更新下一个词的主题,直到发现每个文档的主题分布和每个主题的词分布收敛(应该是文档中出现的所有同一个词计算得到的所属主题分布都一致),算法终止,输出待估计的参数θ和φ,同时每个单词的主题Zmn也可以得到。
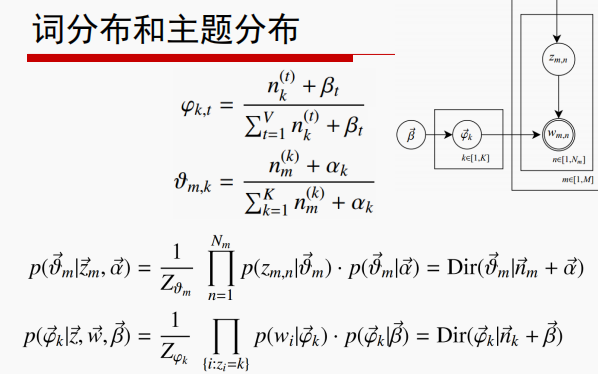
实际中应用会设置最大迭代次数,每一次计算 的公式称为Gibbs updating rule
的公式称为Gibbs updating rule
这样就解释了内部推测话题的过程。其中涉及的数学计算过程如下(我比较懒,直接贴了邹博视频的式子啦,如果对大家有用希望能点个赞之类的啦~~~~~~~~~):



另外,想起来在用LDA做实验的过程中还找到了百度开源的一个项目。关于主题模型的项目。文档主题推断工具、语义匹配计算工具以及基于工业级语料训练的三种主题模型:Latent Dirichlet Allocation(LDA)、SentenceLDA 和Topical Word Embedding(TWE) github链接:https://github.com/baidu/Familia
3.通过gensim中LDA可以实现的功能
1)得到该文档的话题分布及相应概率
2)计算各文档相似度
dictionary = corpora.Dictionary.load('dictionary.dict')
corpus = corpora.MmCorpus("corpus.mm")
lda = models.LdaModel.load("model.lda")
index = similarities.MatrixSimilarity(lda[corpus])
index.save("simIndex.index")
docname = "docs/the_doc.txt" doc = open(docname, 'r').read()
vec_bow = dictionary.doc2bow(doc.lower().split())
vec_lda = lda[vec_bow] sims = index[vec_lda]
sims = sorted(enumerate(sims), key=lambda item: -item[1])
参考链接:https://blog.csdn.net/qq_25073545/article/details/79782066
3)通过PYLDAVIS模块将主题可视化
试了一下该项目是可以直接用的,只不过只能在LINUX下使用,可以直接按github上给出的步骤应用,效果还不错~~~