今天和大家说说C++多线程中的原子操作。首先为什么会有原子操作呢?这纯粹就是C++这门语言的特性所决定的,C++这门语言是为性能而生的,它对性能的追求是没有极限的,它总是想尽一切办法提高性能。互斥锁是可以实现数据的同步,但同时是以牺牲性能为代价的。口说无凭,我们做个实验就知道了。
我们将一个数加一再减一,循环一定的次数,开启20个线程来观察,这个正确的结果应该是等于0的。
首先是不加任何互斥锁同步
#include <iostream> #include <thread> #include <atomic> #include <time.h> #include <mutex> using namespace std; #define MAX 100000 #define THREAD_COUNT 20 int total = 0; void thread_task() { for (int i = 0; i < MAX; i++) { total += 1; total -= 1; } } int main() { clock_t start = clock(); thread t[THREAD_COUNT]; for (int i = 0; i < THREAD_COUNT; ++i) { t[i] = thread(thread_task); } for (int i = 0; i < THREAD_COUNT; ++i) { t[i].join(); } clock_t finish = clock(); cout << "result:" << total << endl; cout << "duration:" << finish - start << "ms" << endl; return 0; }
以上程序运行时相关快的,但是结果却是不正确的。
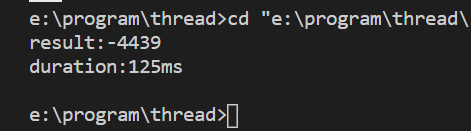
那么我们将线程加上互斥锁mutex再来看看。
#include <iostream> #include <thread> #include <atomic> #include <time.h> #include <mutex> using namespace std; #define MAX 100000 #define THREAD_COUNT 20 int total = 0; mutex mt; void thread_task() { for (int i = 0; i < MAX; i++) { mt.lock(); total += 1; total -= 1; mt.unlock(); } } int main() { clock_t start = clock(); thread t[THREAD_COUNT]; for (int i = 0; i < THREAD_COUNT; ++i) { t[i] = thread(thread_task); } for (int i = 0; i < THREAD_COUNT; ++i) { t[i].join(); } clock_t finish = clock(); // 输出结果 cout << "result:" << total << endl; cout << "duration:" << finish - start << "ms" << endl; return 0; }
我们可以看到运行结果是正确的,但是时间比原来慢太多了。虽然很无奈,但这也是没有办法的,因为只有在保证准确的前提才能去追求性能。

那有没有什么办法在保证准确的同时,又能提高性能呢?
原子操作就横空出世了!
定义原子操作的时候必须引入头文件
#include <atomic>
那么如何利用原子操作提交计算的性能呢?实际上很简单的。
#include <iostream> #include <thread> #include <atomic> #include <time.h> #include <mutex> using namespace std; #define MAX 100000 #define THREAD_COUNT 20 //原子操作 atomic_int total(0); void thread_task() { for (int i = 0; i < MAX; i++) { total += 1; total -= 1; } } int main() { clock_t start = clock(); thread t[THREAD_COUNT]; for (int i = 0; i < THREAD_COUNT; ++i) { t[i] = thread(thread_task); } for (int i = 0; i < THREAD_COUNT; ++i) { t[i].join(); } clock_t finish = clock(); // 输出结果 cout << "result:" << total << endl; cout << "duration:" << finish - start << "ms" << endl; return 0; }
可以看到,我们在这里只需要定义atomic_int total(0)就可以实现原子操作了,就不需要互斥锁了。而性能的提升也是非常明显的,这就是原子操作的魅力所在。

更多精彩内容,请关注同名公众:一点月光(alittle-moon)
