讲索引之前让我们先看看一些常见的数据结构
1.hash
概念:是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值
时间复杂度和空间复杂度:O(1)
缺点:hash索引不支持范围查找,不支持排序
优点:时间复杂度低
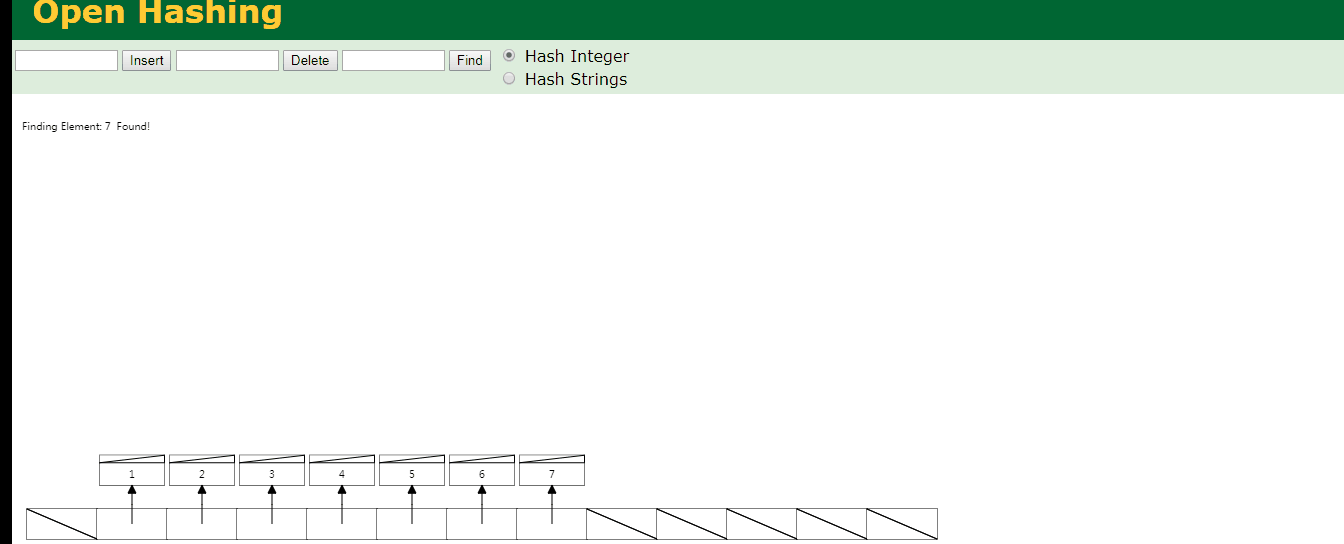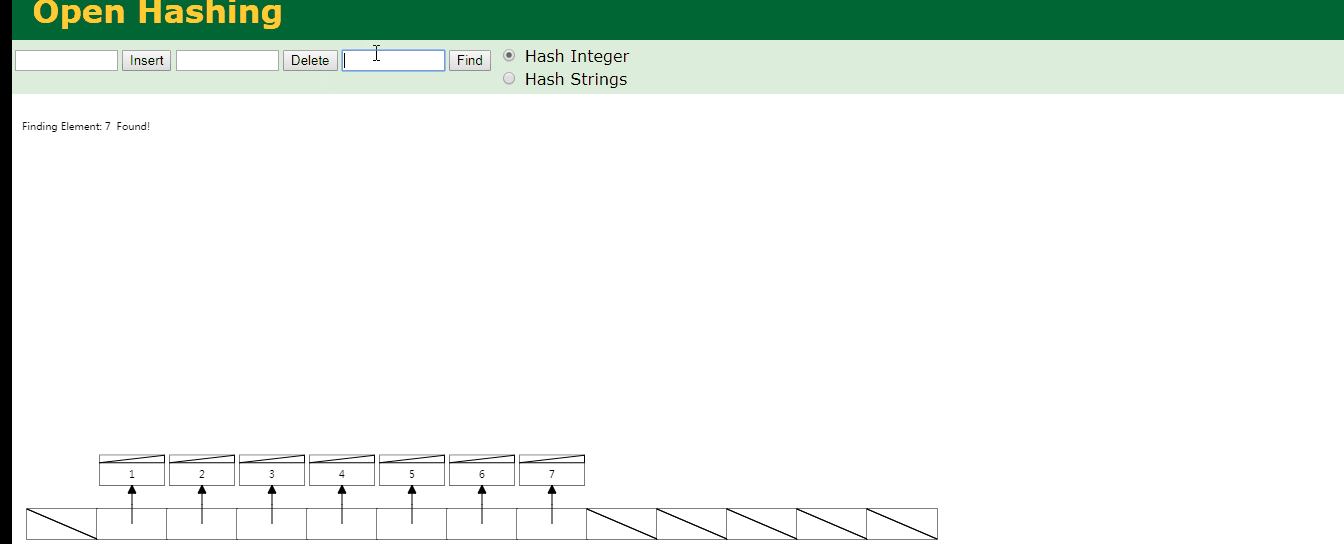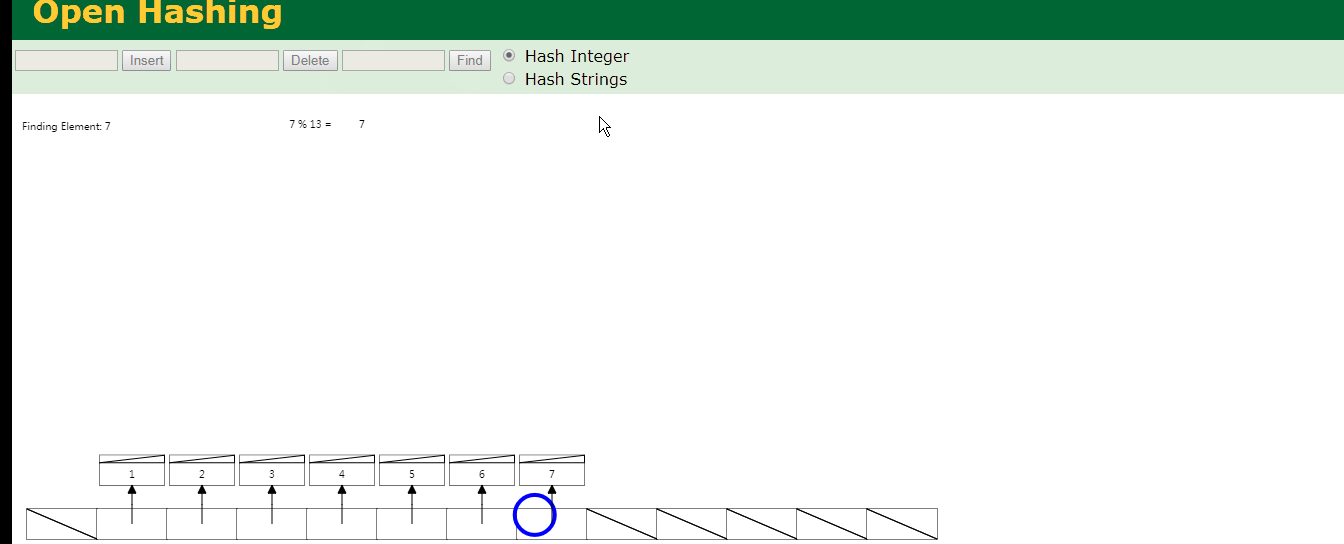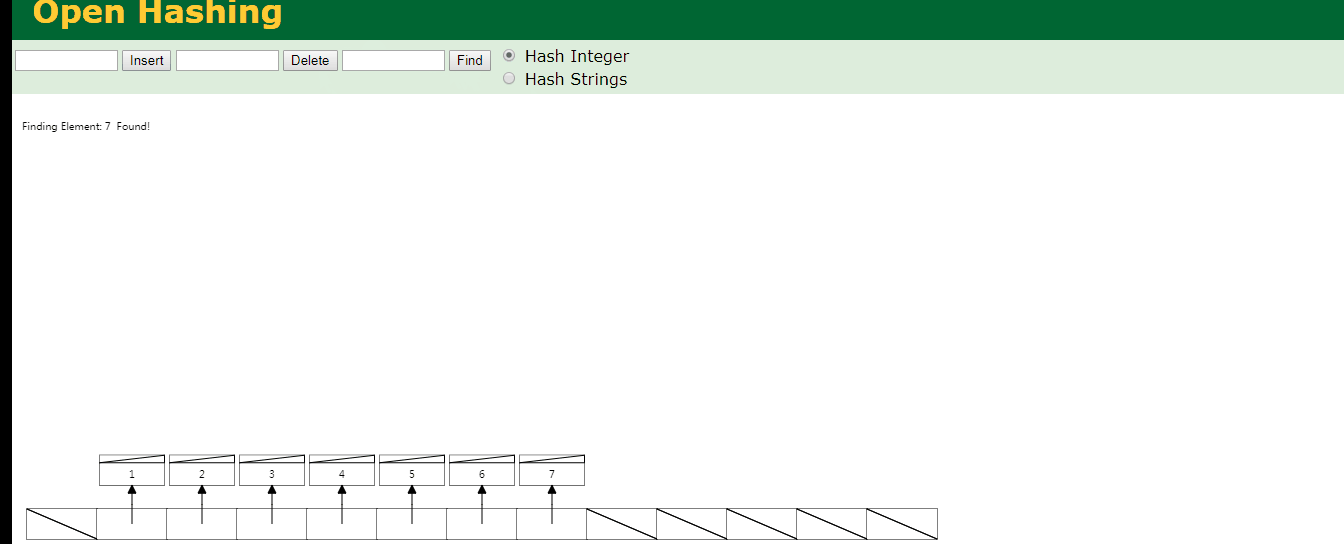
比如现在hash表中有7条数据,要查询id为7的数据只需要一次就能查到,如下图
2.二叉树
特点:左子树都比父节点小,右子树都比父节点大
让我们来看看二叉树的查找
平衡二叉树
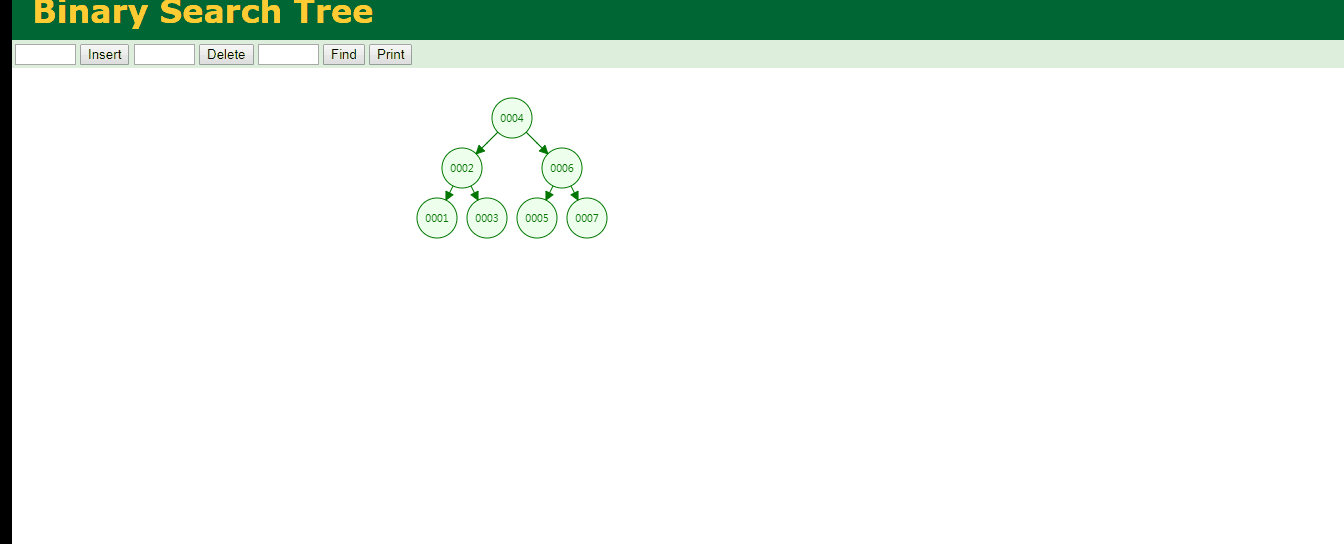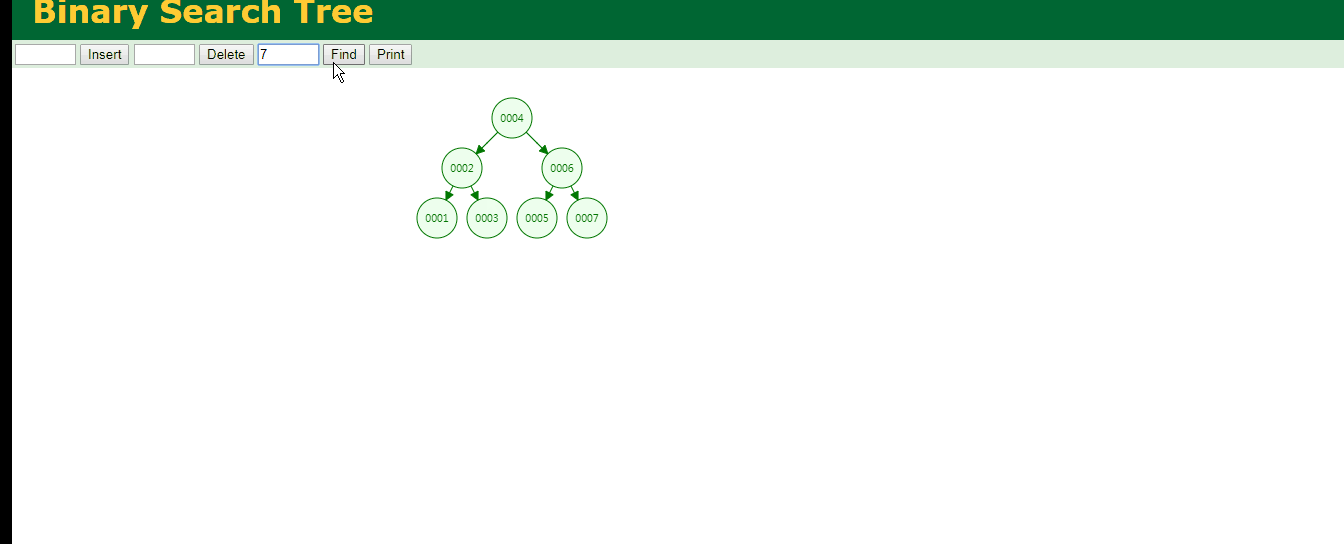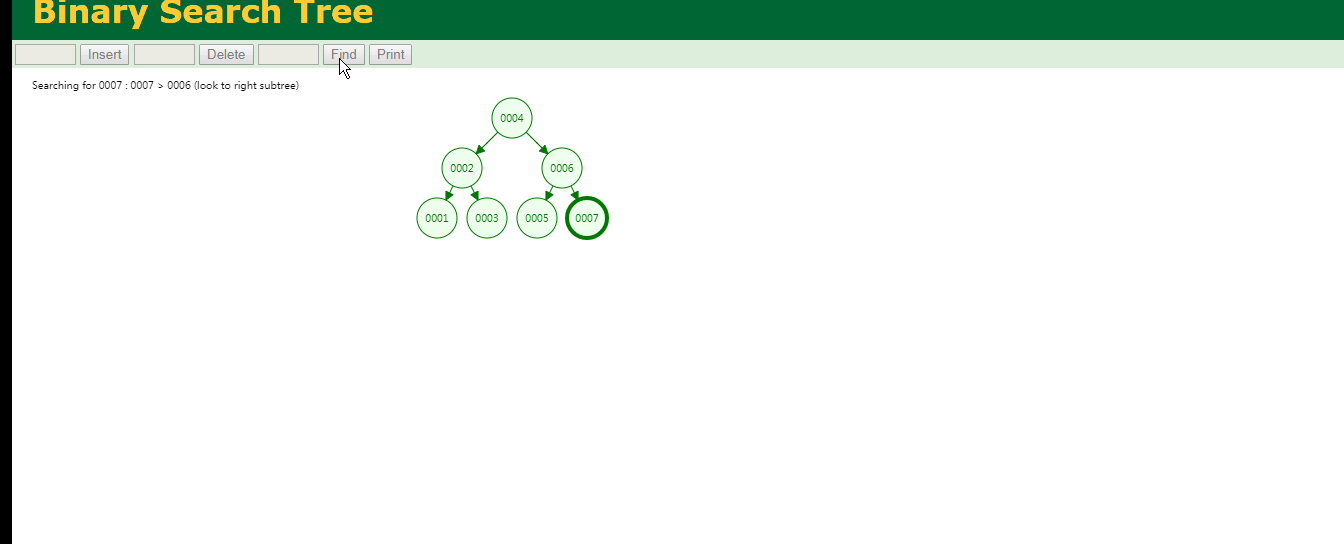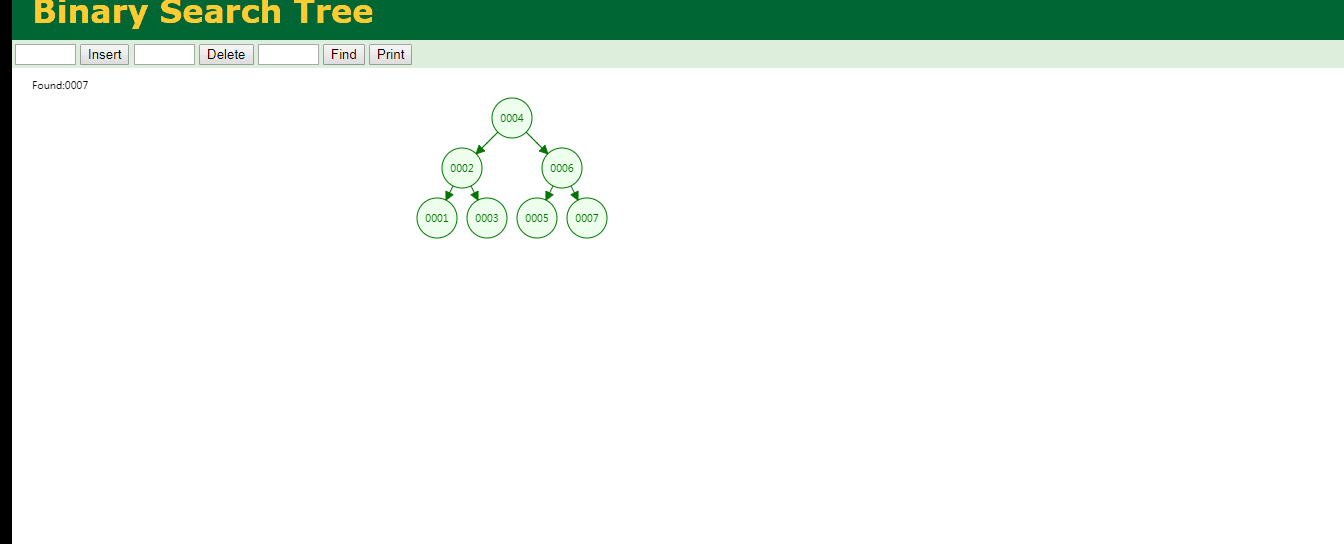
可见查询id为7的数据要比全表扫描要好.
但是如果我们从1开始插入数据的话,那么二叉树应该长这样

不平衡二叉树
显然,查找id为7的数据也需要7次,跟我们不建立索引是一样的效果
缺点:存在不平衡问题
如果二叉排序树是平衡的,则n个节点的二叉排序树的高度为Log2n+1,其查找效率为O(Log2n),近似于折半查找。如果二叉排序树完全不平衡,则其深度可达到n,查找效率为O(n),退化为顺序查找。一般的,二叉排序树的查找性能在O(Log2n)到O(n)之间。因此,为了获得较好的查找性能,就要构造一棵平衡的二叉排序树。
3.红黑树
概念:在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能
看一下红黑树的插入过程

可以发现每次插入都会有一些操作来保证二叉树的平衡
缺点:和二叉树一样,存在不平衡的情况
比如,我们从1插到15,如下图,可见,右子树的节点还是比左子树多

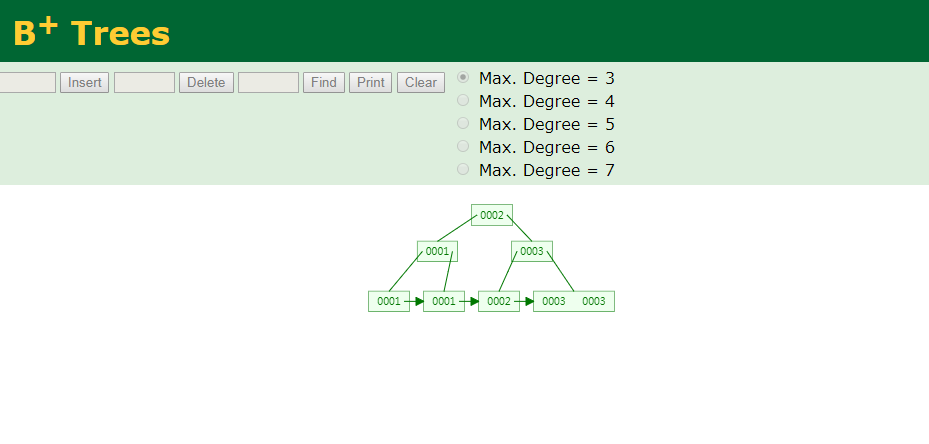
4.B+Tree
概念:B+ 树是一种树数据结构,通常用于数据库和操作系统的文件系统中。B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+ 树元素自底向上插入
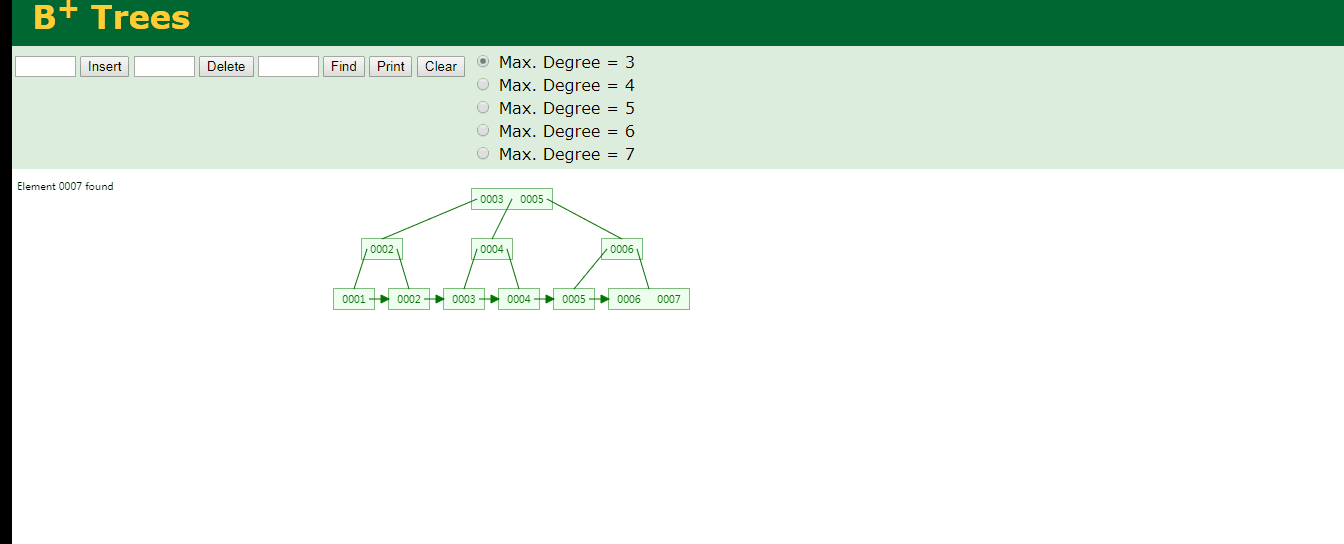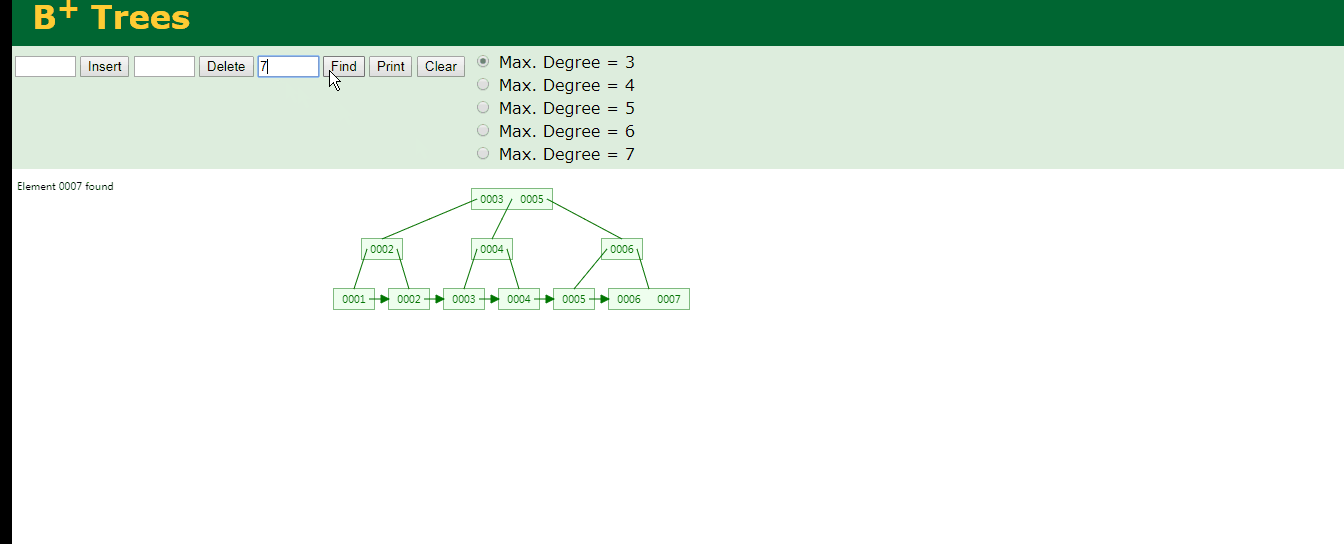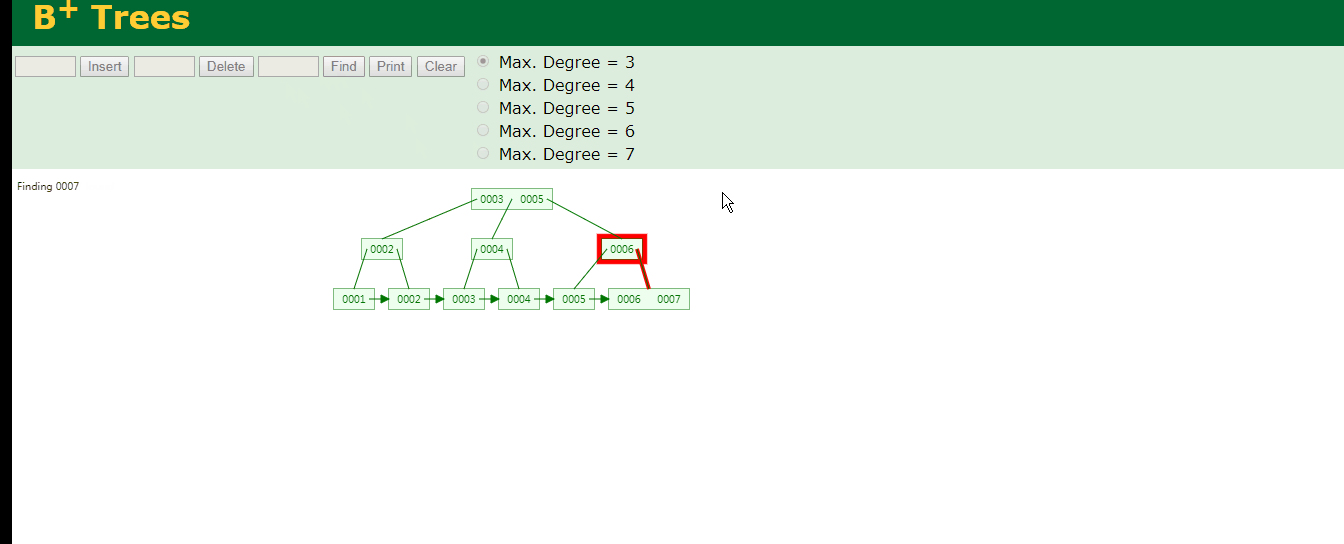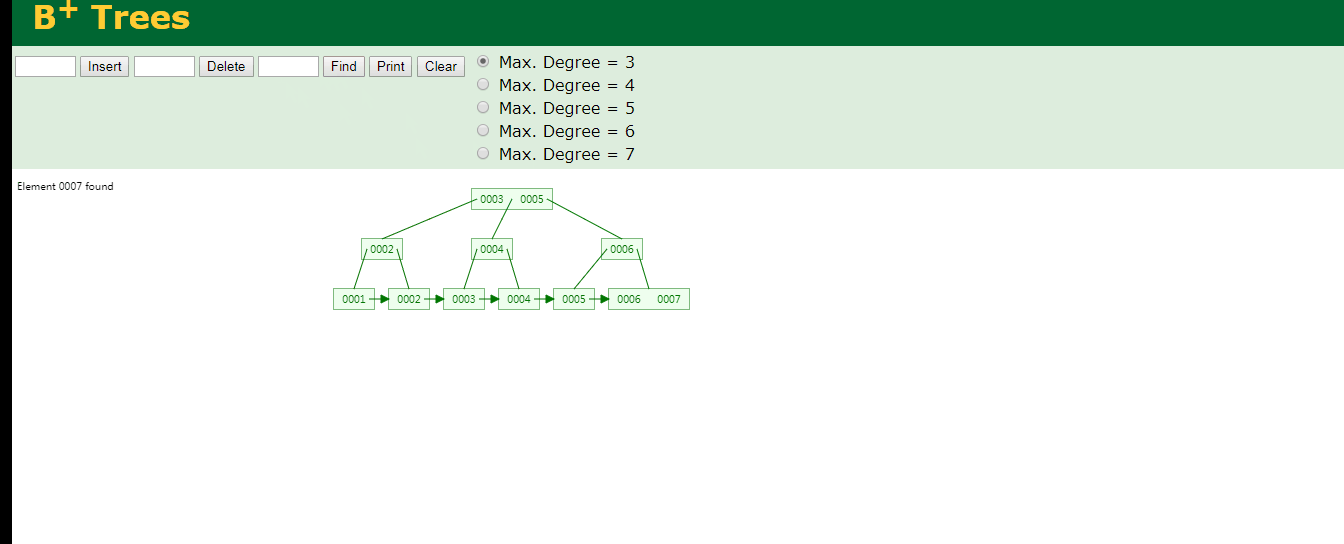
b+树最下层的节点个数会小于上面所选中的degree数量,查找元素为7的只需要3次
B+Tree时间复杂度为logN
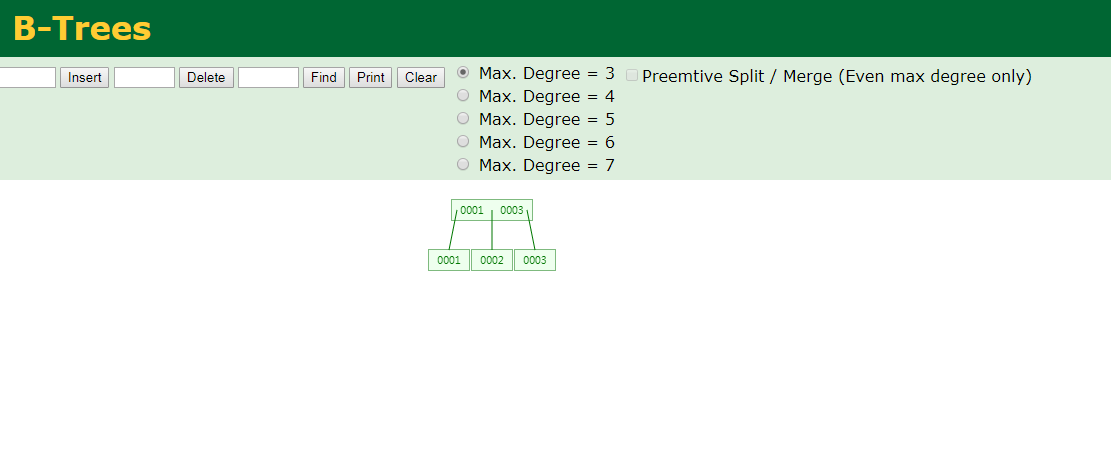
5.Btree
Btree与B+ Tree不同点: B+ tree只有在末节点存储数据,而btree 在所有节点都存储数据
同时将 1,1,2,3,3这几个数插入Btree和B+ tree中
参考文章:https://blog.csdn.net/li_huai_dong/article/details/79911069
感觉有用的小伙伴点个赞,加个关注呗