本文内容主要来自于浩东2011年6月的ppt。
目录:
1、大型网站架构的目标与挑战
2、网站架构演变及其技术脉络
3、架构设计理论与原则
何为“大型”网站?
没有统一的判断标准,流量大小是一个重要指标(日均流量至少IP>1,000,000才算大型网站)

一、大型网站架构的目标与挑战

每个目标背后面临着技术、设计、维护等诸多方面的挑战; 而目标本身的期望值也会根据实际情况进行调整,这也意味着网站架构建设是个不断调整的过程。
二、网站架构演变及其技术脉络
1、Web动静态资源分离及其与DB物理分离

Web Server(ApacheNginxIISJBoss…)、
Database Server(MysqlOracleRedis…)
注意:一般地,本文提到的物理服务器都是泛指pc级物理服务器;Web Server泛指HTTP服务器和应用服务器综合体对于一个试水性网站来说为了节约成本,Web Server和DB Server都放在同一台pc Server服务器上是常见的事情。当网站访问量增大,cpu处理能力是瓶颈的时候,通过把web Server和Db Server简单物理分开的,效果明显!
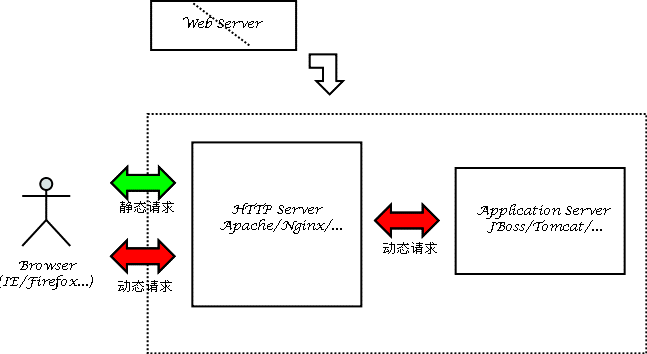
web动静态资源分离:
-->img,doc,js,css等静态资源使用单独的Web HTTP Server处理请求
-->动态页面静态化处理
2、采取缓存处理
访问量持续增大,页面响应越来越慢。考虑到网站还处在试水性成长阶段,节约成本,硬件不动,着重应用本身优化。采取缓存处理机制是个必然的选择。

访客向网站发出访问请求,由前端页面缓存器负担原服务器的处理进程做出响应,获取原服务器的相应网页内容,将其储存在自身的内存中,与 此同时,传送给访客这一缓存的内容;如有另一访客也请求访问之前的相同内容,前端页面缓存器毋须再次获取原服务器上的相应内容,而直接从自身的内存中获取,将这一内容传送给访客。反之,前端页面缓存器也可缓存访客的GET和POST请求。 访客实际面对的是前端页面缓存器,与网站之间的通讯完全由前端页面缓存器反向代理,而非原服务器直接响应访客,这将大大加快访客上网流畅度,有效提升访问量,显著降低带宽占用,减轻原始服务器的繁忙度,加快响应速度,毋须不停地购置大内存,大硬盘,扩容电力设施为服务器端节省成本。

注意:采用具备缓存功能的http反向代理服务器作前端页面缓存器,VarnishSquidNcacheAiCache(商业)…【硬件F5】
ESI是一个基于XML的标记语言,目的是在HTTP中组装各种资源。在实际环境中,一个动态生成的页面,当中可能只有少量的内容是频繁变化的或是个性化的,对于传统的Cache服务器来说,为了能够保证页面的时效性,却由于页面中这些少量的动态内容而无法将整个页面进行缓存。ESI通过使用简单的标记语言来对那些可以缓存和不能缓存的网页中的内容片断进行描述,每个网页都被划分成不同的小部分分别赋予不同的缓存控制策略,使Cache服务器可以根据这些策略在将完整的网页发送给用户之前将不同的小部分动态地组合在一起。通过这种控制,可以有效地减少从服务器抓取整个页面的次数,而只用从原服务器中提取少量的不能缓存的片断,因此可以有效降低原服务器的负载,同时提高用户访问的响应时间。
ESI需要服务器端支持,常见apache(mod_esi)、WebLogic、JSP标签库(JESI)等。
(4)本地数据缓存
(4.1)关系数据库系统(如:OracleMySql)Query Cache策略:一般以sql为key来缓存查询结果,尽量不要拼sql,使用PreparedStatement的“?”模式sql;Query Cache大小要根据数据库系统具体情况合理设置,过大只会浪费内存,参考值:128M
(4.2)关系数据库系统Data Buffer策略:就是数据库数据内存缓存器,其访问命中率决定数据库性能,可根据实际物理内存大小适量增大,如:MySql建议buffer值为物理内存60-80%
(4.3)应用服务器Cache包括:对象缓存(例如:对象线程安全,做成单例),更新频率不大数据考虑缓存(如:基表数据、配置文件信息),考虑使用线程池,对象池,连接池等
(4.4)常见java解决方案:mapOSCacheEHCache等
注意:1、需要从数据库系统和Web应用服务器两个层面考虑缓存优化
2、常见缓存算法:(贝莱蒂算法、最近最少使用算法、最近最频繁使用算法、伪LRU算法)
3、增加机器做HA、数据库读写分离

LVS(LVS集群采用IP负载均衡技术和基于内容请求分发技术。调度器具有很好的吞吐率,将请求均衡地转移到不同的服务器上执行,且调度器自动屏蔽掉服务器的故障,从而将一组服务器构成一个高性能的、高可用的虚拟服务器。整个服务器集群的结构对客户是透明的,而且无需修改客户端和服务器端的程序)

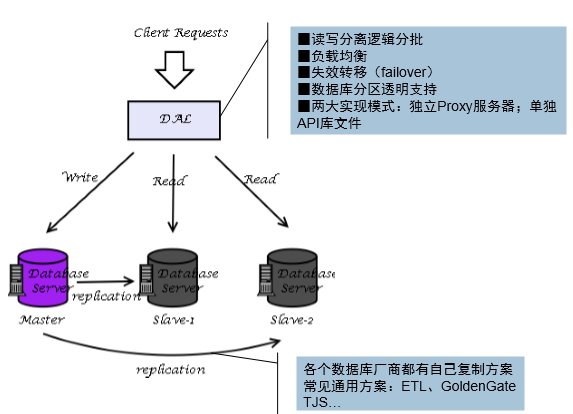
各个关系数据库厂商针对dal及replication都有自己方案
独立的DAL Proxy服务器(MySQL: mysqlproxy,Amoeba;PostgreSQL: PL/Proxy )
DAL API(Java: Hibernate Shard,Ibatis Shard,HiveDB,Guzz;Python: Pyshards)
4、CDN、分布式缓存、分库
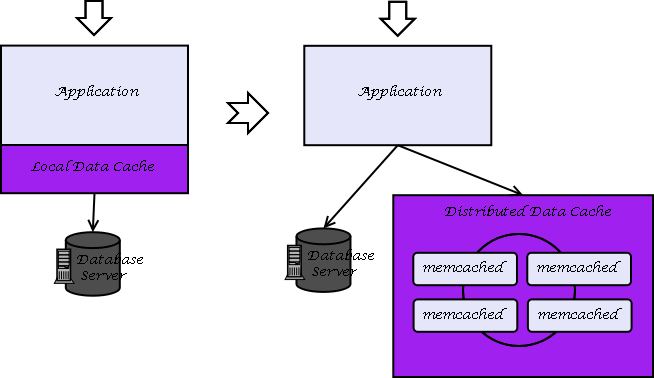
网站业务发展迅速,数据量大幅增大是当前最大的挑战,用户分散各地区,某些地方用户访问响应很慢,影响体验和业务发展;同时,由于数据量过大,数据缓存在本地内存已经不现实,分布式缓存是必然选择了

CDN的全称是Content Delivery Network,即内容分发网络。其目的是通过在现有的Internet中增加一层新的网络架构,将网站的内容发布到最接近用户的网络"边缘",使用户可以就近取得所需的内容,解决 Internet网络拥挤的状况,提高用户访问网站的响应速度。从技术上全面解决由于网络带宽小、用户访问量大、网点分布不均等原因所造成的用户访问网站响应速度慢的问题。 (也就是一个服务器的内容,平均分部到多个服务器上,服务器智能识别,让用户获取离用户最近的服务器,提高速度。
(2)分布式缓存

垂直分库后,各模块数据之间如何关联查询?垂直分库前提是良好的松耦合的模块化设计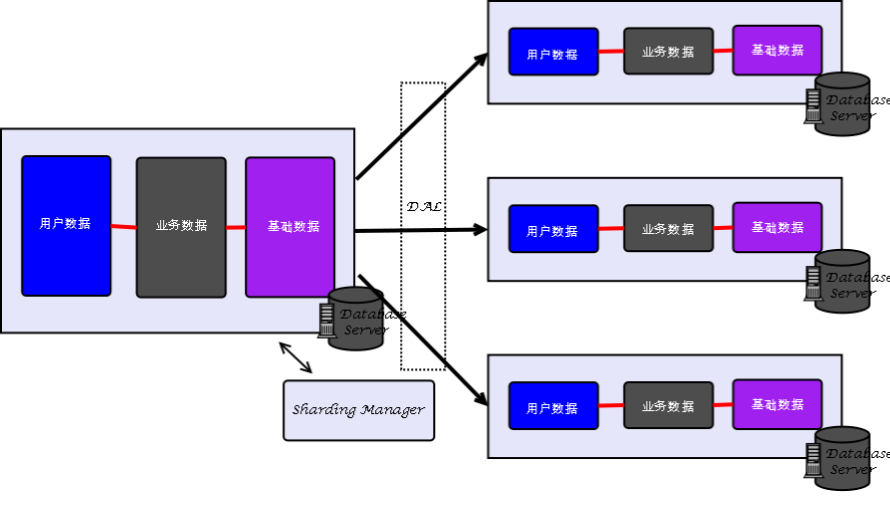
水平分区中,Shard是分布式解决方案,与数据库集中式的表空间分区是两个不同方案(分片Key识别(划分检索依据)是关键)
5、多个数据中心,向分布式存储和计算的架构体系迈进

DFS提供了一个全局命名空间的高可用(通过跨机器(和跨机架)的文件数据复制来达到高可用性,免受传统文件存储系统无法避免的许多失败的影响)文件系统,解决高容量数据高效、可靠存储问题;Map/Reduce的计算框架,它与DFS紧密协作,帮助处理收集到的海量数据;Key-Value DB代替传统的数据库,通过一些主键来组织海量数据,并实现高效的查询。

Google(GFS|Map/Reduce|BigTable)
Apache Hadoop(HDFS|Map/Reduce|HBase)
三、架构设计理论与原则
1、关于数据一致性—ACID vs BASE


