runxinzhi.com
首页
百度搜索
python--scrapy框架爬取分页数据与详情页数据
我们以abckg网址为例演示。
首先爬取详情页。
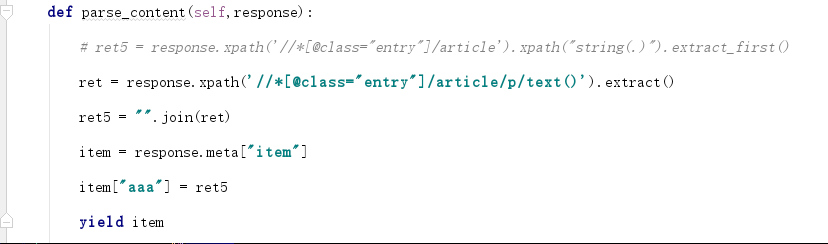
另外一种解析内容页:
然后是爬取分页:
还有一种方法就是设置一个方法循环爬取:
相关阅读:
Qt学习之路,part1
1.获取状态栏的高度
如何在Android Studio中上传代码到Gitee上
关于类图
外观模式
关于类的实例
SharedPreference中关于editor.apply()和editor.commit()
活动的4种启动模式
unittest中case批量管理
unittest使用
原文地址:https://www.cnblogs.com/kitshenqing/p/11047468.html
最新文章
事务的隔离级别
细数JDK里的设计模式
Java中的内存处理机制和final、static、final static总结
快速排序
Android 显示原理简介
android模拟器怎么直接安装apk
解决android.os.NetworkOnMainThreadException
genymotion启动报错
goldengate原理与简单配置
为什么String类是不可变的?
热门文章
怎么获取Android应用程序的上下文
通知
Linux下的lds链接脚本基础
经典试题(2)
经典试题(1)
|、& 、 || 、 &&四者的区别
vim 常用指令
三个问题
复习C
华为--嵌入式软件工程师面试题汇总
Copyright © 2020-2023
润新知