1. 什么是迭代协议?
迭代协议主要包括两方面的协议集,一种是迭代器协议,另一种是可迭代协议。对于迭代器协议来说,其要求迭代器对象在能够在迭代环境中一次产生一个结果。对于可迭代协议来说,就是一个对象序列,该序列可以是实际保存的序列,也可以是按照计算需求而产生的虚拟序列
在Python中,如何判断一个对象是否可迭代呢?我们可以从collections.abc模块下的Iterable和Iterator得到答案
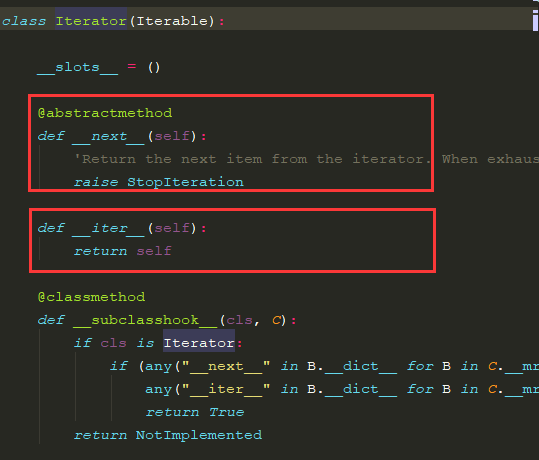
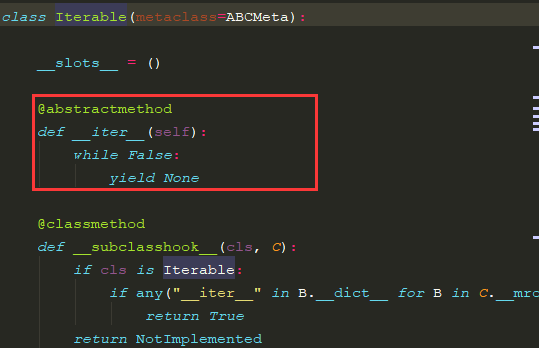
从图中可以看出, 相比较于Iterator对象,可迭代对象要求实现__iter__()这一魔法方法即可,而一个迭代器对象不仅需要实现__iter__()方法,还需要实现__next__()方法,其作用便是能够迭代环境中惰性地返回一次结果。
2.迭代器对象和可迭代对象
刚刚我们通过源码分析得出,迭代器对象需要同时拥有__next__()和__iter__()方法,而一个可迭代对象要求实现__iter__()方法。
那么在Python的数据类型中,那些类型对象是可迭代的呢? 一方面我们可以通过查看所属类型的源码来得出答案,另一方面也可以通过isinstance方法来得知。

在Python的数据类型中, tuple、set、dict、string、list均是可迭代类型。
3.自定义迭代器
在自定义迭代器之前,我们先来看一段代码
# coding:utf-8 from collections.abc import Iterator, Iterable class MyIterator(): def __init__(self, _list: list): self._list = _list self.eq = 0 def __iter__(self): return self def __next__(self): """迭代输出,可能造成eq超出_list的最大下标""" try: cur = self._list[self.eq] except IndexError: # 超出范围抛出StopIteration异常 raise StopIteration else: self.eq += 1 return cur class _Class(object): def __init__(self, members: list): self.members = members def __iter__(self): """实现了可迭代协议,就是一个可迭代对象""" return MyIterator(self.members) def main(): """测试""" students = ["stu[{0}]".format(num) for num in range(1, 11)] _class = _Class(students) # 将_class转化为迭代器对象 _class_itor = iter(_class) print("_class_itor对象是MyIterator的实例:",isinstance(_class_itor, MyIterator)) while 1: try: cur = next(_class_itor) print(cur) except StopIteration: print("迭代完成") break if __name__ == '__main__': main()
输出为:
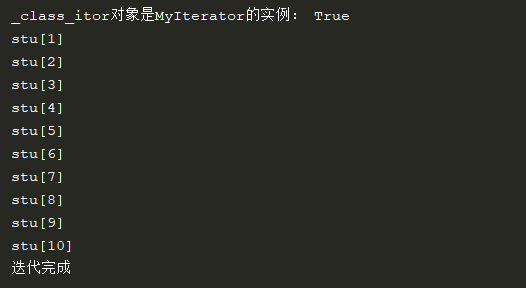
在以上程序中,_Class类拥有__iter__方法便实现了可迭代协议,其对象就是可迭代对象,但是奇怪的是为什么执行iter方法得到的_class_itor对象是MyIterator的实例呢?
我们继续改写代码,使得__iter__返回其自身对象(_Class,只是一个可迭代对象,没有实现__next__方法),看一下效果:
class _Class(object): def __init__(self, members: list): self.members = members def __iter__(self): """实现了可迭代协议,就是一个可迭代对象""" # return MyIterator(self.members) return self def main(): """测试""" students = ["stu[{0}]".format(num) for num in range(1, 11)] _class = _Class(students) # 将_class转化为迭代器对象 _class_itor = iter(_class) print("_class_itor对象是MyIterator的实例:",isinstance(_class_itor, MyIterator)) while 1: try: cur = next(_class_itor) print(cur) except StopIteration: print("迭代完成") break if __name__ == '__main__': main()
运行输出:
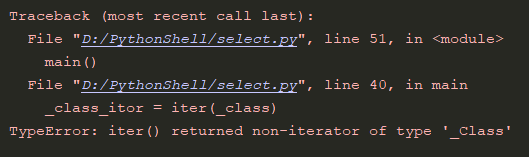
意料之中,iter函数要求接收的参数对象必须是一个迭代器类型,即实现了__next__方法,在上述代码中,_Class类型只属于可迭代类型,并没有实现__next__方法,所以报错了。
那么按照上述说法,我们继续改写程序,让_Class的__iter__方法返回一个迭代器对象呢?
class _Class(object): def __init__(self, members: list): self.members = members def __iter__(self): """实现了可迭代协议,就是一个可迭代对象""" # return MyIterator(self.members) return iter(["stu[{0}]".format(num) for num in range(1, 11)]) def main(): """测试""" students = ["stu[{0}]".format(num) for num in range(1, 11)] _class = _Class(students) # 将_class转化为迭代器对象 _class_itor = iter(_class) print("_class_itor对象是MyIterator的实例:",isinstance(_class_itor, MyIterator)) while 1: try: cur = next(_class_itor) print(cur) except StopIteration: print("迭代完成") break if __name__ == '__main__': main()
运行输出:
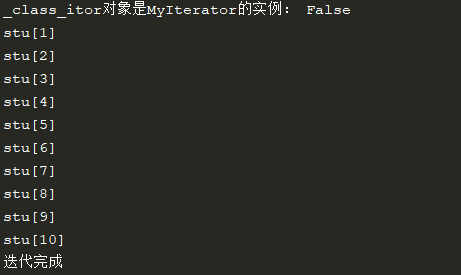
由此,我们得出结论:迭代器类型需要实现__next__方法和__iter__方法,并且特别注意的是__iter__方法的返回值需要是Iterator类型, __next__方法只是暂存了迭代器对象在当次迭代环境下的当次结果。
4. 生成器函数
在分析生成器函数之前,先来一段代码
import builtins def gen_func(): yield 1 yield 2 yield 3 yield 4 yield 5 def func(): return 1 if __name__ == '__main__': gen = gen_func() print(gen) print(hasattr(gen, "__next__")) print(hasattr(gen, "__iter__")) fun = func() print(fun)
运行结果:

可以看出,gen_func()函数多次使用yield关键字来惰性地抛出数值,但gen不再是一个int类型,而是一个generator对象, 这便是一个生成器函数(yield作为返回关键字而不采用return)。除此之外,还可以发现generator对象实现了__iter__和__next__方法,也就是说生成器函数对象属于迭代器类型,那么生成器函数对象肯定能够使用迭代语句进行惰性地获取结果。
5.用生成器函数惰性实现斐波拉契序列
1. 采用普通形式(递归地方式,缺点是不能看到完整的数列)
def fib(index): """1, 1, 2, 3, 5, 8.......""" if index<=2: return 1 return fib(index-1) + fib(index-2) if __name__ == '__main__': print(fib(8)) #21
2. 改进代码,使用列表来存储(采用循环的方式, 缺点是列表的存储空间是有上限的,十分消耗内存)
def fib2(index): """1, 1, 2, 3, 5, 8.......""" res = list() cur_index, ppre, pre = 0, 0, 1 while cur_index<index: res.append(pre) ppre, pre = pre, pre+ppre cur_index += 1 return res if __name__ == '__main__': print(fib2(8)) # [1, 1, 2, 3, 5, 8, 13, 21]
3. 生成器函数实现(有效解决内存问题,即用即取,惰性操作)
def fib3(index): cur_index, ppre, pre = 0, 0, 1 while cur_index<index: yield pre ppre, pre = pre, ppre+pre cur_index += 1 if __name__ == '__main__': for value in fib3(8): print(value)
结果:

6. 使用生成器函数实现大文件(百GB级,且数据未分行)的读取
对于大文件的读取,首先考虑的是避免将结果集一次性加载到内存,如果待读取文件是格式按照预先设定规则来进行换行的,如下:
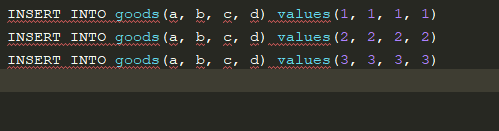
这样的文件直接采用迭代方式读取(for line in file)即可,但如果该文件如下且容量为1TB的该如何逐条读取SQL语句呢?

这时候yield关键字就派上用场了。
我们可以做如下思考:
1)文件句柄的read方法,能够接受一个参数作为输出流的缓冲区大小。
2)循环读取一定容量的数据进行处理,并在每次迭代环境下将一条完整的insert语句抛出。
def yieldLines(file, buffer_size, flag): buf = "" while True: while flag in buf: pos = buf.index(flag) yield buf[:pos] buf = buf[pos+len(flag):] chunk = file.read(buffer_size) # 读取结束 if not chunk: yield buf break buf += chunk if __name__ == '__main__': with open('./data_insert.txt', 'r') as f: for line in yieldLines(f, 1024, "|||"): print(line)
运行结果:

7. 深度分析生成器函数
在操作系统上有着进程(线程)的概念,在并发(并发是指在一段时间范围内,有多个线程/进程交替被CPU调度;并行是指在一个时间点上,有多个线程/进程被CPU调度,利用的CPU的多核心)执行的时候,程序遇IO操作,为了性能,常见的方式是采用异步非阻塞,但是当IO操作完成,进程由阻塞态转为就绪态时,依据于PCB(进程控制块),其进程能够记住运行上下文,达到继续从阻塞位置之后执行程序代码的效果。
对于生成器函数而言,其内部也维持了这样一个运行状态的记录,下面我们来对其进行分析
import dis def gen_func(): a = 1 yield a b = 2 yield b c =3 yield c if __name__ == '__main__': gen = gen_func() print(dis.dis(gen))
运行结果如下,显示的是该生成器函数的字节码形式:
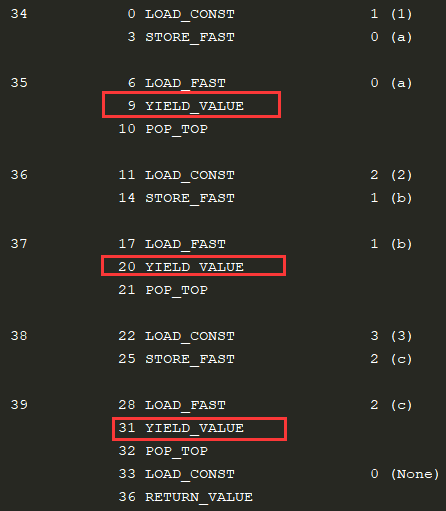
乍一看是不是很像汇编语言的指令,的确也类似这样,Python模块被编译成字节码文件之后才交由python解释器来解释执行,这样的指令就被赋予了新的含义,例如:
LOAD_FAST一般加载局部变量的值,也就是读取值,用于计算或者函数调用传参等。
STORE_FAST一般用于保存值到局部变量。
LOAD_GLOBAL用来加载全局变量,包括指定函数名,类名,模块名等全局符号。
其他指令可以查看这篇博文来获取
有了以上字节码形式,我们可以清楚的了解到函数被解释的细致流程,生成器函数运行状态上下文的记录便依据上图,下面我们来分析一下:
def gen_func(): a = 1 yield a b = 2 yield b c =3 yield c if __name__ == '__main__': gen = gen_func() # print(dis.dis(gen)) for _ in gen: print(gen.gi_frame.f_lasti) print(gen.gi_frame.f_locals)
运行结果如下:

通过比较上图两张截图可以看出gi_frame.f_lasti记录了每次python解释器执行YIELD_VALUE指令时的状态编码,来确定生成器函数的运行上下文。