一、理解创建索引的过程
创建索引的过程与写一本书差不多。
创建索引的过程如下:
- 建立索引器IndexWriter,这相当于一本书的框架。
- 建立文档对象Document,这相当于一篇文章。(对应数据库就是一张表)
- 建立信息字段对象,这相当于一篇文章中的标题,正文等。(对应数据库就是一个字段)
- 将Field添加到Document里面。
- 将Document添加到IndexWriter里面。
- 关闭索引器IndexWriter。
在创建索引的时候,有三个基本步骤:
- 创建Field。
- 将Field组织到一个Document里面,这样就完成了对一篇文章的包装。
- 将多个Document组织到一个IndexWriter里面,也就是将多个文章组装起来,最终形成索引。
主要功能由以下类提供:
- IndexWriter
- Document
- Field
- Analyzer
1、创建Field
创建Field最常用的构造函数(太多重载不一一叙述)如下:
Field(string name, string value, Store store, Index index)
参数说明:
- name:Field名称;
- value:Field值;
- Store:存储方式;
- Index:索引方式;
Store枚举
Store是一个枚举,在3.0.3版本只有两个取值了,表示是否将值存储到Lucene.net里:
- Yes存储;
- No不存储;
Index枚举
Index是一个枚举,在3.0.3版本有以下取值,
- NO : 不索引(数据库主键)
- ANALYZED : 索引经过分词器处理的字段值(正文,摘要,标题)
- NOT_ANALYZED : 不使用分词器索引字段值(meta keyword)
- NOT_ANALYZED_NO_NORMS:不分析也不索引(姓名,日期等不需要模糊搜索的字段)
- ANALYZED_NO_NORMS : 不使用分词器索引字段,也禁用索引调节因子
以一篇文章为例,通常我们会按照标题和全文进行模糊搜索,这类需要进行模糊搜索的字段就用Field.Index.ANALYZED,通常会按照作者名称进行精确搜索,需要精确搜索的字段就用NOT_ANALYZED_NO_NORMS。
而至于Store,比较小的内容可以直接存储,如作者,文档摘要等。而文章主体内容就没必要存储了。
2、创建Document
创建Document的方法如下:
Document doc = new Document();
这个方法用来创建一个不含任何Field的空Document。
如果想把Field添加到Document里面,只需要使用add方法:
doc.Add(field);
3、创建IndexWriter
创建IndexWriter的方法很多,下面给出最常用的方法:
using (IndexWriter writer = new IndexWriter(Directory, Analyzer, MaxFieldLength)){}
参数解释:
- Lucene.Net.Store.Directory:存储索引路径的实例;
- Lucene.Net.Analysis.Analyzer:分析器的实例;
- Lucene.Net.Index.IndexWriter.MaxFieldLength:可被拆分出最大的词条数量。
分析器是用来做词法分析的,包括英文分析器和中文分析器等。要根据所要建立索引的文件情况选择恰当的分析器。常用的有:
- StandardAnalyzer:标准分析器;
- CJKAnalyzer:二分法分词器;
- ChineseAnalyzer:中文分析器;
- FrenchAnalyzer:法语分析器;
可惜Lucene.net只有StandardAnalyzer分词器,要实现其他分词要配合上其他第三方分词器使用。
通过建立IndexWriter,就把逻辑索引和物理索引联系起来了,这样就可以很方便地建立索引。使用二分法分词器来分析字段内容,然后将索引建立在Directory实例的路径中。
要把Document添加到索引中来,需要使用addDocument方法。
writer.AddDocument(doc);
二、索引的优化
1、索引优化的本质
建立索引的目的是为了搜索,搜索实际上是I/O操作。当索引数量增加、文件增大的时候,I/O操作就会减慢,搜索速度也就会减慢,所以需要优化。
随着被索引的文件数量的增加,索引文件本身也在增加,数量也在增加,在搜索的时候面临着同时读取多个索引文件以及读取大索引文件的问题,这些问题都会导致索引速度减慢。
优化索引的核心策略是:
- 利用缓存,减少磁盘读写频率;
- 减少索引文件的大小和数量;
2、复合式索引格式
在前面,我们知道扩展名为cfs的文件是复合式索引格式的索引文件,它相当于把多个索引文件合并起来,从而减少了索引文件的数量。
使用复合式索引文件格式可以有效减少索引文件的数量,是索引优化的重要方法。IndexWriter可以设置是否使用复合式索引格式。默认是Ture,使用复合式索引格式。
3、调整索引优化参数
先在内存中建立索引,然后将索引写到文件系统中,这样比直接在文件系统中添加索引速度快得多。
Lucene提供了3个优化参数,可以优化磁盘写入的频率和内存消耗。对这些参数应该灵活使用,从而优化索引。这3个参数可以通过IndexWriter类来设定。
(1)、mergeFactor合并因子
用来控制索引块的合并频率和大小,默认值是10。
在将Document对象写入磁盘之前,可用mergeFactor参数控制在内存中存储的Document对象的数量以及合并多个索引块的频率。在将它们作为单个块写入磁盘之前,Lucene在内存中默认存储10个Document对象。mergeFactor的值为10也意味着磁盘上的块数达到10的乘方时,Lucene会将这些块合并为一个段。
也就是说,每当向索引增加10个Document的时候,就会有一个索引块被建立起来。当磁盘上有10个索引块的时候,将被合并为1个大块。这个大块中含有100个Document。然后,继续积累,到10个大块的时候,被合并为一个更大的索引块,这个索引块中含有1000个Document。
因此,任意时刻索引中的块数一定都是小于10的,并且每个合并后的块的大小均为10的乘方。但是,这个参数受到maxMergeDocs参数的制约,由此导致每个索引块中含有的Document数量都不可以大于maxMergeDocs参数的值。
使用较大的mergeFactor参数会让Lucene使用更多的内存,同时使得磁盘写入数据的频率降低,因此加速了索引过程。较小的mergeFactor参数能减少内存消耗,并使索引更新的频率升高。这样做使得数据的实时性更强,但是也降低了索引过程的速度。
所以,较大的maxMergeDocs参数适用于批量索引的情况,较小的maxMergeDocs参数适用于交互性较强的索引。
writer.MergeFactor = 10;
(2)、maxMergeDocs索引块文档数量
用来限制每个索引块的文档数量,默认值是Integer.MAX_VALUE。
InderWriter使用MaxMergeDocs属性来设置maxMergeDocs的大小。
writer.MaxMergeDocs = 10;
(3)、maxBufferedDocs内存中的文档数量
用来限制内存中的文档数量,默认值是10。这个值越大,在内存中存储的文档数量就越多,消耗内存更多,但磁盘I/O会更少。maxBufferedDocs参数的意义在于使用更新的内存空间来缓存更快的索引,该参数并不影响磁盘上的索引块大小。
writer.GetMaxBufferedDocs(); writer.SetMaxBufferedDocs(10);
4、内存缓冲器与索引合并
这个东西的原理是:首先在内存中建立索引,然后将建立好的索引集中写到磁盘中去,这样避免了在磁盘中一次次地增加索引文件,从而加快索引速度。
为了将索引放在内存中缓冲起来,我们需要内存缓冲器。
前面学习的IndexWriter的构造方法第一个参数是Directory,这个Directory实例可以选择RAMDirectory或FSDirectory。
- RAMDirectory:在内存中建立索引;
- FSDirectory:在磁盘中建立索引;
可以通过不断增大mergeFactor或者MinMergeDocs的值,从而使得基于FSDirectory的索引速度接近基于RAMDirectory的索引速度。但无论怎么组合参数,基于FSDirectory的索引性能都不可能超越基于RAMDirectory的性能。
在通过修改IndexWriter类的mergeFactor、maxMergeDocs和maxBufferedDocs参数提高性能的前提下,如果希望进一步改进Lucene的索引操作性能,就可以把RAMDirector作为缓冲器,先将索引文件缓存在缓冲器中,再把数据写入基于FSDirectory的索引中,从而达到改善性能的目的。
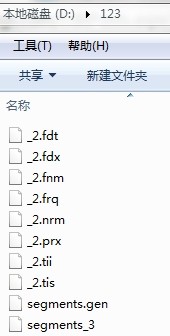
如果是使用FSDirectory方式创建:
DirectoryInfo dir = new DirectoryInfo(@"D:123"); Lucene.Net.Store.Directory directory = new SimpleFSDirectory(dir);
则目录下会立即创建索引文件:
内存缓冲器法
到目前为止RAMDirectory和FSDirectory两个方式都用过了,下面展示一个示例,通过内存缓冲器法将RAMDirectory的索引内容写入到FSDirectory。
这个方法包含以下4个步骤:
- 建立基于RAMDirectory的索引。
- 向基于RAMDirectory的索引中添加文档。
- 建立基于FSDirectory的索引。
- 把缓存在RAMDirectory中的所有数据写入FSDirectory。
static void Main(string[] args) { //创建内存索引 Analyzer analyzer = new StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_30); Lucene.Net.Store.Directory ramdirectory = new RAMDirectory(); IndexWriter.MaxFieldLength maxFieldLength = new IndexWriter.MaxFieldLength(10000); using (IndexWriter writer = new IndexWriter(ramdirectory, analyzer, maxFieldLength)) { writer.MergeFactor = 10; Document document1 = new Document(); document1.Add(new Field("Name", "刘备", Field.Store.YES, Field.Index.ANALYZED)); document1.Add(new Field("Age", "22", Field.Store.YES, Field.Index.ANALYZED)); writer.AddDocument(document1); writer.Optimize(); } //创建磁盘索引 DirectoryInfo dir = new DirectoryInfo(@"D:1234"); Lucene.Net.Store.Directory fsdirectory = new SimpleFSDirectory(dir); using (IndexWriter writer = new IndexWriter(fsdirectory, analyzer, maxFieldLength)) { IndexReader reader = IndexReader.Open(ramdirectory, true); //通过AddIndexes方法,将内存索引并入到磁盘索引 writer.AddIndexes(reader); } }
这种通过RAMDirectory作为FSDirectory的临时缓冲区的方式可以很好地提高索引性能。
如果是在多线程环境仲,可以让每个线程通过RANDirectory建立各自的索引,最后通过FSDirectory建立单一的索引文件,这种做法效率更高。
既可以通过将内存索引并入磁盘索引,也可以将磁盘索引并入内存索引,方式类似。
5、限制每个Field的词条数量
对于某个Document的某个Field,我们可以限定它可被拆分出最大的词条数量。这需要使用IndexWriter的GetMaxFieldLength()或SetMaxFieldLength()方法。
如果某个Field被拆分成了大量的词条,那么将消耗大量的内存。很容易导致内存溢出,这个问题在大文档的情况下尤其容易发生,因此我们要做这个限定。
通常,不要将maxFieldLength设置在10000以上。
writer.GetMaxFieldLength(10000);
writer.SetMaxFieldLength(10000);
6、索引本身的优化
IndexWriter具有一个方法如下:
optimize();
这个方法没有参数,但非常有用。专门用来优化索引的。当索引建立好以后,这个方法的调用将使得多个索引文件合并成单个文件,经过优化的索引比未优化的索引包含的索引文件要少得多。因此,在搜索时减少了读取索引文件的时间,进而加快了搜索速度。
这项索引优化只会提高搜索操作的速度,它对索引过程的速度没有影响。这项优化是通过把已存在的索引块合并成一个全新的索引块来完成的,在进行优化时,使用的磁盘空间会有明显的增加。在新的所有块建立完成之前,旧的索引块不会被删除。这时索引块占用的磁盘空间会变成原来的两倍。等到优化完成后,所占用的磁盘空间会降回到优化前的状态。索引优化的对象可以是多文件索引或复合索引。
索引优化是非常耗费时间的,虽然可以在任意时刻进行优化,但最佳时机是在索引建立完成之后。如果在索引建立的过程之中执行优化,将会导致优化操作耗费更多的时间。
7、查看索引的过程
如果将IndexWriter的公有变量InfoStream设定为某个流,就可以使Lucene输出关于它进行索引操作时的一些具体信息。这对于我们进行精细的索引优化是很有帮助的。
主要通过如下方式实现:
writer.SetInfoStream(sw);
示例如下:
using (StreamWriter sw = new StreamWriter(@"D:123.txt")) { using (IndexWriter writer = new IndexWriter(ramdirectory, analyzer, maxFieldLength)) { writer.SetInfoStream(sw); writer.MergeFactor = 10; Document document1 = new Document(); document1.Add(new Field("Name", "刘备", Field.Store.YES, Field.Index.ANALYZED)); document1.Add(new Field("Age", "22", Field.Store.YES, Field.Index.ANALYZED)); writer.AddDocument(document1); writer.Optimize(); } }