可变属性的需求:我们需要在数据库里面存储很多电器,比如电视,冰箱等等。通常,在程序中,我们的类图为:
EVA设计
对于这种继承下来的可变属性时,有一种办法是创建另外一张表,将属性当成行来存储。
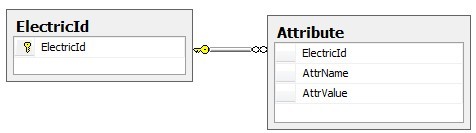
其中存储的数据类似下面这样:
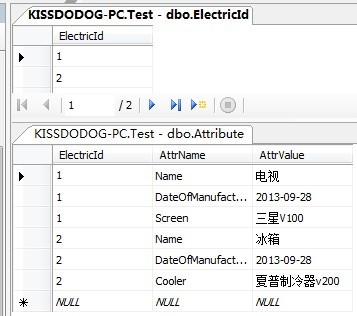
这样的设计称为:实体-属-值,简称:EVA,或者又叫开放架构、无模式。
这种设计有如下3种好处:
1、这两张表的列都很少。
2、新增的属性不会对现有的表结构造成影响,不需要新增列。
3、避免由于空值而造成的表内容混乱。
但是这样也有如下缺点:
1、查询属性
本来,我们想要按出厂日期查询,只需要:
SELECT ElectricId,DateOfManufacture FROM Electric
但是这种方式不行,它需要这样:
SELECT ElectricId,AttrValue AS 'DateOfManufacture' FROM Attribute WHERE AttrName = 'DateOfManufacture'
2、无法声明强制属性
本来,我们要确保DateOfManufacture(出厂日期)这个属性有值,在传统数据库设计中,只需要很简单的声明一个NOT NULL就OK了。
但是现在在EVA设计中,每个属性对应的是Attribute中的一行。我们需要建立一个约束来检查对于每个ElectricId都存在一行,并且这行的AttrName是DateOfManufacture。并且这行记录的AttrValue不为空,并且符合日期格式。
3、无法使用SQL的数据类型
由于AttrValue的格式只能声明为Varchar或NVarchar类型,因此用户输入的日期格式可能是各种各样,甚至有的根本就不是日期格式。
由于数据类型不能够由限制,因此我们执行如下SQL语句也不会报错。
INSERT Attribute VALUES(1,'DateOfManufacture','我不是一个日期') --这样的语句也不报错
4、无法确保引用完整性
加入上面的设计,我们需要添加一个品牌属性。可选值必须是存在的比如,三星,康佳,海尔等等。在传统的数据库设计中,我们只需要设计一张品牌表,并给本表添加一个品牌Id字段,建立外键约束就可以了。
但是,在EVA设计中,因为品牌属性对应的是一行,因此我们无法使用外键来确保引用完整性。如果我们不处理,那么用户输入的品牌属性的值可能是不存在的。
5、重复记录
在EVA设计中,我们可能将同一个属性了两次。
因为,我们连续执行如下SQL语句两次也是不报错的:
INSERT Attribute VALUES(1,'DateOfManufacture','2013-09-09') INSERT Attribute VALUES(1,'DateOfManufacture','2013-09-10')
由于可能存在重复记录,因此我们按出厂日期统计出厂产品数量也并不可靠。同时,按日期统计,也很复杂。
SELECT ElcDate, COUNT(*) AS Per_Date FROM (SELECT DISTINCT ElectricId,AttrValue AS ElcDate FROM Attribute WHERE AttrName = 'DateOfManufacture') GROUP BY ElcDate
这是Oracle中的写法。
6、重组列
在传统数据库设计中,加入我们要显示一条完整的记录,我们只需要:
SELECT * FROM Electric
但是现在,我们要:
SELECT i.ElectricId, i1.AttrValue AS 'Name', i2.AttrValue AS 'DateOfManufacture', i3.AttrValue AS 'Screen' FROM Electric AS i LEFT OUTER JOIN Attribute AS i1 ON i.ElectricId = i1.ElectricId AND i1.AttrName='Name' LEFT OUTER JOIN Attribute AS i2 ON i.ElectricId = i2.ElectricId AND i2.AttrName='DateOfManufacture' LEFT OUTER JOIN Attribute AS i3 ON i.ElectricId = i3.ElectricId AND i3.AttrName='Screen'
不在多说,总而言之,以上的设计,并非一个非常耐得住推敲的设计。
解决方案
一、单表继承
单表继承的设计是将所有相关的类型都存在一张表中,为所有类型的所有属性都保留一列。同时使用一个属性来定义每一行表示的子类型。
例如,对于以上电器的需求,单表继承的数据设计如下:

单表继承的方式可以理解为,所有子类的字段,都往单表里放,存储的时候,当某子实体没有的时候,相应的类为空,都是预留一列作为标记类型。
单表继承的缺点就是:
- 列过多。
- 过多NULL值。
- 当要增加属性的时候,要改动表结构。
综上所述:单表继承只是适合使用子类的特殊属性列不多的情况。
二、实体表继承
实体表继承可以理解为:子表在设计的时候,将父表的所有的属性全部都在本表定义多一次。
回到上面的例子,如果用实体表继承的话,对应的设计如下:
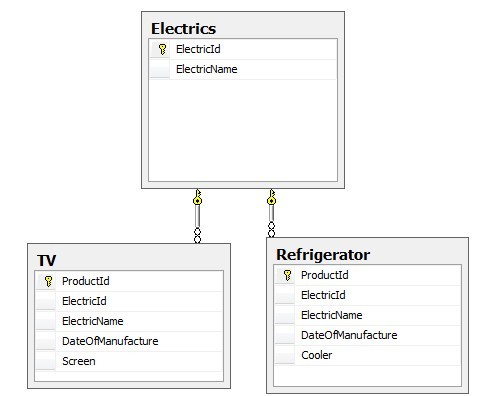
实体表继承相比于单表继承,有一个好处,就是防止在一行内存储太多和当前子类型无关的属性。比如在冰箱表里没有了屏幕列,而在单表继承中,是由Scree列的NULL值的。另外,也不用在加多一个列用于标记当前是什么电器。
实体表继承的致命缺点:
重复列过多
重复列过多,很容易让人摸不着头脑。
三、类表继承
我的推荐,我最喜欢,我认为最可靠的方式
类表继承模拟了高级程序语言中的继承,把表当成面向对象里的类。创建一张基表,包含所有子类型的公共属性。对于每个子类型,创建一个独立的表,通过外键和基类表相连。
对以以上例子,类表继承的设计如下:

类表继承,相比于实体类继承,明显的有点在于,少了很多重复列。子类表中,主键同时也是外键。
我认为这是一个比较好的方法。
四、半结构化
半结构化,实际上跟单表继承差不多。单表继承是多个列,而半结构化使用一个新特性,比如一个xml类型的列,来存储子类的属性。
对于以上例子,半结构化的设计如下:
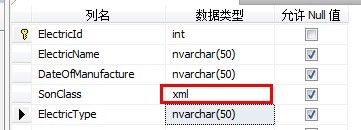
子类的信息,存在一个XML列中,你爱设置什么节点就什么节点。反正查询起来也不麻烦。不够要记住的是,要有一个Type列,来标记哪行是哪种电器。不然就全乱套了。
由于,现在SQLServer对XML的支持越来越强大,这也是一个不错的选择。