链表
Content
链表的概念
链表基本单元
创建表头
创建节点
打印链表
删除节点
一、链表的概念
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
一般采用结构体指针嵌套构建。
二、链表基本单元
struct Node { int data; struct Node *next; };
int data:为储存数据的变量,在一个结构体中可以定义多个变量,以达到一个节点储存多种数据的目的。
Node *next:为结构体指针,其作用是链接不同单元,以实现线性链表的链接。
三、创建表头
Node *CreateList() { Node *headNode = (Node *)malloc(sizeof(Node)); // headNode 成为了结构体变量 // 变量使用前必须初始化 headNode->next = NULL; return headNode; }

由于链表的长度不确定,我们在创建链表的时候就需要向计算机申请内存,在C语言中动态申请内存的函数是malloc(函数储存于头文件<stdllib.h>内),基本格式是—— (需要申请的内存用来储存数据的类型)malloc(申请的内存空间大小)。创建好链表时,要将指针初始化,一般指针的初始化都是初始化为NULL,以链表的结尾。
四、创建节点
(一) 创建新节点函数
Node *CreateNode(int data) { Node *newNode = (Node *)malloc(sizeof(Node)); newNode->data = data; newNode->next = NULL; return newNode; }
创建链表时,我们需要向函数传入参数信息,以代表节点内存储的内容。创建新的节点当然也要新的空间去存储,所以要用malloc函数申请内存。新的链表的指针初始化为NIULL(创建变量及时给变量初始化,以免后续使用时出错)。因为,每次申请的内存时计算分配,并不是连续的,所以链表并不是连续空间的结构。创建完新节点后,这个节点是单独存在的一个结构,与链表并无关联。
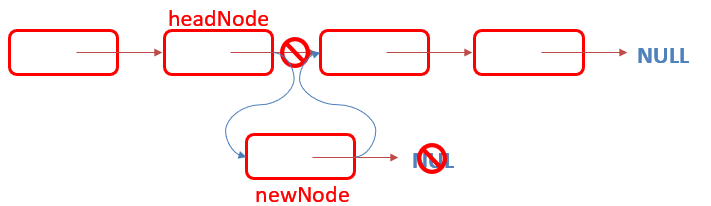
(二) 创建插入节点
void InsertNodeByHead(Node *headNode, int data) { Node *newNode = CreateNode(data); newNode->next = headNode->next; headNode->next = newNode; return; }
插入节点时要将上一个节点的指针指向新创建的节点,并且将新创建的节点的指针指向下一个节点。
五、打印链表
void PrintList(Node *headNode) { Node *pMove = headNode->next; while (pMove) { printf("%d ", pMove->data); pMove = pMove->next; } }
打印链表就是要将链表遍历一遍并且输出其中的内容。在执行while时,每一次循环用pMove的移动读取一个节点,pMove移动过程中就可以选择性输出链表中的内容。由于pMove是循环条件,读取到NULL时,循环结束打印完成。

六、删除节点
void DeleteNodeByAppoin(Node *headNode, int data) { Node *posNode = headNode->next; Node *posNodeFront = headNode; if (posNode == NULL) printf("无法删除链表为空 "); else { while (posNode->data != posNodeFront->data) { posNodeFront = posNode; posNode = posNodeFront->next; if (posNode == NULL) { printf("没有找到相关信息,无法删除 "); return; } } posNodeFront->next = posNode->next; free(posNode); } }
删删除节点此处节点信息作为标识识别删除,找到NULL时表示为空指针,无可删除节点。删除节点时要将上一个链表的指针指向下一个链表以保持链表的连贯性。在删除节点时也要注意链表是否有可删除内容,如果找不到信息就输出错误信息。posNod作为中间变量最后我们要将他所申请的空间释放,缓解内存积压。posNode的作用类似于上述打印链表时使用的pMove 只不过我们在寻找时是在匹配内容,以我们的data为标识寻找。从头节点开始遍历,将posNode指向下一个变量,将posNodeFront指向当前变量,若链表的后面有内容,与删除信息不相符合就往下走,与删除信息相同就让posNodefront直接指向posNode所指向的节点,即可完成对posNodeFront节点的下一个节点的删除。

写在最后
这就是KIrk初学链表的总结啦,要是有问题还请给位readers指出哦!
最后奉上一篇可行代码