
本文独立博客阅读地址:https://ryan4yin.space/posts/iptables-and-container-networks/
本文仅针对 ipv4 网络
iptables 提供了包过滤、NAT 以及其他的包处理能力,iptables 应用最多的两个场景是 firewall 和 NAT
iptables 及新的 nftables 都是基于 netfilter 开发的,是 netfilter 的子项目。
但是 eBPF 社区目前正在开发旨在取代 netfilter 的新项目 bpfilter,他们的目标之一是兼容 iptables/nftables 规则,让我们拭目以待吧。
概念 - 四表五链
实际上还有张 SELinux 相关的 security 表(应该是较新的内核新增的,但是不清楚是哪个版本加的),但是我基本没接触过,就略过了。
实际上还有张 SELinux 相关的 security 表(应该是较新的内核新增的,但是不清楚是哪个版本加的),但是我基本没接触过,就略过了。
详细的说明参见 iptables详解(1):iptables概念 - 朱双印,这篇文章写得非常棒!把 iptables 讲清楚了。
默认情况下,iptables 提供了四张表(不考虑 security 的话)和五条链,数据在这四表五链中的处理流程如下图所示:
在这里的介绍中,可以先忽略掉图中 link layer 层的链路,它属于 ebtables 的范畴。另外
conntrack也暂时忽略,在下一小节会详细介绍 conntrack 的功能。
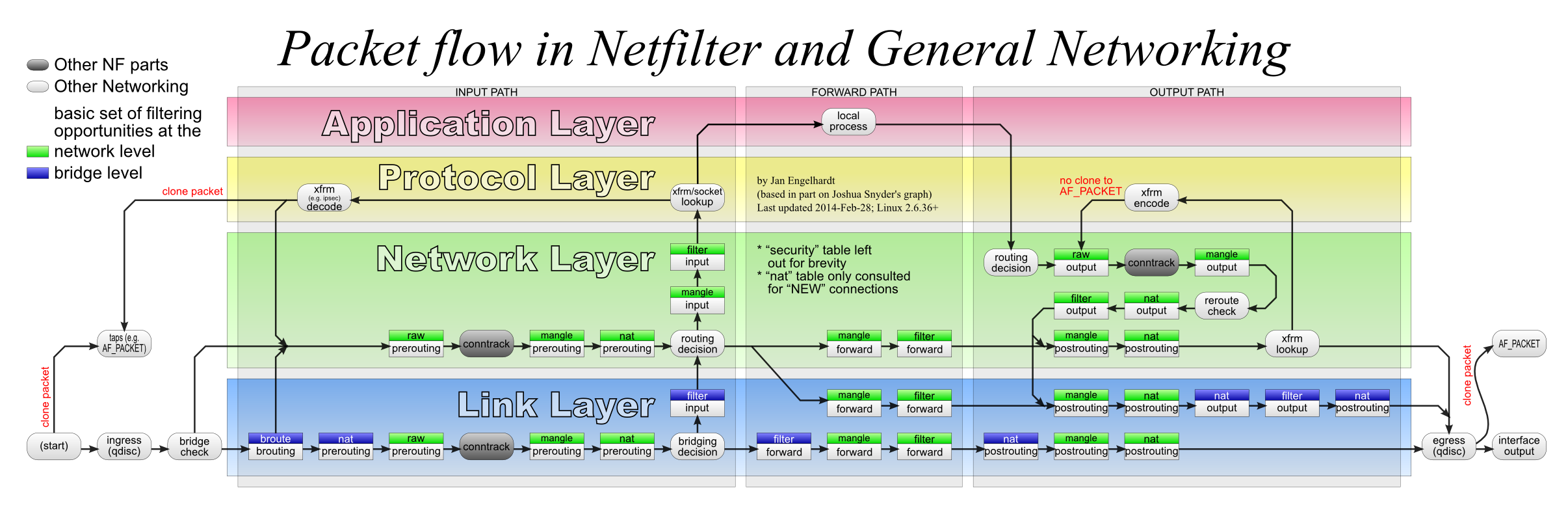
对照上图,对于发送到某个用户层程序的数据而言,流量顺序如下:
- 首先进入 PREROUTING 链,依次经过这三个表: raw -> mangle -> nat
- 然后进入 INPUT 链,这个链上也有三个表,处理顺序是:mangle -> nat -> filter
- 过了 INPUT 链后,数据才会进入内核协议栈,最终到达用户层程序。
用户层程序发出的报文,则依次经过这几个表:OUTPUT -> POSTROUTING
从图中也很容易看出,如果数据 dst ip 不是本机任一接口的 ip,那它通过的几个链依次是:PREROUTEING -> FORWARD -> POSTROUTING
五链的功能和名称完全一致,应该很容易理解。下面按优先级分别介绍下链中的四个表:
- raw: 对收到的数据包在连接跟踪前进行处理。一般用不到,可以忽略
- 一旦用户使用了 RAW 表,RAW 表处理完后,将跳过 NAT 表和 ip_conntrack 处理,即不再做地址转换和数据包的链接跟踪处理了
- mangle: 用于修改报文、给报文打标签
- nat: 主要用于做网络地址转换,SNAT 或者 DNAT
- filter: 主要用于过滤数据包
数据在按优先级经过四个表的处理时,一旦在某个表中匹配到一条规则 A,下一条处理规则就由规则 A 的 target 参数指定,后续的所有表都会被忽略。target 有如下几种类型:
- ACCEPT: 直接允许数据包通过
- DROP: 直接丢弃数据包,对程序而言就是 100% 丢包
- REJECT: 丢弃数据包,但是会给程序返回 RESET。这个对程序更友好,但是存在安全隐患,通常不使用。
- MASQUERADE: (伪装)将 src ip 改写为网卡 ip,和 SNAT 的区别是它会自动读取网卡 ip。路由设备必备。
- SNAT/DNAT: 顾名思义,做网络地址转换
- REDIRECT: 在本机做端口映射
- LOG: 在/var/log/messages文件中记录日志信息,然后将数据包传递给下一条规则,也就是说除了记录以外不对数据包做任何其他操作,仍然让下一条规则去匹配。
- 只有这个 target 特殊一些,匹配它的数据仍然可以匹配后续规则,不会直接跳过。
- 其他类型,可以用到的时候再查
理解了上面这张图,以及四个表的用途,就很容易理解 iptables 的命令了。
常用命令
注意: 下面提供的 iptables 命令做的修改是未持久化的,重启就会丢失!在下一节会简单介绍持久化配置的方法。
命令格式:
iptables [-t table] {-A|-C|-D} chain [-m matchname [per-match-options]] -j targetname [per-target-options]
其中 table 默认为 filter 表,但是感觉系统管理员实际使用最多的是 INPUT 表,用于设置防火墙。
以下简单介绍在 INPUT 表上添加、修改规则,来设置防火墙:
# --add 允许 80 端口通过
iptables -A INPUT -p tcp --dport 80 -j ACCEPT
# --list-rules 查看所有规则
iptables -S
# --list-rules 查看 INPUT 表中的所有规则
iptables -S INPUT
# 查看 iptables 中的所有规则(比 -L 更详细)
# ---delete 通过编号删除规则
iptables -D 1
# 或者通过完整的规则参数来删除规则
iptables -D INPUT -p tcp --dport 80 -j ACCEPT
# --replace 通过编号来替换规则内容
iptables -R INPUT 1 -s 192.168.0.1 -j DROP
# --insert 在指定的位置插入规则,可类比链表的插入
iptables -I INPUT 1 -p tcp --dport 80 -j ACCEPT
# 在匹配条件前面使用感叹号表示取反
# 如下规则表示接受所有来自 docker0,但是目标接口不是 docker0 的流量
iptables -A FORWARD -i docker0 ! -o docker0 -j ACCEPT
# --policy 设置某个链的默认规则
# 很多系统管理员会习惯将连接公网的服务器,默认规则设为 DROP,提升安全性,避免错误地开放了端口。
# 但是也要注意,默认规则设为 DROP 前,一定要先把允许 ssh 端口的规则加上,否则就尴尬了。
iptables -P INPUT DROP
# --flush 清空 INPUT 表上的所有规则
iptables -F INPUT
本文后续分析时,假设用户已经清楚 linux bridge、veth 等虚拟网络接口相关知识。
如果你还缺少这些前置知识,请先阅读文章 Linux 中的虚拟网络接口。
conntrack 连接跟踪与 NAT
在讲 conntrack 之间,我们再回顾下前面给出过的 netfilter 数据处理流程图:
上一节中我们忽略了图中的 conntrack,它就是本节的主角——netfilter 的连接跟踪(connection tracking)模块。
netfilter/conntrack 是 iptables 实现 SNAT/DNAT/MASQUERADE 的前提条件,上面的流程图显示, conntrack 在 PREROUTEING 和 OUTPUT 表的 raw 链之后生效。
下面以 docker 默认的 bridge 网络为例详细介绍下 conntrack 的功能。
首先,这是我在「Linux 的虚拟网络接口」文中给出过的 docker0 网络架构图:
首先,这是我在「Linux 的虚拟网络接口」文中给出过的 docker0 网络架构图:
+-----------------------------------------------+-----------------------------------+-----------------------------------+
| Host | Container A | Container B |
| | | |
| +---------------------------------------+ | +-------------------------+ | +-------------------------+ |
| | Network Protocol Stack | | | Network Protocol Stack | | | Network Protocol Stack | |
| +----+-------------+--------------------+ | +-----------+-------------+ | +------------+------------+ |
| ^ ^ | ^ | ^ |
|........|.............|........................|................|..................|.................|.................|
| v v ↓ | v | v |
| +----+----+ +-----+------+ | +-----+-------+ | +-----+-------+ |
| | .31.101 | | 172.17.0.1 | +------+ | | 172.17.0.2 | | | 172.17.0.3 | |
| +---------+ +-------------<---->+ veth | | +-------------+ | +-------------+ |
| | eth0 | | docker0 | +--+---+ | | eth0(veth) | | | eth0(veth) | |
| +----+----+ +-----+------+ ^ | +-----+-------+ | +-----+-------+ |
| ^ ^ | | ^ | ^ |
| | | +------------------------+ | | |
| | v | | | |
| | +--+---+ | | | |
| | | veth | | | | |
| | +--+---+ | | | |
| | ^ | | | |
| | +------------------------------------------------------------------------------+ |
| | | | |
| | | | |
+-----------------------------------------------+-----------------------------------+-----------------------------------+
v
Physical Network (192.168.31.0/24)
docker 会在 iptables 中为 docker0 网桥添加如下规则:
-t nat -A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-t filter -P DROP
-t filter -A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
这几行规则使 docker 容器能正常访问外部网络。MASQUERADE 在请求出网时,会自动做 SNAT,将 src ip 替换成出口网卡的 ip.
这样数据包能正常出网,而且对端返回的数据包现在也能正常回到出口网卡。
现在问题就来了:出口网卡收到返回的数据包后,还能否将数据包转发到数据的初始来源端——某个 docker 容器?难道 docker 还额外添加了与 MASQUERADE 对应的 dst ip 反向转换规则?
实际上这一步依赖的是本节的主角——iptables 提供的 conntrack 连接跟踪功能(在「参考」中有一篇文章详细介绍了此功能)。
连接跟踪对 NAT 的贡献是:在做 NAT 转换时,无需手动添加额外的规则来执行反向转换以实现数据的双向传输。netfilter/conntrack 系统会记录 NAT 的连接状态,NAT 地址的反向转换是根据这个状态自动完成的。
比如上图中的 Container A 通过 bridge 网络向 baidu.com 发起了 N 个连接,这时数据的处理流程如下:
- 首先
Container A发出的数据包被 MASQUERADE 规则处理,将 src ip 替换成 eth0 的 ip,然后发送到物理网络192..168.31.0/24。- conntrack 系统记录此连接被 NAT 处理前后的状态信息,并将其状态设置为 NEW,表示这是新发起的一个连接
- 对端 baidu.com 返回数据包后,会首先到达 eth0 网卡
- conntrack 查表,发现返回数据包的连接已经记录在表中并且状态为 NEW,于是它将连接的状态修改为 ESTABLISHED,并且将 dst_ip 改为
172.17.0.2然后发送出去- 注意,这个和 tcp 的 ESTABLISHED 没任何关系
- 经过路由匹配,数据包会进入到 docker0,然后匹配上 iptables 规则:
-t filter -A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT,数据直接被放行 - 数据经过 veth 后,最终进入到
Container A中,交由容器的内核协议栈处理。 - 数据被
Container A的内核协议栈发送到「发起连接的应用程序」。
实际测试 conntrack
现在我们来实际测试一下,看看是不是这么回事:
# 使用 tcpdump 分别在出口网卡 wlp4s0 (相当于 eth0)和 dcoker0 网桥上抓包,后面会用来分析
❯ sudo tcpdump -i wlp4s0 -n > wlp4s0.dump # 窗口一,抓 wlp4s0 的包
❯ sudo tcpdump -i docker0 -n > docker0.dump # 窗口二,抓 docker0 的包
现在新建窗口三,启动一个容器,通过 curl 命令低速下载一个视频文件:
❯ docker run --rm --name curl -it curlimages/curl "https://media.w3.org/2010/05/sintel/trailer.mp4" -o /tmp/video.mp4 --limit-rate 100k
然后新建窗口四,在宿主机查看 conntrack 状态
❯ sudo zypper in conntrack-tools # 这个记得先提前安装好
❯ sudo conntrack -L | grep 172.17
# curl 通过 NAT 网络发起了一个 dns 查询请求,DNS 服务器是网关上的 192.168.31.1
udp 17 22 src=172.17.0.4 dst=192.168.31.1 sport=59423 dport=53 src=192.168.31.1 dst=192.168.31.228 sport=53 dport=59423 [ASSURED] mark=0 use=1
# curl 通过 NAT 网络向 media.w3.org 发起了 tcp 连接
tcp 6 298 ESTABLISHED src=172.17.0.4 dst=198.18.5.130 sport=54636 dport=443 src=198.18.5.130 dst=192.168.31.228 sport=443 dport=54636 [ASSURED] mark=0 use=1
等 curl 命令跑个十来秒,然后关闭所有窗口及应用程序,接下来进行数据分析:
# 前面查到的,本地发起请求的端口是 54636,下面以此为过滤条件查询数据
# 首先查询 wlp4s0/eth0 进来的数据,可以看到本机的 dst_ip 为 192.168.31.228.54636
❯ cat wlp4s0.dump | grep 54636 | head -n 15
18:28:28.349321 IP 192.168.31.228.54636 > 198.18.5.130.443: Flags [S], seq 750859357, win 64240, options [mss 1460,sackOK,TS val 3365688110 ecr 0,nop,wscale 7], length 0
18:28:28.350757 IP 198.18.5.130.443 > 192.168.31.228.54636: Flags [S.], seq 2381759932, ack 750859358, win 28960, options [mss 1460,sackOK,TS val 22099541 ecr 3365688110,nop,wscale 5], length 0
18:28:28.350814 IP 192.168.31.228.54636 > 198.18.5.130.443: Flags [.], ack 1, win 502, options [nop,nop,TS val 3365688111 ecr 22099541], length 0
18:28:28.357345 IP 192.168.31.228.54636 > 198.18.5.130.443: Flags [P.], seq 1:518, ack 1, win 502, options [nop,nop,TS val 3365688118 ecr 22099541], length 517
18:28:28.359253 IP 198.18.5.130.443 > 192.168.31.228.54636: Flags [.], ack 518, win 939, options [nop,nop,TS val 22099542 ecr 3365688118], length 0
18:28:28.726544 IP 198.18.5.130.443 > 192.168.31.228.54636: Flags [P.], seq 1:2622, ack 518, win 939, options [nop,nop,TS val 22099579 ecr 3365688118], length 2621
18:28:28.726616 IP 192.168.31.228.54636 > 198.18.5.130.443: Flags [.], ack 2622, win 482, options [nop,nop,TS val 3365688487 ecr 22099579], length 0
18:28:28.727652 IP 192.168.31.228.54636 > 198.18.5.130.443: Flags [P.], seq 518:598, ack 2622, win 501, options [nop,nop,TS val 3365688488 ecr 22099579], length 80
18:28:28.727803 IP 192.168.31.228.54636 > 198.18.5.130.443: Flags [P.], seq 598:644, ack 2622, win 501, options [nop,nop,TS val 3365688488 ecr 22099579], length 46
18:28:28.727828 IP 192.168.31.228.54636 > 198.18.5.130.443: Flags [P.], seq 644:693, ack 2622, win 501, options [nop,nop,TS val 3365688488 ecr 22099579], length 49
18:28:28.727850 IP 192.168.31.228.54636 > 198.18.5.130.443: Flags [P.], seq 693:728, ack 2622, win 501, options [nop,nop,TS val 3365688488 ecr 22099579], length 35
18:28:28.727875 IP 192.168.31.228.54636 > 198.18.5.130.443: Flags [P.], seq 728:812, ack 2622, win 501, options [nop,nop,TS val 3365688488 ecr 22099579], length 84
18:28:28.729241 IP 198.18.5.130.443 > 192.168.31.228.54636: Flags [.], ack 598, win 939, options [nop,nop,TS val 22099579 ecr 3365688488], length 0
18:28:28.729245 IP 198.18.5.130.443 > 192.168.31.228.54636: Flags [.], ack 644, win 939, options [nop,nop,TS val 22099579 ecr 3365688488], length 0
18:28:28.729247 IP 198.18.5.130.443 > 192.168.31.228.54636: Flags [.], ack 693, win 939, options [nop,nop,TS val 22099579 ecr 3365688488], length 0
# 然后再查询 docker0 上的数据,能发现本地的地址为 172.17.0.4.54636
❯ cat docker0.dump | grep 54636 | head -n 20
18:28:28.349299 IP 172.17.0.4.54636 > 198.18.5.130.443: Flags [S], seq 750859357, win 64240, options [mss 1460,sackOK,TS val 3365688110 ecr 0,nop,wscale 7], length 0
18:28:28.350780 IP 198.18.5.130.443 > 172.17.0.4.54636: Flags [S.], seq 2381759932, ack 750859358, win 28960, options [mss 1460,sackOK,TS val 22099541 ecr 3365688110,nop,wscale 5], length 0
18:28:28.350812 IP 172.17.0.4.54636 > 198.18.5.130.443: Flags [.], ack 1, win 502, options [nop,nop,TS val 3365688111 ecr 22099541], length 0
18:28:28.357328 IP 172.17.0.4.54636 > 198.18.5.130.443: Flags [P.], seq 1:518, ack 1, win 502, options [nop,nop,TS val 3365688118 ecr 22099541], length 517
18:28:28.359281 IP 198.18.5.130.443 > 172.17.0.4.54636: Flags [.], ack 518, win 939, options [nop,nop,TS val 22099542 ecr 3365688118], length 0
18:28:28.726578 IP 198.18.5.130.443 > 172.17.0.4.54636: Flags [P.], seq 1:2622, ack 518, win 939, options [nop,nop,TS val 22099579 ecr 3365688118], length 2621
18:28:28.726610 IP 172.17.0.4.54636 > 198.18.5.130.443: Flags [.], ack 2622, win 482, options [nop,nop,TS val 3365688487 ecr 22099579], length 0
18:28:28.727633 IP 172.17.0.4.54636 > 198.18.5.130.443: Flags [P.], seq 518:598, ack 2622, win 501, options [nop,nop,TS val 3365688488 ecr 22099579], length 80
18:28:28.727798 IP 172.17.0.4.54636 > 198.18.5.130.443: Flags [P.], seq 598:644, ack 2622, win 501, options [nop,nop,TS val 3365688488 ecr 22099579], length 46
18:28:28.727825 IP 172.17.0.4.54636 > 198.18.5.130.443: Flags [P.], seq 644:693, ack 2622, win 501, options [nop,nop,TS val 3365688488 ecr 22099579], length 49
18:28:28.727847 IP 172.17.0.4.54636 > 198.18.5.130.443: Flags [P.], seq 693:728, ack 2622, win 501, options [nop,nop,TS val 3365688488 ecr 22099579], length 35
18:28:28.727871 IP 172.17.0.4.54636 > 198.18.5.130.443: Flags [P.], seq 728:812, ack 2622, win 501, options [nop,nop,TS val 3365688488 ecr 22099579], length 84
18:28:28.729308 IP 198.18.5.130.443 > 172.17.0.4.54636: Flags [.], ack 598, win 939, options [nop,nop,TS val 22099579 ecr 3365688488], length 0
18:28:28.729324 IP 198.18.5.130.443 > 172.17.0.4.54636: Flags [.], ack 644, win 939, options [nop,nop,TS val 22099579 ecr 3365688488], length 0
18:28:28.729328 IP 198.18.5.130.443 > 172.17.0.4.54636: Flags [.], ack 693, win 939, options [nop,nop,TS val 22099579 ecr 3365688488], length 0
能看到数据确实在进入 docker0 网桥前,dst_ip 确实被从 192.168.31.228(wlp4s0 的 ip)被修改为了 172.17.0.4(Container A 的 ip).
NAT 如何分配端口?
上一节我们实际测试发现,docker 容器的流量在经过 iptables 的 MASQUERADE 规则处理后,只有 src ip 被修改了,而 port 仍然是一致的。
但是如果 NAT 不修改连接的端口,实际上是会有问题的。如果有两个容器同时向 ip: 198.18.5.130, port: 443 发起请求,又恰好使用了同一个 src port,在宿主机上就会出现端口冲突!
因为这两个请求被 SNAT 时,如果只修改 src ip,那它们映射到的将是主机上的同一个连接!
这个问题 NAT 是如何解决的呢?我想如果遇到这种情况,NAT 应该会通过一定的规则选用一个不同的端口。
有空可以翻一波源码看看这个,待续...
如何持久化 iptables 配置
首先需要注意的是,centos7/opensuse 15 都已经切换到了 firewalld 作为防火墙配置软件,
而 ubuntu18.04 lts 也换成了 ufw 来配置防火墙。
包括 docker 应该也是在启动的时候动态添加 iptables 配置。
对于上述新系统,还是建议直接使用 firewalld/ufw 配置防火墙吧,或者网上搜下关闭 ufw/firewalld、启用 iptables 持久化的解决方案。
本文主要目的在于理解 docker 容器网络的原理,以及为后面理解 kubernetes 网络插件 calico/flannel 打好基础,因此就不多介绍持久化了。
Docker 如何使用 iptables + 虚拟网络接口实现容器网络
通过 docker run 运行容器
首先,使用 docker run 运行几个容器,检查下网络状况:
# 运行一个 debian 容器和一个 nginx
❯ docker run -dit --name debian --rm debian:buster sleep 1000000
❯ docker run -dit --name nginx --rm nginx:1.19-alpine
# 查看网络接口,有两个 veth 接口(而且都没设 ip 地址),分别连接到两个容器的 eth0(dcoker0 网络架构图前面给过了,可以往前面翻翻对照下)
❯ ip addr ls
...
5: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:42:c7:12:ba brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:42ff:fec7:12ba/64 scope link
valid_lft forever preferred_lft forever
100: veth16b37ea@if99: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 42:af:34:ae:74:ae brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::40af:34ff:feae:74ae/64 scope link
valid_lft forever preferred_lft forever
102: veth4b4dada@if101: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 9e:f1:58:1a:cf:ae brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::9cf1:58ff:fe1a:cfae/64 scope link
valid_lft forever preferred_lft forever
# 两个 veth 接口都连接到了 docker0 上面,说明两个容器都使用了 docker 默认的 bridge 网络
❯ sudo brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.024242c712ba no veth16b37ea
veth4b4dada
# 查看路由规则
❯ ip route ls
default via 192.168.31.1 dev wlp4s0 proto dhcp metric 600
#下列路由规则将 `172.17.0.0/16` 网段的所有流量转发到 docker0
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
192.168.31.0/24 dev wlp4s0 proto kernel scope link src 192.168.31.228 metric 600
# 查看 iptables 规则
# NAT 表
❯ sudo iptables -t nat -S
-P PREROUTING ACCEPT
-P INPUT ACCEPT
-P OUTPUT ACCEPT
-P POSTROUTING ACCEPT
-N DOCKER
# 所有目的地址在本机的,都先交给 DOCKER 链处理一波
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
# (容器访问外部网络)所有出口不为 docker0 的流量,都做下 SNAT,把 src ip 换成出口接口的 ip 地址
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
-A DOCKER -i docker0 -j RETURN
# filter 表
❯ sudo iptables -t filter -S
-P INPUT ACCEPT
-P FORWARD DROP
-P OUTPUT ACCEPT
-N DOCKER
-N DOCKER-ISOLATION-STAGE-1
-N DOCKER-ISOLATION-STAGE-2
-N DOCKER-USER
# 所有流量都必须先经过如下两个表处理,没问题才能继续往下走
-A FORWARD -j DOCKER-ISOLATION-STAGE-1
-A FORWARD -j DOCKER-USER
# (容器访问外部网络)出去的流量走了 MASQUERADE,回来的流量会被 conntrack 识别并转发回来,这里允许返回的数据包通过。
# 这里直接 ACCEPT 被 conntrack 识别到的流量
-A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
# 将所有访问 docker0 的流量都转给自定义链 DOCKER 处理
-A FORWARD -o docker0 -j DOCKER
# 允许所有来自 docker0 的流量通过,不论下一跳是否是 docker0
-A FORWARD -i docker0 ! -o docker0 -j ACCEPT
-A FORWARD -i docker0 -o docker0 -j ACCEPT
# 下面三个表目前啥规则也没有,就是简单的 RETURN,交给后面的表继续处理
-A DOCKER-ISOLATION-STAGE-1 -j RETURN
-A DOCKER-ISOLATION-STAGE-2 -j RETURN
-A DOCKER-USER -j RETURN
接下来使用如下 docker-compose 配置启动一个 caddy 容器,添加自定义 network 和端口映射,待会就能验证 docker 是如何实现这两种网络的了。
docker-compose.yml 内容:
version: "3.3"
services:
caddy:
image: "caddy:2.2.1-alpine"
container_name: "caddy"
restart: always
command: caddy file-server --browse --root /data/static
ports:
- "8081:80"
volumes:
- "/home/ryan/Downloads:/data/static"
networks:
- caddy-1
networks:
caddy-1:
现在先用上面的配置启动 caddy 容器,然后再查看网络状况:
# 启动 caddy
❯ docker-compose up -d
# 查下 caddy 容器的 ip
> docker inspect caddy | grep IPAddress
...
"IPAddress": "172.18.0.2",
# 查看网络接口,可以看到多了一个网桥,它就是上一行命令创建的 caddy-1 网络
# 还多了一个 veth,它连接到了 caddy 容器的 eth0(veth) 接口
❯ ip addr ls
...
5: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:42:c7:12:ba brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:42ff:fec7:12ba/64 scope link
valid_lft forever preferred_lft forever
100: veth16b37ea@if99: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 42:af:34:ae:74:ae brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::40af:34ff:feae:74ae/64 scope link
valid_lft forever preferred_lft forever
102: veth4b4dada@if101: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 9e:f1:58:1a:cf:ae brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::9cf1:58ff:fe1a:cfae/64 scope link
valid_lft forever preferred_lft forever
103: br-ac3e0514d837: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:7d:95:ba:7e brd ff:ff:ff:ff:ff:ff
inet 172.18.0.1/16 brd 172.18.255.255 scope global br-ac3e0514d837
valid_lft forever preferred_lft forever
inet6 fe80::42:7dff:fe95:ba7e/64 scope link
valid_lft forever preferred_lft forever
105: veth0c25c6f@if104: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br-ac3e0514d837 state UP group default
link/ether 9a:03:e1:f0:26:ea brd ff:ff:ff:ff:ff:ff link-netnsid 2
inet6 fe80::9803:e1ff:fef0:26ea/64 scope link
valid_lft forever preferred_lft forever
# 查看网桥,能看到 caddy 容器的 veth 接口连在了 caddy-1 这个网桥上,没有加入到 docker0 网络
❯ sudo brctl show
bridge name bridge id STP enabled interfaces
br-ac3e0514d837 8000.02427d95ba7e no veth0c25c6f
docker0 8000.024242c712ba no veth16b37ea
veth4b4dada
# 查看路由,能看到新网桥使用的地址段是 172.18.0.0/16,是 docker0 递增上来的
❯ ip route ls
default via 192.168.31.1 dev wlp4s0 proto dhcp metric 600
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
# 多了一个网桥的
172.18.0.0/16 dev br-ac3e0514d837 proto kernel scope link src 172.18.0.1
192.168.31.0/24 dev wlp4s0 proto kernel scope link src 192.168.31.228 metric 600
# iptables 中也多了 caddy-1 网桥的 MASQUERADE 规则,以及端口映射的规则
❯ sudo iptables -t nat -S
-P PREROUTING ACCEPT
-P INPUT ACCEPT
-P OUTPUT ACCEPT
-P POSTROUTING ACCEPT
-N DOCKER
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
-A POSTROUTING -s 172.18.0.0/16 ! -o br-ac3e0514d837 -j MASQUERADE
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE
# 端口映射过来的入网流量,都做下 SNAT,把 src ip 换成出口 docker0 的 ip 地址
-A POSTROUTING -s 172.18.0.2/32 -d 172.18.0.2/32 -p tcp -m tcp --dport 80 -j MASQUERADE
-A DOCKER -i br-ac3e0514d837 -j RETURN
-A DOCKER -i docker0 -j RETURN
# 主机上所有其他接口进来的 tcp 流量,只要目标端口是 8081,就转发到 caddy 容器去(端口映射)
# DOCKER 是被 PREROUTEING 链的 target,因此这会导致流量直接走了 FORWARD 链,直接绕过了通常设置在 INPUT 链的主机防火墙规则!
-A DOCKER ! -i br-ac3e0514d837 -p tcp -m tcp --dport 8081 -j DNAT --to-destination 172.18.0.2:80
❯ sudo iptables -t filter -S
-P INPUT ACCEPT
-P FORWARD DROP
-P OUTPUT ACCEPT
-N DOCKER
-N DOCKER-ISOLATION-STAGE-1
-N DOCKER-ISOLATION-STAGE-2
-N DOCKER-USER
-A FORWARD -j DOCKER-USER
-A FORWARD -j DOCKER-ISOLATION-STAGE-1
# 给 caddy-1 bridge 网络添加的转发规则,与 docker0 的规则完全一一对应,就不多介绍了。
-A FORWARD -o br-ac3e0514d837 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o br-ac3e0514d837 -j DOCKER
-A FORWARD -i br-ac3e0514d837 ! -o br-ac3e0514d837 -j ACCEPT
-A FORWARD -i br-ac3e0514d837 -o br-ac3e0514d837 -j ACCEPT
-A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o docker0 -j DOCKER
-A FORWARD -i docker0 ! -o docker0 -j ACCEPT
-A FORWARD -i docker0 -o docker0 -j ACCEPT
# 这一条仍然是端口映射相关的规则,接受所有从其他接口过来的,请求 80 端口且出口是 caddy-1 网桥的流量
-A DOCKER -d 172.18.0.2/32 ! -i br-ac3e0514d837 -o br-ac3e0514d837 -p tcp -m tcp --dport 80 -j ACCEPT
# 当存在多个 bridge 网络的时候,docker 就会在下面两个 STAGE 链中处理将它们隔离开,禁止互相访问
-A DOCKER-ISOLATION-STAGE-1 -i br-ac3e0514d837 ! -o br-ac3e0514d837 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -j RETURN
# 这里延续上面 STAGE-1 的处理,彻底隔离两个网桥的流量
-A DOCKER-ISOLATION-STAGE-2 -o br-ac3e0514d837 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -j RETURN
-A DOCKER-USER -j RETURN
到这里,我们简单地分析了下 docker 如何通过 iptables 实现 bridge 网络和端口映射。
有了这个基础,后面就可以尝试深入分析 kubernetes 网络插件 flannel/calico/cilium 了哈哈。
Rootless 容器的网络实现
如果容器运行时也在 Rootless 模式下运行,那它就没有权限在宿主机添加 bridge/veth 等虚拟网络接口,这种情况下,我们前面描述的容器网络就无法设置了。
那么 podman/containerd(nerdctl) 目前是如何在 Rootless 模式下构建容器网络的呢?
查看文档,发现它们都用到了 rootlesskit 相关的东西,而 rootlesskit 提供了 rootless 网络的几个实现,文档参见 rootlesskit/docs/network.md
其中目前推荐使用,而且 podman/containerd(nerdctl) 都默认使用的方案,是 rootless-containers/slirp4netns
以 containerd(nerdctl) 为例,按官方文档安装好后,随便启动几个容器,然后在宿主机查 iptables/ip addr ls,会发现啥也没有。
这显然是因为 rootless 模式下 containerd 改不了宿主机的 iptables 配置和虚拟网络接口。但是可以查看到宿主机 slirp4netns 在后台运行:
❯ ps aux | grep tap
ryan 11644 0.0 0.0 5288 3312 ? S 00:01 0:02 slirp4netns --mtu 65520 -r 3 --disable-host-loopback --enable-sandbox --enable-seccomp 11625 tap0
但是我看半天文档,只看到怎么使用 rootlesskit/slirp4netns 创建新的名字空间,没看到有介绍如何进入一个已存在的 slirp4netns 名字空间...
使用 nsenter -a -t 11644 也一直报错,任何程序都是 no such binary...
以后有空再重新研究一波...
总之能确定的是,它通过在虚拟的名字空间中创建了一个 tap 虚拟接口来实现容器网络,性能相比前面介绍的网络多少是要差一点的。
nftables
前面介绍了 iptables 以及其在 docker 和防火墙上的应用。但是实际上目前各大 Linux 发行版都已经不建议使用 iptables 了,甚至把 iptables 重命名为了 iptables-leagacy.
目前 opensuse/debian/opensuse 都已经预装了并且推荐使用 nftables,而且 firewalld 已经默认使用 nftables 作为它的后端了。
我在 opensuse tumbleweed 上实测,firewalld 添加的是 nftables 配置,而 docker 仍然在用旧的 iptables,也就是说我现在的机器上有两套 netfilter 工具并存:
# 查看 iptables 数据
> iptables -S
-P INPUT ACCEPT
-P FORWARD DROP
-P OUTPUT ACCEPT
-N DOCKER
-N DOCKER-ISOLATION-STAGE-1
-N DOCKER-ISOLATION-STAGE-2
-N DOCKER-USER
-A FORWARD -j DOCKER-ISOLATION-STAGE-1
-A FORWARD -o br-e3fbbb7a1b3a -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o br-e3fbbb7a1b3a -j DOCKER
...
# 确认下是否使用了 nftables 的兼容层,结果提示请我使用 iptables-legacy
> iptables-nft -S
# Warning: iptables-legacy tables present, use iptables-legacy to see them
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPT
# 查看 nftables 规则,能看到三张 firewalld 生成的 table
> nft list ruleset
table inet firewalld {
...
}
table ip firewalld {
...
}
table ip6 firewalld {
...
}
但是现在 kubernetes/docker 都还是用的 iptables,nftables 我学了用处不大,以后有空再补充。