20190529更新
1 增加测试用例
2 修复中文查找可能导致越界的bug
3 strstr改为不使用二分(效率会慢一些,但匹配结果相对可控),推荐使用strstrs_ext
==================================================================================
20190529:windows上建议使用strstrs_ext,linux上在数据不匹配的场景好像strstrs_normal更快一点。我把测试效率代码附上,有需要的可以自己验证。
从我自己测试的效率对比猜测,linux上gcc的strstr应该不是普通的暴力匹配法,网上的说法不正确。
==================================================================================
平时项目中有时需要用到在字符串中搜索两个或更多的关键字的情景。例如:将字符串"ab|cd#ef|"按竖线或者井号做分隔
如果是大项目,一般会采用正则表达式做处理。但有时写个小程序,不想因此引进一个正则库,所以我自己写了一个支持多关键字版本的字符串查找函数strstrs
函数说明:
1 #include <stdio.h> 2 #include <windows.h> 3 4 #ifndef IN 5 #define IN 6 #endif 7 8 //函数说明:在字符串中搜索指定的关键字,支持1-nCnt个关键字 9 //strToFind 待查找字符串 不允许为空 10 //strKeywords 搜索关键字字符串数组 不允许为空 数组元素不允许为空(NULL),但可以是空串("") 11 //nCnt 关键字个数 12 //pFound 查找到的关键字在字符串数组的位置 不允许为空 13 //返回值: 14 //1 如果关键字存在空串,则返回strToFind 15 //2 如果找不到关键字则返回NULL 16 //3 如果找到关键字,则返回关键字在strKeywords中的位置(位置从0开始) 17 18 //使用哈希加二分查找实现 19 const char *strstrs(const char *strToFind, IN char *strKeywords[], size_t nCnt, int *pFound); 20 //使用哈希加链接实现 推荐使用 21 const char *strstrs_ext(const char *strToFind, IN char *strKeywords[], size_t nCnt, int *pFound); 22 //依次查找关键字的实现 23 const char *strstrs_normal(const char *strToFind, IN char *strKeywords[], size_t nCnt, int *pFound); 24 25 //以下是为了使用方便而增加的一些重载,没多大意义 26 char *strstrs(IN char *strToFind, IN char *strKeywords[], size_t nCnt, int *pFound); 27 char *strstrs_ext(IN char *strToFind, IN char *strKeywords[], size_t nCnt, int *pFound); 28 char *strstrs_normal(IN char *strToFind, IN char *strKeywords[], size_t nCnt, int *pFound); 29 30 char *strstrs(IN char *strToFind, const char *strKeywords[], size_t nCnt, int *pFound); 31 char *strstrs_ext(IN char *strToFind, const char *strKeywords[], size_t nCnt, int *pFound); 32 char *strstrs_normal(IN char *strToFind, const char *strKeywords[], size_t nCnt, int *pFound); 33 34 const char *strstrs(const char *strToFind, const char *strKeywords[], size_t nCnt, int *pFound); 35 const char *strstrs_ext(const char *strToFind, const char *strKeywords[], size_t nCnt, int pFound); 36 const char *strstrs_normal(const char *strToFind, const char *strKeywords[], size_t nCnt, int *pFound); 37 void tets_strstrs(int nStep); // 0 strstrs 1 strstrs_ext 2 strstrs_normal
函数实现及相应测试代码:
// stdafx.cpp : source file that includes just the standard includes // sqlite_test.pch will be the pre-compiled header // stdafx.obj will contain the pre-compiled type information #include "stdafx.h" #include <assert.h> #include <stdlib.h> #include <time.h> #include <stdio.h> // TODO: reference any additional headers you need in STDAFX.H // and not in this file const char *strstrs(const char *strToFind, const char *strKeywords[], size_t nCnt, int *pFound) { return strstrs(const_cast<char *>(strToFind), strKeywords, nCnt, pFound); } const char *strstrs_ext(const char *strToFind, const char *strKeywords[], size_t nCnt, int *pFound) { return strstrs_ext(const_cast<char *>(strToFind), strKeywords, nCnt, pFound); } const char *strstrs_normal(const char *strToFind, const char *strKeywords[], size_t nCnt, int *pFound) { return strstrs_normal(const_cast<char *>(strToFind), strKeywords, nCnt, pFound); } const char *strstrs(const char *strToFind, IN char *strKeywords[], size_t nCnt, int *pFound) { return strstrs(const_cast<char *>(strToFind), (const char **)strKeywords, nCnt, pFound); } const char *strstrs_ext(const char *strToFind, IN char *strKeywords[], size_t nCnt, int *pFound) { return strstrs_ext(const_cast<char *>(strToFind), (const char **)strKeywords, nCnt, pFound); } const char *strstrs_normal(const char *strToFind, IN char *strKeywords[], size_t nCnt, int *pFound) { return strstrs_normal(const_cast<char *>(strToFind), (const char **)strKeywords, nCnt, pFound); } char *strstrs(IN char *strToFind, IN char *strKeywords[], size_t nCnt, int *pFound) { return strstrs(const_cast<char *>(strToFind), (const char **)strKeywords, nCnt, pFound); } char *strstrs_ext(IN char *strToFind, IN char *strKeywords[], size_t nCnt, int *pFound) { return strstrs_ext(const_cast<char *>(strToFind), (const char **)strKeywords, nCnt, pFound); } char *strstrs_normal(IN char *strToFind, IN char *strKeywords[], size_t nCnt, int *pFound) { return strstrs_normal(const_cast<char *>(strToFind), (const char **)strKeywords, nCnt, pFound); } typedef struct tagKeyPos { const char *m_str; size_t m_nIdx; size_t m_strLen; }KeyPos; int __strstrs_cmp(const void *p1, const void *p2) { const KeyPos *pLeft = (KeyPos *)p1, *pRight = (KeyPos *)p2; int nCmp = strcmp(pLeft->m_str, pRight->m_str); if (nCmp == 0) { return pLeft->m_nIdx - pRight->m_nIdx; } return nCmp; } /* //lower_bound KeyPos *__strstrs_find_first(KeyPos *pRealBeg, KeyPos *pRealEnd, size_t *pKeyLenArr, KeyPos *pKey) { KeyPos *pBeg = pRealBeg; KeyPos *pEnd = pRealEnd; KeyPos *pEqal = NULL; while (pBeg != pEnd) { pEqal = pBeg + (pEnd - pBeg) / 2; int nCmp = memcmp( pEqal->m_str, pKey->m_str, pEqal->m_strLen ); if (nCmp == 0) { //若相等,则往前找,直至找到最后一个相等的元素 while (pEqal != pBeg) { pEqal--; if (memcmp( pEqal->m_str, pKey->m_str, pEqal->m_strLen )) { return pEqal + 1; } } return pBeg; } else if (nCmp > 0) { //中值比目标值大 pEnd = pEqal; } else { //中值比目标值小 pBeg = pEqal + 1; } } return pRealEnd; } */ KeyPos *__strstrs_find_first(KeyPos *pRealBeg, KeyPos *pRealEnd, size_t *pKeyLenArr, KeyPos *pKey) { KeyPos *pBeg = pRealBeg; KeyPos *pEnd = pRealEnd; while (pBeg != pEnd) { int nCmp = memcmp( pBeg->m_str, pKey->m_str, pBeg->m_strLen ); if (nCmp == 0) { return pBeg; } ++pBeg; } return pRealEnd; } char *strstrs(char *strToFind, const char *strKeywords[], size_t nCnt, int *pFound) { //作者:皇家救星 创建于:2016-10-19 //有bug请发送邮件至89475049@qq.com 邮件主题注明:strstrs问题反馈 //异常参数判断 assert(strToFind != NULL); assert(strKeywords != NULL); assert(pFound != NULL); assert(nCnt > 0); //记录各个关键字首字符到集合中 后面判断用 bool mpFirstChar[256] = {0}; //这里如果用位图,可以节省不少空间 for (size_t i = 0; i < nCnt; i++) { //linux和win的char类型定义不一样 这里统一强制转换一下 assert(strKeywords[i] != NULL); //使用unsigned char 确保char类型是负数时强制转换不会超过256而越界 mpFirstChar[(unsigned char)strKeywords[i][0]] = true; if (strKeywords[i][0] == '�') { *pFound = i; return strToFind; } } KeyPos *sortKeywords = new KeyPos[nCnt]; for (size_t i = 0; i < nCnt; ++i) { sortKeywords[i].m_str = strKeywords[i]; sortKeywords[i].m_strLen = strlen(strKeywords[i]); sortKeywords[i].m_nIdx = i; } //不能排序,会导致关键字位置混乱 //qsort(sortKeywords, nCnt, sizeof(KeyPos), __strstrs_cmp); //使用unsigned char 确保char类型是负数时强制转换不会超过256而越界 unsigned char *p = (unsigned char *)strToFind; KeyPos key; KeyPos *pEnd = sortKeywords + nCnt; KeyPos *pResult = NULL; while (*p) { //判断当前字符是否在关键串首字符集中 if (mpFirstChar[*p]) { key.m_str = (char *)p; pResult = __strstrs_find_first(sortKeywords, pEnd, NULL, &key); if (pResult != pEnd) { *pFound = pResult->m_nIdx; delete []sortKeywords; return reinterpret_cast<char *>(p); } } p++; } delete []sortKeywords; return NULL; } typedef struct tagKeyPosExt { size_t m_strLen; size_t m_strIdx; struct tagKeyPosExt *m_next; }KeyPosExt; char *strstrs_ext(char *strToFind, const char *strKeywords[], size_t nCnt, int *pFound) { //作者:皇家救星 创建于:2016-10-19 //有bug请发送邮件至89475049@qq.com 邮件主题注明:strstrs问题反馈 //20190522 修改字符串有中文会导致内存访问异常的bug //异常参数判断 assert(strToFind != NULL); assert(strKeywords != NULL); assert(pFound != NULL); assert(nCnt > 0); //仿内存池 减少new调用次数 KeyPosExt *memPool = new KeyPosExt[nCnt]; //注意:memPool分配失败会抛异常 memset(memPool, 0, nCnt * sizeof(KeyPosExt)); int nUsed = 0; //记录各个关键字首字符到集合中 后面判断用 KeyPosExt mpFirstChar[256]; memset(mpFirstChar, 0, sizeof(mpFirstChar)); for (size_t i = nCnt - 1; i != (size_t)-1; --i) { KeyPosExt *pPos = &memPool[nUsed++]; //如果同一个首字符对应多个关键字,则用链表连起来 assert(strKeywords[i] != NULL); pPos->m_strIdx = i; pPos->m_strLen = strlen(strKeywords[i]); if (pPos->m_strLen == 0) { *pFound = i; delete []memPool; return strToFind; } //把新的节点插到最前面 //使用unsigned char 确保char类型是负数时强制转换不会超过256而越界 KeyPosExt *pLast = &mpFirstChar[(unsigned char)strKeywords[i][0]]; pPos->m_next = pLast->m_next; pLast->m_next = pPos; } //使用unsigned char 确保char类型是负数时强制转换不会超过256而越界 unsigned char *p = (unsigned char *) strToFind; while (*p) { //判断当前字符是否在关键串首字符集中 for (KeyPosExt *pPos = mpFirstChar[*p].m_next; pPos != NULL; pPos = pPos->m_next) { //遍历以当前字符开头的关键串,挨个比较 看是否有匹配的 if (memcmp(p, strKeywords[pPos->m_strIdx], pPos->m_strLen) == 0) { *pFound = pPos->m_strIdx; delete []memPool; return reinterpret_cast<char *>(p); } } p++; } delete []memPool; return NULL; } char *strstrs_normal(char *strToFind, const char *strKeywords[], size_t nCnt, int *pFound) { //作者:皇家救星 创建于:2016-10-19 //有bug请发送邮件至89475049@qq.com 邮件主题注明:strstrs问题反馈 //20190522 修改字符串有中文会导致内存访问异常的bug //异常参数判断 assert(strToFind != NULL); assert(strKeywords != NULL); assert(pFound != NULL); assert(nCnt > 0); char *p = NULL; for (size_t i = 0; i < nCnt; i++) { assert(strKeywords[i] != NULL); if (strKeywords[i][0] == '�') { *pFound = i; return strToFind; } } for (size_t i = 0; i < nCnt; i++) { assert(strKeywords[i] != NULL); if ((p = strstr(strToFind, strKeywords[i])) != NULL) { *pFound = i; return p; } } return NULL; } //准确性测试 int tets_strstrs1() { const char *strKeywords[] = {"123", "select", "union", "or", "customer", "subsid", "2455", "group_id", "test", "from", "truncate", "s", "english1", "2222222222222222888888888888833300", "皇家"}; const char *strSqls[] = { "select * from dual", "drop table", "truncate", "english", "goodby", "get 123", "123 get", " from" "D", "s", "89sfs89", "or", "sor", "orunion", "unionor", "83eejr3r9r9r33302002013345331224312343", "去9999给", "去皇家救星给" }; for (int i = 0; i < sizeof(strSqls) / sizeof(strSqls[0]); ++i) { bool bFoundNormal = false; int nFoundNormal = 0; if (NULL != strstrs_normal(strSqls[i], strKeywords, sizeof(strKeywords) / sizeof(strKeywords[0]), &nFoundNormal)) { bFoundNormal = true; } bool bFoundExt = false; int nFoundExt = 0; if (NULL != strstrs_ext(strSqls[i], strKeywords, sizeof(strKeywords) / sizeof(strKeywords[0]), &nFoundExt)) { bFoundExt = true; } bool bFound = false; int nFound = 0; if (NULL != strstrs(strSqls[i], strKeywords, sizeof(strKeywords) / sizeof(strKeywords[0]), &nFound)) { bFound = true; } if ((bFound != bFoundExt || bFound != bFoundNormal) || (nFound != nFoundExt /*|| nFound != nFoundNormal*/)) { printf("error! strSqls[i] = [%s] ", strSqls[i]); printf("bFound = %d nFound = %d ", bFound, nFound); printf("bFoundNormal = %d nFoundNormal = %d ", bFoundNormal, nFoundNormal); printf("bFoundExt = %d nFoundExt = %d ", bFoundExt, nFoundExt); return -1 - i * 10; } } return 0; } //效率比较及准确性测试函数 void tets_strstrs(int nStep) { const int max_length = 10000; //max_length必须大于1024 const int max_keyword = 1000; char *strToFound = new char[max_length + 1]; //待查找的字符串 char *strBackup = new char[max_length + 1]; char *strKeywords[max_keyword]; //关键字数组 const char strBase64[65] = {"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"}; //为避免结果全是找不到关键字,随机将一个关键字复制到strToFound中 //这样肯定会有找到关键字的情况,结果更有意义 bool arrayFoundFlags[max_keyword] = {0}; //标记是否把关键字复制到strToFound中 int arrayFoundIdxs[max_keyword] = {0}; //待替换的关键字(序号) int arrayFoundBeg[max_keyword] = {0}; //在strToFound替换关键字的起始位置 if (tets_strstrs1() != 0) { printf("函数功能验证失败 "); return; } srand((int)time(NULL)); //初始化要查询的字符串 for (int i = 0; i < max_length; i++) { strToFound[i] = strBase64[rand() % 64]; } strToFound[max_length] = '�'; fprintf(stderr, "strToFound = [%s] ", strToFound); //初始化查询关键字 for (int i = 0; i < max_keyword; i++) { size_t nKeyLen = max_length / 4; size_t nKeyLenMin = 50; strKeywords[i] = new char[nKeyLen + 1]; if (nKeyLen < nKeyLenMin) { fprintf(stderr, "max_length is too small "); exit(1); } int nLen = rand() % (nKeyLen - nKeyLenMin) + nKeyLenMin; for (int j = 0; j < nLen; j++) { strKeywords[i][j] = strBase64[rand() % 64]; } strKeywords[i][nLen] = '�'; //为避免随机结果都是查不到的情况,这里增加一些干预 //if (0 != (rand() % 10)) // { // //随机抽取约9/10的关键字 复制到待查字符串中 // arrayFoundFlags[i] = true; // arrayFoundIdxs[i] = rand() % (i + 1); // arrayFoundBeg[i] = 0; // } fprintf(stderr, "strKeywords[%d] = [%s] ", i, strKeywords[i]); fprintf(stderr, "%d: %d %d %d ", i, arrayFoundFlags[i], arrayFoundIdxs[i], arrayFoundBeg[i]); } fflush(stderr); printf("RESULT: 函数类型 关键字总数 总耗时 总共找到次数 "); for (int cmpType = 0; cmpType < 3; cmpType++) { int nSn = 0; double total_start = GetTickCount(); for (size_t nCnt = 0; nCnt < max_keyword; nCnt++) { bool bSetFound = arrayFoundFlags[nCnt]; int nBeg = 0; int nChange = 0; int idxKeyword = 0; if (bSetFound) { //把关键字替换到字符串中 这样能保证字符串肯定包含想要的字符串 idxKeyword = arrayFoundIdxs[nCnt]; nChange = strlen(strKeywords[idxKeyword]); nBeg = arrayFoundBeg[nCnt]; memcpy(strBackup, strToFound + nBeg, nChange); strBackup[nChange] = '�'; memcpy(strToFound + nBeg, strKeywords[idxKeyword], nChange); } double start = GetTickCount(); int nFoundCnt = 0; //待查字符串从短到长 for (int nStrlen = 0; nStrlen < max_length; nStrlen += nStep) { //末尾要有� 所以这里行把末尾字符备份起来 用�覆盖 后面调用strstrs后再替换回去 char cBak = strToFound[nStrlen]; strToFound[nStrlen] = '�'; int nFound = -1; const char *p; switch (cmpType) { case 0: p = strstrs(strToFound, strKeywords, nCnt + 1, &nFound); break; case 1: p = strstrs_ext(strToFound, strKeywords, nCnt + 1, &nFound); break; default: p = strstrs_normal(strToFound, strKeywords, nCnt + 1, &nFound); break; } //fprintf(stderr, "cmpType %d %d %d ", cmpType, nSn, nFound); nSn++; if (p != NULL) { nFoundCnt++; } else { //假设明明有把关键字拷进去但还是返回找不到,说明结果有问题 if (bSetFound && ((nBeg + nChange) <= nStrlen)) { printf("cmpType = %d ###############################error! ", cmpType); printf("strToFound = [%s], nStrlen = %d, nCnt = %d ", strToFound, nStrlen, nCnt); printf("strKeywords[arrayFoundIdxs[nCnt]] = [%s], nBeg = %d, nChange = %d ", strKeywords[arrayFoundIdxs[nCnt]], nBeg, nChange); exit(10); // switch (cmpType) // { // case 0: // p = strstrs(strToFound, strKeywords, nCnt + 1, &nFound); // break; // case 1: // p = strstrs_ext(strToFound, strKeywords, nCnt + 1, &nFound); // break; // default: // p = strstrs_normal(strToFound, strKeywords, nCnt + 1, &nFound); // break; // } } } strToFound[nStrlen] = cBak; } double end = GetTickCount(); //函数类型 关键字序列 耗时 总共找到次数 printf("RESULT: %d %d %f %d ", cmpType, nCnt + 1, end - start, nFoundCnt); fflush(stdout); fflush(stderr); // if (nFoundCnt == 499) // { // printf("pre strToFound = [%s], strBackup = [%s], nCnt = %d nBeg %d nChange %d idxKeyword %d strKeywords[idxKeyword] %s ", // strToFound, strBackup, nCnt, nBeg, nChange, idxKeyword, strKeywords[idxKeyword]); // } if (bSetFound) { memcpy(strToFound + nBeg, strBackup, nChange); } // // if (nFoundCnt == 499) // { // printf("strToFound = [%s], nCnt = %d nBeg %d nChange %d idxKeyword %d ", strToFound, nCnt, nBeg, nChange, idxKeyword); // } } double total_end = GetTickCount(); fprintf(stderr, "总共耗时[%f] ", total_end - total_start); } //TODO: 此处应该要释放内存 delete []strToFound; delete []strBackup; for (int i = 0; i < max_keyword; i++) { delete []strKeywords[i]; } }
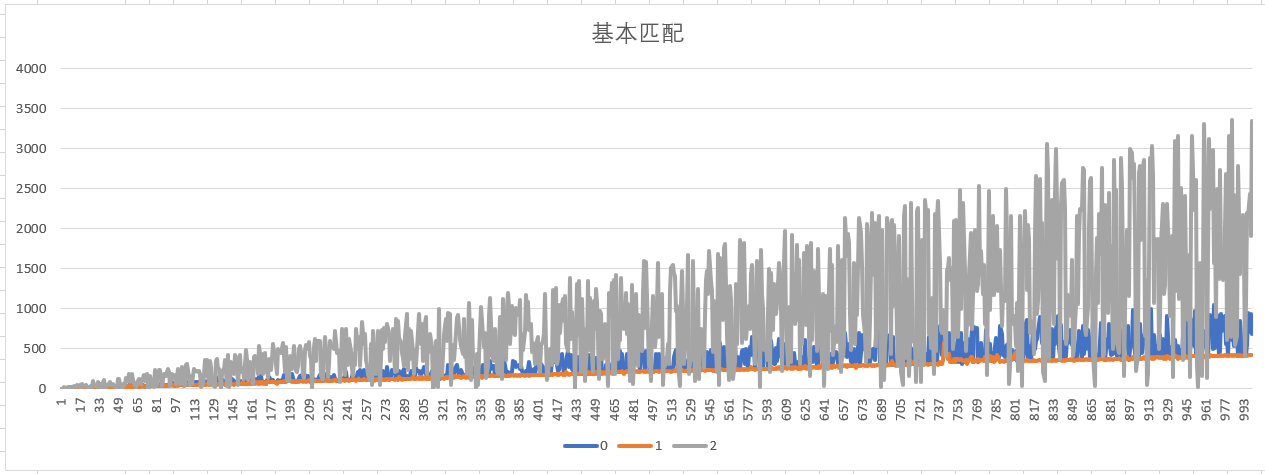
函数效率比较图:
0 代表strstrs
1 代表strstrs_ext
2 代表strstrs_normal
可以看出,strstrs_ext比较稳定,而且效率也比较高。
在关键字列表都与查找字符串不匹配情况trstrs_normal表现好过strstrs
在关键字列表都与查找字符串基本都存在匹配项情况strstrs表现好过strs_normal
在任何情况下strstrs_ext都表现 最好