一,解析过程
二,硬解析,软解析,软软解析
01,硬解析
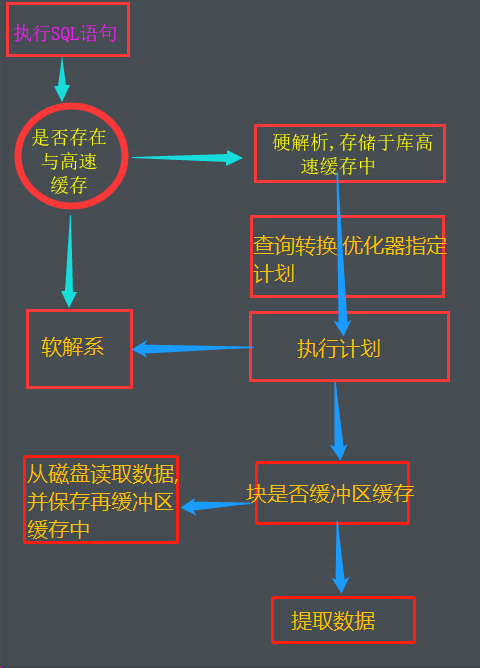
将SQL语句通过监听器发送到Oracle时, 会触发一个Server process生成,来对该客户进程服务。Server process得到SQL语句之后,对SQL语句进行Hash运算,然后根据Hash值到library cache中查找,如果存在,则直接将library cache中的缓存的执行计划拿来执行,最后将执行结果返回该客户端,这种SQL解析叫做软解析;如果不存在,则会对该SQL进行解析parse,然后执行,返回结果,这种SQL解析叫做硬解析。
1.1,解析过程
硬解析一般包括下面几个过程:
1)对SQL语句进行语法检查,看是否有语法错误。比如select from where 等的拼写错误,如果存在语法错误,则推出解析过程;
2)通过数据字典(row cache),检查SQL语句中涉及的对象和列是否存在。如果不存在,则推出解析过程。
3)检查SQL语句的用户是否对涉及到的对象是否有权限。如果没有则推出解析;
4)通过优化器创建一个最优的执行计划。这个过程会根据数据字典中的对象的统计信息,来计算多个执行计划的cost,从而得到一个最优的执行计划。这一步涉及到大量的数据运算,从而会消耗大量的CPU资源;(library cache最主要的目的就是通过软解析来减少这个步骤);
5)将该游标所产生的执行计划,SQL文本等装载进library cache中的heap中。
1.2 , 硬解析不足
1、 硬解析可能会导致Shared Pool Latch的争用。在Shared Pool中分配内存需要持有Shared Pool Latch,如果并发的硬解析的数量很多的化,可能会导致Shared Pool Latch的争用,这会影响到系统的性能和可扩展性。
2、 硬解析可能会导致库缓存相关Latch 和Mutex的争用
2.软解系
软解析是指Oracle在执行目标sql时,在Library Cache中找到了匹配的Parent Cursor和child Cursor,并将存储在Child Cursor中的解析树和执行计划直接拿过来重用,而无需从头开始解析的过程。
3,软软解析
当设置了session_cursor_cache这个参数之后,Cursor被直接Cache在当前Session的PGA中的,在解析的时候只需要对其语法分析、权限对象分析之后就可以转到PGA中查找了,如果发现完全相同的Cursor,就可以直接去取结果了,也就就是实现了 Soft Soft Parse.
4,总诉
无论是软硬解析,软软解析,Oracle在解析和执行sql时候,首先会到PGA中查找是否有匹配的session cursor,如果在当前PGA没有找到,则会到库缓存 查找是否有匹配的父子游标,如果找不到,就是生成一个新的session cursor和一对父子游标,如果找到父游标,没有找到子游标,就会生成,session cursor和子游标,挂在父游标下,这两种情况都是硬解析。 如果在PGA没有找到session cursor,但在库缓存找到父子游标,则生成一个新的session cursor,重用父子游标。如果在PGA找到,并在库缓存也找到,就是软软解析了。
三,sql执行的顺序
1、from子句:组装来自不同表、视图等数据源的数据。
2、where子句基于指定的过滤条件对记录进行筛选。
3、group by子句:将数据划分为多个组。
4、使用狙击函数的计算。
5、使用having子句筛选分组。
6、计算所有表达式。
7、select 产生字段。
8、使用order by 对结果进行排序。


1 SELECT (9) DISTINCT (11) <TOP_specification> <select_list> 2 (1) FROM <left_table> 3 (3) <join_type> JOIN <right_table> 4 (2) ON <join_condition> 5 (4) WHERE <where_condition> 6 (5) GROUP BY <group_by_list> 7 (6) WITH {CUBE | ROLLUP} 8 (7) HAVING <having_condition> 9 (10) ORDER BY <order_by_list>
1、 FROM:对FROM子句中的前两个表执行笛卡尔积(交叉联接),生成虚拟表VT1。 2、 ON:对VT1应用ON筛选器,只有那些使为真才被插入到TV2。 3、 OUTER (JOIN):如果指定了OUTER JOIN(相对于CROSS JOIN或INNER JOIN),保留表中未找到匹配的行将作为外部行添加到VT2,生成TV3。如果FROM子句包含两个以上的表,则对上一个联接生成的结果表和下一个表重复执行步骤1到步骤3,直到处理完所有的表位置。 4、 WHERE:对TV3应用WHERE筛选器,只有使为true的行才插入TV4。 5、 GROUP BY:按GROUP BY子句中的列列表对TV4中的行进行分组,生成TV5。 6、 CUTE|ROLLUP:把超组插入VT5,生成VT6。 7、 HAVING:对VT6应用HAVING筛选器,只有使为true的组插入到VT7。 8、 SELECT:处理SELECT列表,产生VT8。 9、 DISTINCT:将重复的行从VT8中删除,产品VT9。 10、ORDER BY:将VT9中的行按ORDER BY子句中的列列表顺序,生成一个游标(VC10)。 11、TOP:从VC10的开始处选择指定数量或比例的行,生成表TV11,并返回给调用者。
来自于:>>jlins