1.什么是Zookeeper
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper包含一个简单的原语集,提供Java和C的接口。
ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口,代码在zookeeper-3.4.3src
ecipes。其中分布锁和队列有Java和C两个版本,选举只有Java版本。
2.zookeeper的原理
ZooKeeper是以Fast Paxos算法为基础的,paxos算法存在
活锁的 问题,即当有多个proposer交错提交时,有可能互相排斥导致没有一个proposer能提交成功,而Fast Paxos作了一些优化,通过选举产生一个leader,只有leader才能提交propose,具体算法可见Fast Paxos。因此,要想弄懂ZooKeeper首先得对Fast Paxos有所了解。
1、选举Leader。
2、同步数据。
3、选举Leader过程中算法有很多,但要达到的选举标准是一致的。
4、Leader要具有最高的zxid。
5、集群中大多数的机器得到响应并follow选出的Leader
3.zookeeper的特点
在Zookeeper中,znode是一个跟Unix文件系统路径相似的节点,可以往这个节点存储或获取数据。如果在创建znode时Flag设置为 EPHEMERAL,那么当创建这个znode的节点和Zookeeper失去连接后,这个znode将不再存在在Zookeeper 里,Zookeeper使用Watcher察觉事件信息。当客户端接收到事件信息,比如连接超时、节点数据改变、子节点改变,可以调用相应的行为来处理数 据。Zookeeper的Wiki页面展示了如何使用Zookeeper来处理事件通知,队列,优先队列,锁,共享锁,可撤销的共享锁,两阶段提交。
那么Zookeeper能作什么事情呢,简单的例子:假设我们有20个
搜索引擎的
服务器(每 个负责总索引中的一部分的搜索任务)和一个总服务器(负责向这20个搜索引擎的服务器发出搜索请求并合并结果集),一个备用的总服务器(负责当总服务器宕 机时替换总服务器),一个web的cgi(向总服务器发出搜索请求)。搜索引擎的服务器中的15个服务器提供搜索服务,5个服务器正在生成索引。这20个 搜索引擎的服务器经常要让正在提供搜索服务的服务器停止提供服务开始生成索引,或生成索引的服务器已经把索引生成完成可以搜索提供服务了。使用 Zookeeper可以保证总服务器自动感知有多少提供搜索引擎的服务器并向这些服务器发出搜索请求,当总服务器宕机时自动启用备用的总服务器。
4.阿里云上搭建完全分布式zookeeper
系统环境可以参考前文 Hadoop环境搭建与配置
现在只需要准备zookeeper安装文件即可,可以从我的网盘获取 链接是: https://pan.baidu.com/s/1i5mTBEH 密码是:xbf4
(1). 安装软件
Create zookeeper folder under opt: sudo mkdir /opt/zookeeper
Unzip the installer: sudo tar -xvf zookeeper-3.4.9.tar.gz
(2). 修改配置文件
1). Rename the zoo.example.cfg to zoo.cfg

2). Add data directory in zoo.cfg

3). Add server list
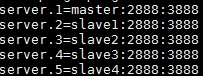
4). Create myid for each server and add corresponding server list number. Set master as the demo.

(3). 拷贝配置文件到slave节点并且修改myid
scp -r /opt/zookeeper hadoop@Slave1:/home/hadoop
scp -r /opt/zookeeper hadoop@Slave2:/home/hadoop
scp -r /opt/zookeeper hadoop@Slave3:/home/hadoop
scp -r /opt/zookeeper hadoop@Slave4:/home/hadoop
In each Slave, move to same location with Master and change owner:
sudo mv -r /home/zookeeper /opt/
(4). 在每个节点上都启动zookeeper


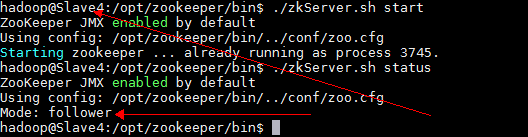
(5). Zookeeper leader和follower分配

5. 小结
本文介绍了如何在阿里云上分布式搭建zookeeper的操作,如果有任何问题,还请大家帮忙指正,谢谢.