本博客是自己在学习和工作途中的积累与总结,仅供自己参考,也欢迎大家转载,转载时请注明出处。
http://www.cnblogs.com/king-xg/p/6927541.html
如果觉得对您有帮助,请点击推荐或收藏本博客,谢谢。
1. 使用了connect by 的人,大多会存在一些疑问:
a. start with 后接的节点不同导致查询的方向(上或下)不同?
b. prior 关键字理解?
c. 突然出现的诸多冗余数据是怎么来的?
案例数据集就拿我上一篇博客的案例表来用了(删掉了循环列)
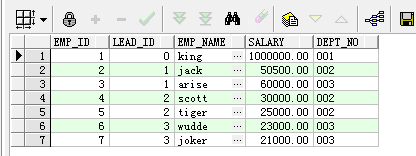
树形展示图:
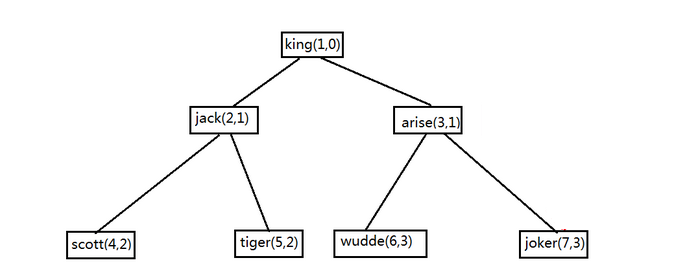
问题解答:
答: 1. start with 仅仅只是指定从那个节点开始,并不是上下查询的判断
2. start with 在向下查询时,仅有一点不同,后接子节点列则查询会比后接父节点列多一条记录,多出来的一条记录就是起始节点列,即,后接子节点列会查出起始行,后接父节点列则不会查询出起始行
3. 只有connect by语句中的prior关键字的位置决定了上下查询的方向,补充一下,如何判断上下查询
(a). 死记 prior 子节点列 = 父节点列 [向下查询],prior 父节点列 = 子节点列 [向上查询]
(b). 另一种更方便一点,“prior 子节点列 = 父节点列 [向下查询]” 就把proir 翻译成"以...为查询条件",那么就是这样翻译的"以子节点列为查询条件,查询父节点列",举例:"prior emp_id = lead_id" 翻译之后就是"以emp_id为查询条件查询lead_id",即向下查询,这样理解起来是不是感觉很简单了;
4. 向上查询的两种特殊情况,(1). 后接子节点列 (2). 后接父节点列
5.多出的冗余数据会在如下情况中出现
(a). 向上查询且start with 后接父节点列时
(b). sql语句中不包含start with 关键字时
讲解:
问题-向上查询的两种特殊情况:
向下查询且后接子节点列与向下查询且后接父节点列查询的结果集:
select emp_id,lead_id,emp_name,prior emp_name as lead_name,salary from employee start with emp_id=1 connect by prior emp_id = lead_id ;
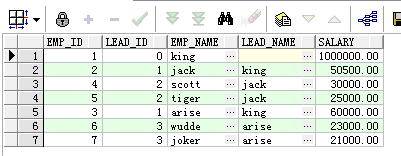
select emp_id,lead_id,emp_name,prior emp_name as lead_name,salary from employee start with lead_id=1 connect by prior emp_id = lead_id ;
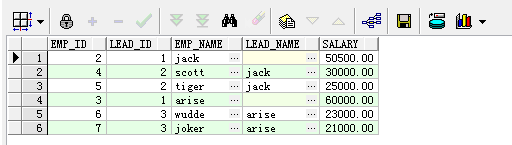
少了一行记起始记录,当然也可以使结果集不缺少记录,前提是其实行需定位到同一行
select emp_id,lead_id,emp_name,prior emp_name as lead_name,salary from employee start with lead_id=0 connect by prior emp_id = lead_id ;
解释: lead_id=0和emp_id=1指向的是同一行
问题-冗余数据的产生情况:
(1). 向上查询且后接父节点列时
select emp_id,lead_id,emp_name as lead_name,prior emp_name as emp_name,salary from employee start with lead_id=2 connect by emp_id = prior lead_id order by lead_id;
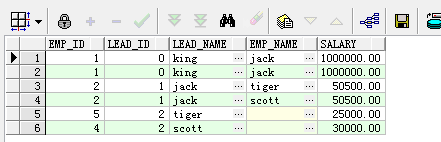
多了两条冗余记录,其实根据数据不难看出冗余的是起始节点记录的所有父节点和祖先节点的记录行
画图分析:

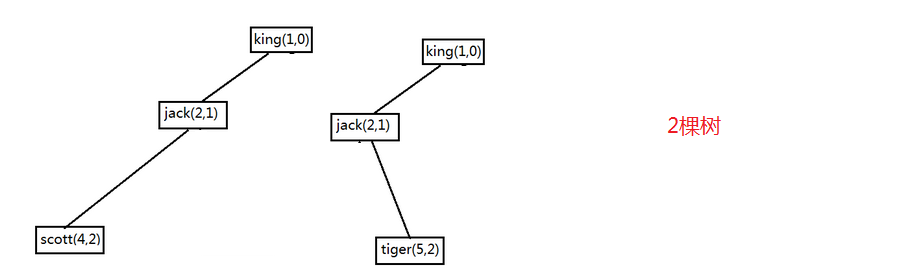
所以一般不建议向上查询时start with后接父节点列,这样会造成很多冗余数据行,拖慢了查询速度。
强烈建议: 需要查询父节点行或祖先记录行时,可以用向上查询且后接子节点列
举例:
select emp_id,lead_id,emp_name as lead_name,prior emp_name as emp_name,salary from employee start with emp_id=2 connect by emp_id = prior lead_id order by lead_id;

(2). sql语句中不包含start with 关键字时,同样也会产生冗余数据行,而且比上面的更多原因就在下面:
举例:
select emp_id,lead_id,emp_name,prior emp_name as lead_name,salary from employee connect by prior emp_id = lead_id
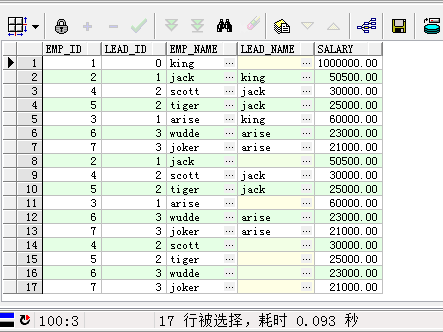
产生了10条冗余数据行,为什么呢?
其实很简单,由于缺少start with 指定起始行,那么oracle会根据proir修饰的字段进行一个内部的动态指定起始行位置,规则是由上至下,由左至右。
首先,指定起始节点为根节点(king),向下查询,然后指定子节点之一(jack)为起始节点,再向下查询,然后指定子节点之一(arise)为起始节点,再向下查询,....循环往复,直到到达最右侧最下方的叶子节点为止。
这里大家可能就会想,为什么是向下查询,而不是向上呢,原因就在于proir 的为止或者说他所修饰的列是子节点列还是父节点列有关,翻译一下就是"以子节点列为匹配条件,查询父节点",这么一看知道是向下查询喽。
同理,connect by emp_id = prior lead_id 这个表示向上查询,其他同理~_~