本博客是自己在学习和工作途中的积累与总结,仅供自己参考,也欢迎大家转载,转载时请注明出处。
http://www.cnblogs.com/king-xg/p/6692841.html
一, model子句
制作表格数据,用传统sql来实现的话,一般通过多个表的自联结实现,而model的出现则使得不用自联结就能实现表格,因为model拥有了跨行应用能力。
(1) 语法
MODEL
[]
[]
[MAIN ]
[PARTITION BY ()]
DIMENSION BY ()
MEASURES ()
[]
[RULES]
(, ,.., )
::=
::= RETURN {ALL|UPDATED} ROWS
::=
[IGNORE NAV | [KEEP NAV]
[UNIQUE DIMENSION | UNIQUE SINGLE REFERENCE]
::=
[UPDATE | UPSERT | UPSERT ALL]
[AUTOMATIC ORDER | SEQUENTIAL ORDER]
[ITERATE () [UNTIL ]]
::= REFERENCE ON ON ()
DIMENSION BY () MEASURES ()
------------建表,初始化数据,才好讲下面的内容----------------------
-- 创建表
create table ademo(
id number(18) primary key,
year varchar2(4),
week number(8),
sale number(8,2),
area varchar2(100)
);
-- 创建序列
create sequence seq_ademo_id
minvalue 1
start with 1
increment by 1
nomaxvalue
nocache
nocycle;
-- 创建触发器
create or replace trigger trigger_ademo_id
before insert on ademo for each row when (new.id is null)
begin
select seq_ademo_id.nextval into :new.id from dual;
end;
-- 初始化数据
insert into ademo (AREA, YEAR, WEEK, SALE)
values ('astiya', '2000', 1, 52.12);
insert into ademo (AREA, YEAR, WEEK, SALE)
values ('astiya', '2001', 1, 110.12);
insert into ademo (AREA, YEAR, WEEK, SALE)
values ('astiya', '2001', 2, 110.12);
insert into ademo (AREA, YEAR, WEEK, SALE)
values ('astiya', '2001', 3, 1210.12);
insert into ademo (AREA, YEAR, WEEK, SALE)
values ('astiya', '2002', 1, 170.12);
insert into ademo (AREA, YEAR, WEEK, SALE)
values ('astiya', '2002', 2, 680.12);
insert into ademo (AREA, YEAR, WEEK, SALE)
values ('astiya', '2002', 3, 680.12);
insert into ademo (AREA, YEAR, WEEK, SALE)
values ('anter', '2001', 1, 80.12);
insert into ademo (AREA, YEAR, WEEK, SALE)
values ('anter', '2001', 2, 56.72);
insert into ademo (AREA, YEAR, WEEK, SALE)
values ('anter', '2001', 3, 156.72);
insert into ademo (AREA, YEAR, WEEK, SALE)
values ('anter', '2002', 1, 640.12);
insert into ademo (AREA, YEAR, WEEK, SALE)
values ('anter', '2002', 2, 980.12);
insert into ademo (AREA, YEAR, WEEK, SALE)
values ('anter', '2002', 3, 1980.12);
/*delete from ademo;*/
-- 注释(这是我的个人习惯,不想麻烦的可以不加)
comment on table ademo is '测试经济类的表';
comment on column ademo.id is '主键';
comment on column ademo.year is '年份';
comment on column ademo.week is 'xxx周';
comment on column ademo.sale is '销售额';
comment on column ademo.area is '地区';
-- 展示数据
select * from ademo;
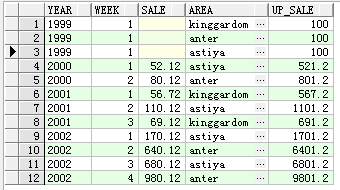
-- 例子1
select year,week,sale,area,up_sale
from ademo
model return updated rows -- model 语句
partition by (area) -- 分组
dimension by (year,week) -- 维度列
measures(sale,0 up_sale) -- 度量值列
rules( -- 规则
up_sale[year,week]=sale[cv(year),cv(week)]*10,
up_sale[1999,1]=100.00
)order by year,week;
-- 例子2
select year,week,sale,area,up_sale
from ademo
model
partition by (area)
dimension by (year,week)
measures(sale,0 up_sale)
rules(
up_sale[year,week]=sale[cv(year),cv(week)]*10,
up_sale[1999,for week from 1 to 3 increment 1]=100.00
)order by year,week;

--------------------------------------------------------------------
(2) 规则
a. 位置标记
即指定确定的位置明确的维度列值,例如:例子1中的规则(rules)中的up_sale[1999,1]=100.00,明确指出,year=1999,week=1的up_sale列的值为100.00,
作用: 位置标记通常也叫UPSERT,即update and insert,当结果集中不存在则插入,数量随分组的数量而定;存在时,则更新数据,更新的数据条数同样与分组的组数相同。
b. 符号标记
即指定范围的度量列值,例如:例子2中,up_sale[1999,for week from 1 to 3 increment 1]=100.00,指出,week的范围是在1-3,增长步长为1,所以在每个组中添加了3个up_sale[1999,1..3],共9个。
作用:只能更新数据
(3) model 返回更新后的行
在例子1中,model return updated rows 中,的“return updated rows”表示返回在本次操作中更新或插入的新纪录。默认返回所有符合条件的记录
(4) 在model的规则中是能够使用一般的聚合函数的,例如:count,sum,ave,stddev,PLAP。
(5) model 查找表,功能类似于表连接
---- 查询表
-- 创建表(销售表)
create table product_cost(
id number(18) primary key,
year number(4),
month number(2),
pid number(18),
countSum number(18)
);
comment on table product_cost is '产品销售表';
comment on column product_cost.id is '主键';
comment on column product_cost.year is '年份';
comment on column product_cost.month is '月份';
comment on column product_cost.pid is '产品id';
comment on column product_cost.countSum is '销售数量';
-- 创建表(产品表)
create table product(
id number(18) primary key,
pname varchar(100),
price number(8,2)
);
comment on table product is '产品表';
comment on column product.id is '主键';
comment on column product.pname is '产品名称';
comment on column product.price is '单价';
-- 创建序列
create sequence seq_product_cost_id
minvalue 1
start with 1
increment by 1
nomaxvalue
nocache
nocycle;
create sequence seq_product_id
minvalue 1
start with 1
increment by 1
nomaxvalue
nocache
nocycle;
-- 创建触发器
create or replace trigger trigger_product_cost_id
before insert on product_cost for each row when (new.id is null)
begin
select seq_product_cost_id.nextval into :new.id from dual;
end;
create or replace trigger trigger_product_id
before insert on product for each row when (new.id is null)
begin
select seq_product_id.nextval into :new.id from dual;
end;
-- 初始化数据
insert into product (pname,price) values('i7-6700K','23');
insert into product (pname,price) values('i7-6600K','20');
insert into product (pname,price) values('i7-6500K','19');
insert into product (pname,price) values('i7-6400K','18');
insert into product (pname,price) values('i7-6300K','17');
insert into product (pname,price) values('i7-6200K','15');
insert into product (pname,price) values('i7-6100K','12');
delete from product;
select * from product;
insert into product_cost(year,month,pid,countSum) values(2000,1,1,500);
insert into product_cost(year,month,pid,countSum) values(2000,1,2,630);
insert into product_cost(year,month,pid,countSum) values(2000,1,3,1200);
insert into product_cost(year,month,pid,countSum) values(2000,1,4,320);
insert into product_cost(year,month,pid,countSum) values(2000,1,5,150);
insert into product_cost(year,month,pid,countSum) values(2000,1,6,250);
insert into product_cost(year,month,pid,countSum) values(2000,1,7,350);
insert into product_cost(year,month,pid,countSum) values(2000,2,1,1500);
insert into product_cost(year,month,pid,countSum) values(2000,2,2,1630);
insert into product_cost(year,month,pid,countSum) values(2000,2,3,200);
insert into product_cost(year,month,pid,countSum) values(2000,2,4,1320);
insert into product_cost(year,month,pid,countSum) values(2000,2,5,250);
insert into product_cost(year,month,pid,countSum) values(2000,2,6,350);
insert into product_cost(year,month,pid,countSum) values(2000,2,7,450);
insert into product_cost(year,month,pid,countSum) values(2000,3,1,520);
insert into product_cost(year,month,pid,countSum) values(2000,3,2,660);
insert into product_cost(year,month,pid,countSum) values(2000,3,3,1900);
insert into product_cost(year,month,pid,countSum) values(2000,3,4,300);
insert into product_cost(year,month,pid,countSum) values(2000,3,5,180);
insert into product_cost(year,month,pid,countSum) values(2000,3,6,210);
insert into product_cost(year,month,pid,countSum) values(2000,3,7,320);
insert into product_cost(year,month,pid,countSum) values(2000,4,1,1520);
insert into product_cost(year,month,pid,countSum) values(2000,4,2,1660);
insert into product_cost(year,month,pid,countSum) values(2000,4,3,2900);
insert into product_cost(year,month,pid,countSum) values(2000,4,4,1200);
insert into product_cost(year,month,pid,countSum) values(2000,4,5,980);
insert into product_cost(year,month,pid,countSum) values(2000,4,6,910);
insert into product_cost(year,month,pid,countSum) values(2000,4,7,620);
insert into product_cost(year,month,pid,countSum) values(2001,1,1,500);
insert into product_cost(year,month,pid,countSum) values(2001,1,2,630);
insert into product_cost(year,month,pid,countSum) values(2001,1,3,1200);
insert into product_cost(year,month,pid,countSum) values(2001,1,4,320);
insert into product_cost(year,month,pid,countSum) values(2001,1,5,150);
insert into product_cost(year,month,pid,countSum) values(2001,1,6,250);
insert into product_cost(year,month,pid,countSum) values(2001,1,7,350);
insert into product_cost(year,month,pid,countSum) values(2001,2,1,1500);
insert into product_cost(year,month,pid,countSum) values(2001,2,2,1630);
insert into product_cost(year,month,pid,countSum) values(2001,2,3,200);
insert into product_cost(year,month,pid,countSum) values(2001,2,4,1320);
insert into product_cost(year,month,pid,countSum) values(2001,2,5,250);
insert into product_cost(year,month,pid,countSum) values(2001,2,6,350);
insert into product_cost(year,month,pid,countSum) values(2001,2,7,450);
insert into product_cost(year,month,pid,countSum) values(2001,3,1,520);
insert into product_cost(year,month,pid,countSum) values(2001,3,2,660);
insert into product_cost(year,month,pid,countSum) values(2001,3,3,1900);
insert into product_cost(year,month,pid,countSum) values(2001,3,4,300);
insert into product_cost(year,month,pid,countSum) values(2001,3,5,180);
insert into product_cost(year,month,pid,countSum) values(2001,3,6,210);
insert into product_cost(year,month,pid,countSum) values(2001,3,7,320);
insert into product_cost(year,month,pid,countSum) values(2001,4,1,1520);
insert into product_cost(year,month,pid,countSum) values(2001,4,2,1660);
insert into product_cost(year,month,pid,countSum) values(2001,4,3,2900);
insert into product_cost(year,month,pid,countSum) values(2001,4,4,1200);
insert into product_cost(year,month,pid,countSum) values(2001,4,5,980);
insert into product_cost(year,month,pid,countSum) values(2001,4,6,910);
insert into product_cost(year,month,pid,countSum) values(2001,4,7,620);
select * from product_cost;
select * from product;
在传统sql实现:
select pc.year as year,pc.month as month, p.pname as pname,pc.countSum as count, (pc.countSum * p.price) as sale
from product_cost pc left join product p
on pc.pid=p.id
where year=2000 and month=4;
-- 解释计划
explain plan for
select pc.year as year,pc.month as month, p.pname as pname,pc.countSum as count, (pc.countSum * p.price) as sale
from product_cost pc left join product p
on pc.pid=p.id where year=2000 and month=4;
commit;
-- 查看解释计划
select * from table(dbms_xplan.display);
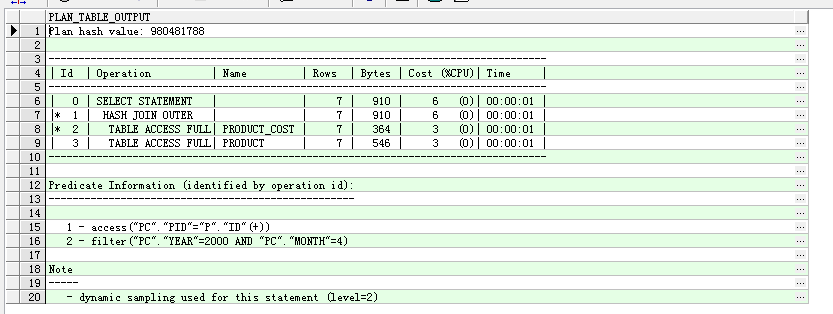
由于没添加索引所以全盘扫描。
model查找表:
select year,month,pid,pname,price,sale,countSum
from product_cost
model
reference ref_pro on
(
select id,pname,price
from product
)
dimension by (id)
measures (pname,price)
main main_selection
partition by (year,month)
dimension by (pid)
measures(countSum,cast(' ' as varchar2(200))pname, cast(0 as number(18,2))sale, cast(0 as number(8,2))price)
rules (
pname[pid] =ref_pro.pname[cv(pid)],
price[pid]=ref_pro.price[cv(pid)],
countSum[pid]=countSum[cv(pid)],
sale[pid]=price[cv(pid)]*countSum[cv(pid)]
) where year=2000 and month=4 order by year,month,pid;
-- 解释计划
explain plan for
select year,month,pid,pname,price,sale,countSum
from product_cost
model
reference ref_pro on
(
select id,pname,price
from product
)
dimension by (id)
measures (pname,price)
main main_selection
partition by (year,month)
dimension by (pid)
measures(countSum,cast(' ' as varchar2(200))pname, cast(0 as number(18,2))sale, cast(0 as number(8,2))price)
rules (
pname[pid] =ref_pro.pname[cv(pid)],
price[pid]=ref_pro.price[cv(pid)],
countSum[pid]=countSum[cv(pid)],
sale[pid]=price[cv(pid)]*countSum[cv(pid)]
) where year=2000 and month=4 order by year,month,pid;
commit;
-- 查看解释计划
select * from table(dbms_xplan.display);

两者相比较,model子句的性能会更好,即便在没有索引的情况下,model子句预期访问的字节数要小于传统的sql自联结,那这是为什么呢?
其实这与model的内部分组机制有关,谓语中的字段含有分组(partition by)中的字段,所以,model就会仅仅访问谓语指定的分区,其他分区不管,这很大程度上提高了sql的性能。
(5)谓语前推
--谓语前推
-- 内嵌视图
select *
from ( select year,week,sale,area,0 as new_sale from ademo)
model return updated rows
partition by (year,week)
dimension by (area)
measures (sale, 0 new_sale)
rules (
new_sale[area]=sale[cv(area)]*10
)
order by year,week;
-- 成功将谓语推入视图
explain plan for
select *
from ( select year,week,sale,area,0 as new_sale from ademo
model return updated rows
partition by (year,week)
dimension by (area)
measures (sale, 0 new_sale)
rules (
new_sale[area]=sale[cv(area)]*10
)
)where year=2001
order by year,week;
commit;
-- 解释计划
select * from table(dbms_xplan.display);

在一开始全表扫描的时候就执行了过滤,减少了扫描的数据块的数,降低了加载的字节数。
然后看看下面推入失败的sql
-- 失败,在全表扫描完后的结果集上进行过滤,并未退入到视图
explain plan for
select *
from ( select year,week,sale,area,0 as new_sale from ademo
model return updated rows
partition by (year,week)
dimension by (area)
measures (sale, 0 new_sale)
rules (
new_sale[area]=sale[cv(area)]*10
)
)where area='kinggardom'
order by year,week;
commit;
-- 解释计划
select * from table(dbms_xplan.display);

很明显,过滤实在view操作的时候进行,即在得到全包扫描后的结果集后进行过滤,无疑说明此次谓语前推失败。
-- 原因:在model中存在一种分区的机制,partition by是进行分区的判断依据,那么若果在外sql中存在与分区列匹配的列,则model子句就会只扫描匹配的分区,其他分区就不管了,如果不存在则,全表扫描或者说扫描所有分区
-- 结论: 谓语中,能被推入到视图中的仅仅只有分组中的字段(partition by(字段))
(6) 子查询因子化(小小的提一下,后期再出详细的笔记)
-- 格式: with [alias] as () select ...
-- 题目: 将同一年的一月前的sale进行对比,查看是增长还是下降了多少
-- 神似内嵌视图
举例:
with t as (
select year,month,pid,pname,price,sale,countSum
from product_cost
model
reference ref_pro on
(
select id,pname,price
from product
)
dimension by (id)
measures (pname,price)
main main_selection
partition by (year,month)
dimension by (pid)
measures(countSum,cast(' ' as varchar2(200))pname, cast(0 as number(18,2))sale, cast(0 as number(8,2))price)
rules (
pname[pid] =ref_pro.pname[cv(pid)],
price[pid]=ref_pro.price[cv(pid)],
countSum[pid]=countSum[cv(pid)],
sale[pid]=price[cv(pid)]*countSum[cv(pid)]
)
)
select year,month,pname,sale,pre_sale,compare_pre_sale
from t
model
partition by (pname)
dimension by (year,month)
measures (0 pre_sale,0 compare_pre_sale,sale)
rules(
pre_sale[year,month]=presentnnv(sale[cv(year),cv(month)-1],sale[cv(year),cv(month)-1],sale[cv(year),cv(month)]),
compare_pre_sale[year,month]=sale[cv(year),cv(month)]-pre_sale[cv(year),cv(month)]
)order by pname,month;
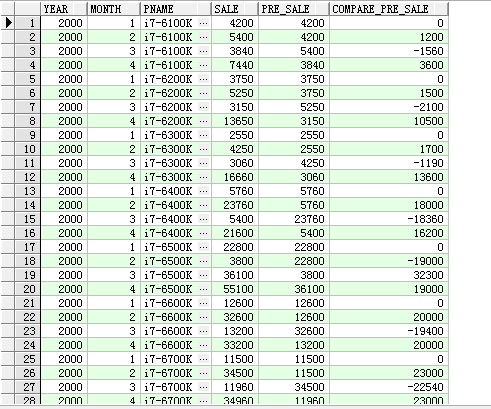
其实这个可以不用把规则分开写,因为数据并不复杂,对于复杂的数据,用这个还是很不错的选择。
小结: model用来制作表格数据比之传统的表联结来实现会是一个更好的选择,model子句能够提供更好的sql性能,提供更清晰的结构。