首次体验Pytorch,本文参考于:github and PyTorch 中文网人脸相似度对比
本文主要熟悉Pytorch大致流程,修改了读取数据部分。没有采用原作者的ImageFolder方法: ImageFolder(root, transform=None, target_transform=None, loader=default_loader)。而是采用了一种更自由的方法,利用了Dataset 和 DataLoader 自由实现,更加适合于不同数据的预处理导入工作。
Siamese网络不用多说,就是两个共享参数的CNN。每次的输入是一对图像+1个label,共3个值。注意label=0或1(又称正负样本),表示输入的两张图片match(匹配、同一个人)或no-match(不匹配、非同一人)。 下图是Siamese基本结构,图是其他论文随便找的,输入看做两张图片就好。只不过下图是两个光普段而已。
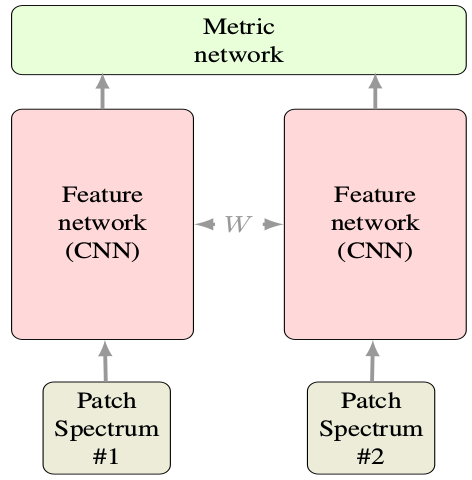
1. 数据处理
数据采用的是AT&T人脸数据。共40个人,每个人有10张脸。数据下载:AT&T
首先解压后发现文件夹下共40个文件夹,每个文件夹里有10张pgm图片。这里生成一个包含图片路径的train.txt文件共后续调用:
def convert(train=True): if(train): f=open(Config.txt_root, 'w') data_path=root+'/train/' if(not os.path.exists(data_path)): os.makedirs(data_path) for i in range(40): for j in range(10): img_path = data_path+'s'+str(i+1)+'/'+str(j+1)+'.pgm' f.write(img_path+' '+str(i)+' ') f.close()
生成结果:每行前面为每张图片的完整路径, 后面数字为类别标签0~39。train文件夹下为s1~s40共40个子文件夹。
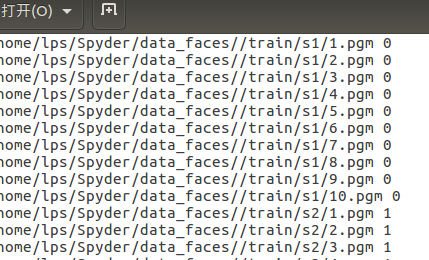

2. 定制个性化数据集
这一步骤主要继承了类Dataset,然后重写getitem和len方法即可:
class MyDataset(Dataset): # 集成Dataset类以定制 def __init__(self, txt, transform=None, target_transform=None, should_invert=False): self.transform = transform self.target_transform = target_transform self.should_invert = should_invert self.txt = txt # 之前生成的train.txt def __getitem__(self, index): line = linecache.getline(self.txt, random.randint(1, self.__len__())) # 随机选择一个人脸 line.strip(' ') img0_list= line.split() should_get_same_class = random.randint(0,1) # 随机数0或1,是否选择同一个人的脸,这里为了保证尽量使匹配和非匹配数据大致平衡(正负类样本相当) if should_get_same_class: # 执行的话就挑一张同一个人的脸作为匹配样本对 while True: img1_list = linecache.getline(self.txt, random.randint(1, self.__len__())).strip(' ').split() if img0_list[1]==img1_list[1]: break else: # else就是随意挑一个人的脸作为非匹配样本对,当然也可能抽到同一个人的脸,概率较小而已 img1_list = linecache.getline(self.txt, random.randint(1,self.__len__())).strip(' ').split() img0 = Image.open(img0_list[0]) # img_list都是大小为2的列表,list[0]为图像, list[1]为label img1 = Image.open(img1_list[0]) img0 = img0.convert("L") # 转为灰度 img1 = img1.convert("L") if self.should_invert: # 是否进行像素反转操作,即0变1,1变0 img0 = PIL.ImageOps.invert(img0) img1 = PIL.ImageOps.invert(img1) if self.transform is not None: # 非常方便的transform操作,在实例化时可以进行任意定制 img0 = self.transform(img0) img1 = self.transform(img1) return img0, img1 , torch.from_numpy(np.array([int(img1_list[1]!=img0_list[1])],dtype=np.float32)) # 注意一定要返回数据+标签, 这里返回一对图像+label(应由numpy转为tensor) def __len__(self): # 数据总长 fh = open(self.txt, 'r') num = len(fh.readlines()) fh.close() return num
3. 制作双塔CNN
class SiameseNetwork(nn.Module): def __init__(self): super(SiameseNetwork, self).__init__() self.cnn1 = nn.Sequential( nn.ReflectionPad2d(1), nn.Conv2d(1, 4, kernel_size=3), nn.ReLU(inplace=True), nn.BatchNorm2d(4), nn.Dropout2d(p=.2), nn.ReflectionPad2d(1), nn.Conv2d(4, 8, kernel_size=3), nn.ReLU(inplace=True), nn.BatchNorm2d(8), nn.Dropout2d(p=.2), nn.ReflectionPad2d(1), nn.Conv2d(8, 8, kernel_size=3), nn.ReLU(inplace=True), nn.BatchNorm2d(8), nn.Dropout2d(p=.2), ) self.fc1 = nn.Sequential( nn.Linear(8*100*100, 500), nn.ReLU(inplace=True), nn.Linear(500, 500), nn.ReLU(inplace=True), nn.Linear(500, 5) ) def forward_once(self, x): output = self.cnn1(x) output = output.view(output.size()[0], -1) output = self.fc1(output) return output def forward(self, input1, input2): output1 = self.forward_once(input1) output2 = self.forward_once(input2) return output1, output2
很简单,没说的,注意前向传播是两张图同时输入进行。
4. 定制对比损失函数
# Custom Contrastive Loss class ContrastiveLoss(torch.nn.Module): """ Contrastive loss function. Based on: http://yann.lecun.com/exdb/publis/pdf/hadsell-chopra-lecun-06.pdf """ def __init__(self, margin=2.0): super(ContrastiveLoss, self).__init__() self.margin = margin def forward(self, output1, output2, label): euclidean_distance = F.pairwise_distance(output1, output2) loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2) + # calmp夹断用法 (label) * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2)) return loss_contrastive
上面的损失函数为自己制作的,公式源于lecun文章:
Loss = 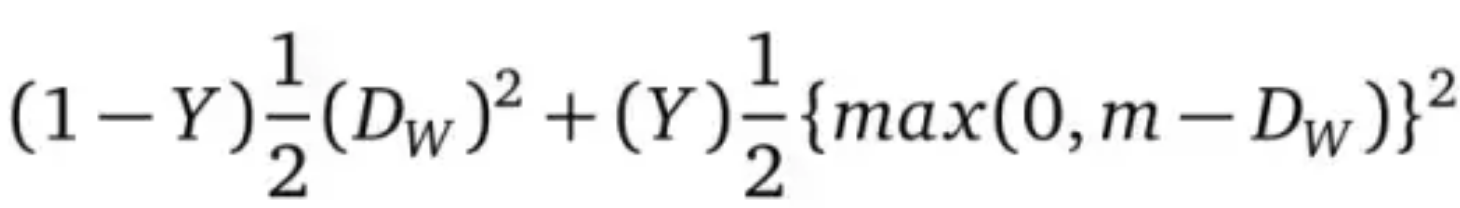
DW= 
m为容忍度, Dw为两张图片的欧氏距离。
5. 训练一波
train_data = MyDataset(txt = Config.txt_root,transform=transforms.Compose( [transforms.Resize((100,100)),transforms.ToTensor()]), should_invert=False) #Resize到100,100 train_dataloader = DataLoader(dataset=train_data, shuffle=True, num_workers=2, batch_size = Config.train_batch_size) net = SiameseNetwork().cuda() # GPU加速 criterion = ContrastiveLoss() optimizer = optim.Adam(net.parameters(), lr=0.0005) counter = [] loss_history =[] iteration_number =0 for epoch in range(0, Config.train_number_epochs): for i, data in enumerate(train_dataloader, 0): img0, img1, label = data img0, img1, label = Variable(img0).cuda(), Variable(img1).cuda(), Variable(label).cuda() output1, output2 = net(img0, img1) optimizer.zero_grad() loss_contrastive = criterion(output1, output2, label) loss_contrastive.backward() optimizer.step() if i%10 == 0: print("Epoch:{}, Current loss {} ".format(epoch,loss_contrastive.data[0])) iteration_number += 10 counter.append(iteration_number) loss_history.append(loss_contrastive.data[0]) show_plot(counter, loss_history) # plot 损失函数变化曲线
损失函数结果图:
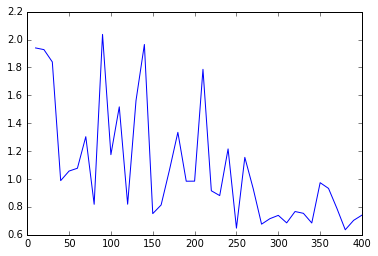
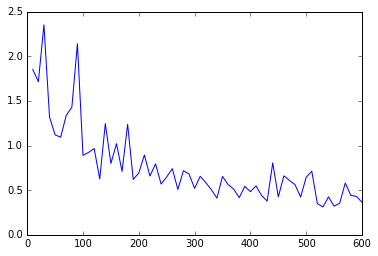
batch_size=32, epoches=20, lr=0.001 batch_size=32, epoches=30, lr=0.0005
全部代码:


#!/usr/bin/env python3 # -*- coding: utf-8 -*- """ Created on Wed Jan 24 10:00:24 2018 Paper: Siamese Neural Networks for One-shot Image Recognition links: https://www.cnblogs.com/denny402/p/7520063.html """ import torch from torch.autograd import Variable import os import random import linecache import numpy as np import torchvision from torch.utils.data import Dataset, DataLoader from torchvision import transforms from PIL import Image import PIL.ImageOps import matplotlib.pyplot as plt class Config(): root = '/home/lps/Spyder/data_faces/' txt_root = '/home/lps/Spyder/data_faces/train.txt' train_batch_size = 32 train_number_epochs = 30 # Helper functions def imshow(img,text=None,should_save=False): npimg = img.numpy() plt.axis("off") if text: plt.text(75, 8, text, style='italic',fontweight='bold', bbox={'facecolor':'white', 'alpha':0.8, 'pad':10}) plt.imshow(np.transpose(npimg, (1, 2, 0))) plt.show() def show_plot(iteration,loss): plt.plot(iteration,loss) plt.show() def convert(train=True): if(train): f=open(Config.txt_root, 'w') data_path=root+'/train/' if(not os.path.exists(data_path)): os.makedirs(data_path) for i in range(40): for j in range(10): img_path = data_path+'s'+str(i+1)+'/'+str(j+1)+'.pgm' f.write(img_path+' '+str(i)+' ') f.close() #convert(True) # ready the dataset, Not use ImageFolder as the author did class MyDataset(Dataset): def __init__(self, txt, transform=None, target_transform=None, should_invert=False): self.transform = transform self.target_transform = target_transform self.should_invert = should_invert self.txt = txt def __getitem__(self, index): line = linecache.getline(self.txt, random.randint(1, self.__len__())) line.strip(' ') img0_list= line.split() should_get_same_class = random.randint(0,1) if should_get_same_class: while True: img1_list = linecache.getline(self.txt, random.randint(1, self.__len__())).strip(' ').split() if img0_list[1]==img1_list[1]: break else: img1_list = linecache.getline(self.txt, random.randint(1,self.__len__())).strip(' ').split() img0 = Image.open(img0_list[0]) img1 = Image.open(img1_list[0]) img0 = img0.convert("L") img1 = img1.convert("L") if self.should_invert: img0 = PIL.ImageOps.invert(img0) img1 = PIL.ImageOps.invert(img1) if self.transform is not None: img0 = self.transform(img0) img1 = self.transform(img1) return img0, img1 , torch.from_numpy(np.array([int(img1_list[1]!=img0_list[1])],dtype=np.float32)) def __len__(self): fh = open(self.txt, 'r') num = len(fh.readlines()) fh.close() return num # Visualising some of the data """ train_data=MyDataset(txt = Config.txt_root, transform=transforms.ToTensor(), transform=transforms.Compose([transforms.Scale((100,100)), transforms.ToTensor()], should_invert=False)) train_loader = DataLoader(dataset=train_data, batch_size=8, shuffle=True) #it = iter(train_loader) p1, p2, label = it.next() example_batch = it.next() concatenated = torch.cat((example_batch[0],example_batch[1]),0) imshow(torchvision.utils.make_grid(concatenated)) print(example_batch[2].numpy()) """ # Neural Net Definition, Standard CNNs import torch.nn as nn import torch.nn.functional as F import torch.optim as optim class SiameseNetwork(nn.Module): def __init__(self): super(SiameseNetwork, self).__init__() self.cnn1 = nn.Sequential( nn.ReflectionPad2d(1), nn.Conv2d(1, 4, kernel_size=3), nn.ReLU(inplace=True), nn.BatchNorm2d(4), nn.Dropout2d(p=.2), nn.ReflectionPad2d(1), nn.Conv2d(4, 8, kernel_size=3), nn.ReLU(inplace=True), nn.BatchNorm2d(8), nn.Dropout2d(p=.2), nn.ReflectionPad2d(1), nn.Conv2d(8, 8, kernel_size=3), nn.ReLU(inplace=True), nn.BatchNorm2d(8), nn.Dropout2d(p=.2), ) self.fc1 = nn.Sequential( nn.Linear(8*100*100, 500), nn.ReLU(inplace=True), nn.Linear(500, 500), nn.ReLU(inplace=True), nn.Linear(500, 5) ) def forward_once(self, x): output = self.cnn1(x) output = output.view(output.size()[0], -1) output = self.fc1(output) return output def forward(self, input1, input2): output1 = self.forward_once(input1) output2 = self.forward_once(input2) return output1, output2 # Custom Contrastive Loss class ContrastiveLoss(torch.nn.Module): """ Contrastive loss function. Based on: http://yann.lecun.com/exdb/publis/pdf/hadsell-chopra-lecun-06.pdf """ def __init__(self, margin=2.0): super(ContrastiveLoss, self).__init__() self.margin = margin def forward(self, output1, output2, label): euclidean_distance = F.pairwise_distance(output1, output2) loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2) + (label) * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2)) return loss_contrastive # Training train_data = MyDataset(txt = Config.txt_root,transform=transforms.Compose( [transforms.Resize((100,100)),transforms.ToTensor()]), should_invert=False) train_dataloader = DataLoader(dataset=train_data, shuffle=True, num_workers=2, batch_size = Config.train_batch_size) net = SiameseNetwork().cuda() criterion = ContrastiveLoss() optimizer = optim.Adam(net.parameters(), lr=0.0005) counter = [] loss_history =[] iteration_number =0 for epoch in range(0, Config.train_number_epochs): for i, data in enumerate(train_dataloader, 0): img0, img1, label = data img0, img1, label = Variable(img0).cuda(), Variable(img1).cuda(), Variable(label).cuda() output1, output2 = net(img0, img1) optimizer.zero_grad() loss_contrastive = criterion(output1, output2, label) loss_contrastive.backward() optimizer.step() if i%10 == 0: print("Epoch:{}, Current loss {} ".format(epoch,loss_contrastive.data[0])) iteration_number += 10 counter.append(iteration_number) loss_history.append(loss_contrastive.data[0]) show_plot(counter, loss_history)
原作者jupyter notebook下载:Siamese Neural Networks for One-shot Image Recognition
更多资料:Some important Pytorch tasks
利用Siamese network 来解决 one-shot learning:https://sorenbouma.github.io/blog/oneshot/ 译文: 【深度神经网络 One-shot Learning】孪生网络少样本精准分类
A PyTorch Implementation of "Siamese Neural Networks for One-shot Image Recognition"