一. 引入NMS
在R-CNN中对于2000多个region proposals得到特征向量(4096维)后,输入到SVM中进行打分(score)。除了背景以外VOC数据集共有20类。那么2000*4096维特征矩阵与20个SVM组成的权重矩阵4096*20相乘得到结果为2000*20维矩阵。这个矩阵2000行表示有2000个框。20列为每一个框属于这20个类的score(置信度)。也就是说每一列即每一类有2000个不同的分值。那么每一类有这么多候选框肯定大多冗余。所以需要利用非极大值抑制方法进行删除重叠候选框。
NMS算法的输入:2000个候选框的位置坐标(两个顶点的x,y坐标,共4个值)、score分数值(置信度)。
NMS算法的输出:所有满足筛选条件的建议框(可能不止一个)。
NMS算法的大致思想:对于有重叠的候选框:若大于规定阈值(某一提前设定的置信度)则删除,低于阈值的保留。
对于无重叠的候选框:都保留。
二. 算法实现
nms.m
function pick = nms(boxes, overlap)
% pick = nms(boxes, overlap) 输入: boxes为所有候选框的左下角和右上角x,y坐标。overlap为事先人为设定的阈值。
% Non-maximum suppression. 输出: pick,即所有保留下来的框
% Greedily select high-scoring detections and skip detections
% that are significantly covered by a previously selected detection.
if isempty(boxes)
pick = [];
else
x1 = boxes(:,1); %所有候选框的左下角顶点x
y1 = boxes(:,2); %所有候选框的左下角顶点y
x2 = boxes(:,3); %所有候选框的右上角顶点x
y2 = boxes(:,4); %所有候选框的右上角顶点y
s = boxes(:,end); %所有候选框的置信度,可以包含1列或者多列,用于表示不同准则的置信度
area = (x2-x1+1) .* (y2-y1+1); %所有候选框的面积
[vals, I] = sort(s); %将所有候选框进行从小到大排序,vals为排序后结果,I为排序后标签
pick = [];
while ~isempty(I)
last = length(I); %last代表标签I的长度,即最后一个元素的位置,(matlab矩阵从1开始计数)
i = I(last); %所有候选框的中置信度最高的那个的标签赋值给i
pick = [pick; i]; %将i存入pick中,pick保存输出的NMS处理后的box的序号,即保存最后结果
suppress = [last]; %将I中最大置信度的标签在I中位置赋值给suppress,suppress作用为类似打标志,
for pos = 1:last-1 %从1到倒数第二个进行循环
j = I(pos); %得到pos位置的标签,赋值给j
xx1 = max(x1(i), x1(j));%左上角最大的x(求两个方框的公共区域)
yy1 = max(y1(i), y1(j));%左上角最大的y
xx2 = min(x2(i), x2(j));%右下角最小的x
yy2 = min(y2(i), y2(j));%右下角最小的y
w = xx2-xx1+1; %公共区域的宽度
h = yy2-yy1+1; %公共区域的高度
if w > 0 && h > 0 %w,h全部>0,证明2个候选框相交
o = w * h / area(j);%计算overlap比值,即交集占候选框j的面积比例
if o > overlap %如果大于设置的阈值就去掉候选框j,因为候选框i的置信度最高
suppress = [suppress; pos]; %大于规定阈值就加入到suppress,即待删除的框
end
end
end
I(suppress) = [];%将待删除的框删除,I中剩余未处理的框。当I为空结束循环
end
end
nms_draw.m
boxes=[200,200,400,400,0.99; 220,220,420,420,0.9; 100,100,150,150,0.82; 200,240,400,440,0.5; 150,250,300,400,0.88]; overlap=0.8; # 设置好的阈值 pick = nms(boxes, overlap); figure; for i=1:size(boxes,1) rectangle('Position',[boxes(i,1),boxes(i,2),boxes(i,3)-boxes(i,1),boxes(i,4)-boxes(i,2)],'EdgeColor','y','LineWidth',6); text(boxes(i,1),boxes(i,2),num2str(boxes(i,5)),'FontSize',14,'color','b'); end for i=1:size(pick,1) rectangle('Position',[boxes(pick(i),1),boxes(pick(i),2),boxes(pick(i),3)-boxes(pick(i),1),boxes(pick(i),4)-boxes(pick(i),2)],'EdgeColor','r','LineWidth',2); end axis([0 600 0 600]);
结果:
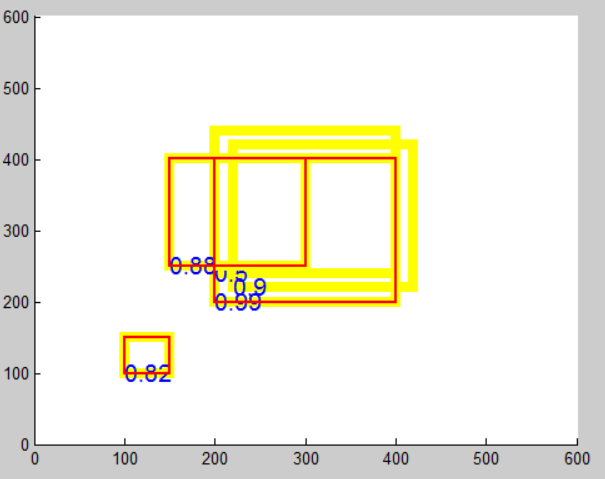
可以看到:置信度为0.99的框保留下来是因为其置信度最高。第一次迭代时就已经存入了pick数组中。
置信度为0.88的框保留下来是因为其与0.99的框交并比IOU < overlap = 0.8
置信度为0.82的框保留下来是因为其与任何框都无重叠。
注意此时经过NMS后,每类别还可能会剩余不止一个的候选框。而对于图像中的每个类别我们只需一个候选框即可。所以还有后续处理。
后续:R-CNN分别用20个回归器对上述20个类别中剩余的候选框进行回归操作。最终得到每个类别修正后的得分最高的bounding box。
Reference: