这篇文章给出了用元学习做few-shot的baseline。整体感觉是实验做得很丰富,但是创新不太明显,简单总结一些实验过程和结论。code:https://github.com/cyvius96/few-shot-meta-baseline。
关于元学习和few-shot的基本内容有个很好的解释:Model-Agnostic Meta-Learning (MAML)模型介绍及算法详解(转载 。
baseline包括两部分:classifier-baseline和Meta-Baseline。
classifier-baseline:在base类上预训练一个分类器,然后移去最后一个分类器。把novel类的support特征都提出来,求均值作为每个类中心,然后把novel类的query数据按照余弦相似性进行分配(这个过程是eval过程,在meta-baseline中是meta-learning过程)。和之前方法的区别:之前的方法是吧novel数据扔进网络微调分类器,而本文不需再训练这个丢掉的分类器。就这个操作就和sota能打了。
meta-baseline:然后是这个东西,用于在classifier-baseline再提升。在meta-learning过程,利用上面的eval方法进行训练。
下图很明确:

性能:
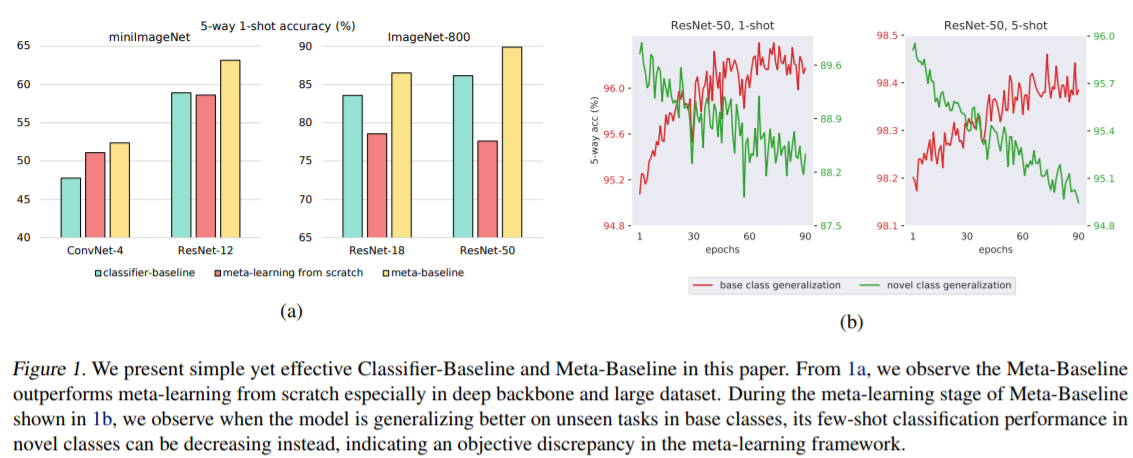
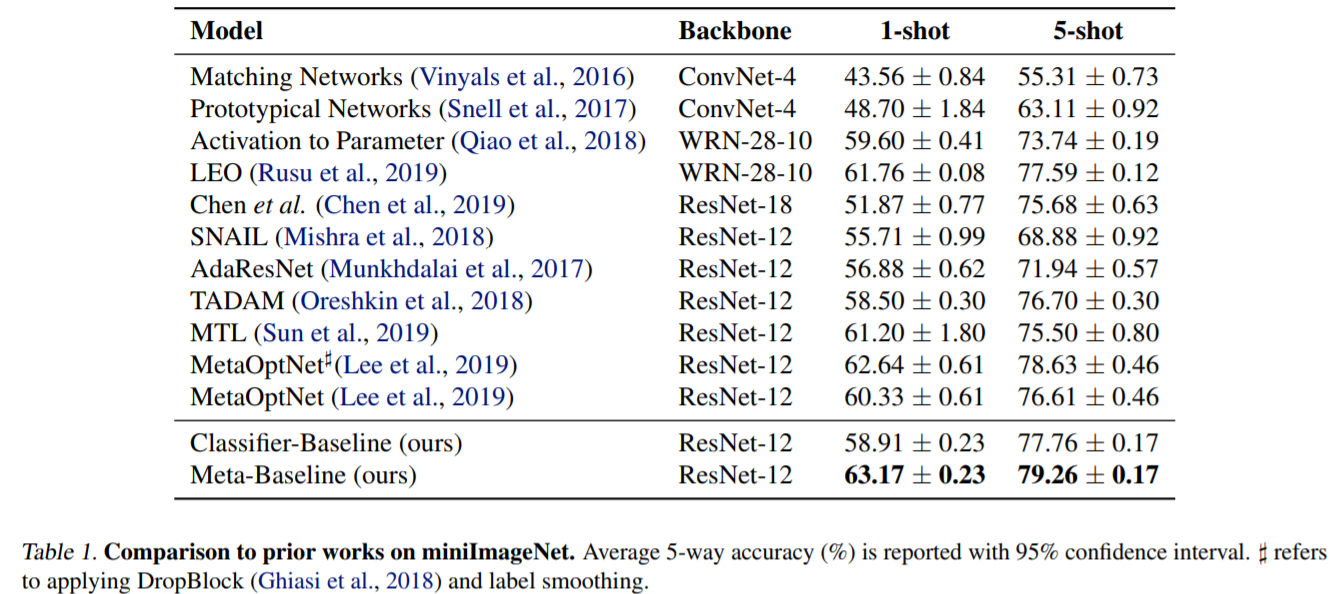
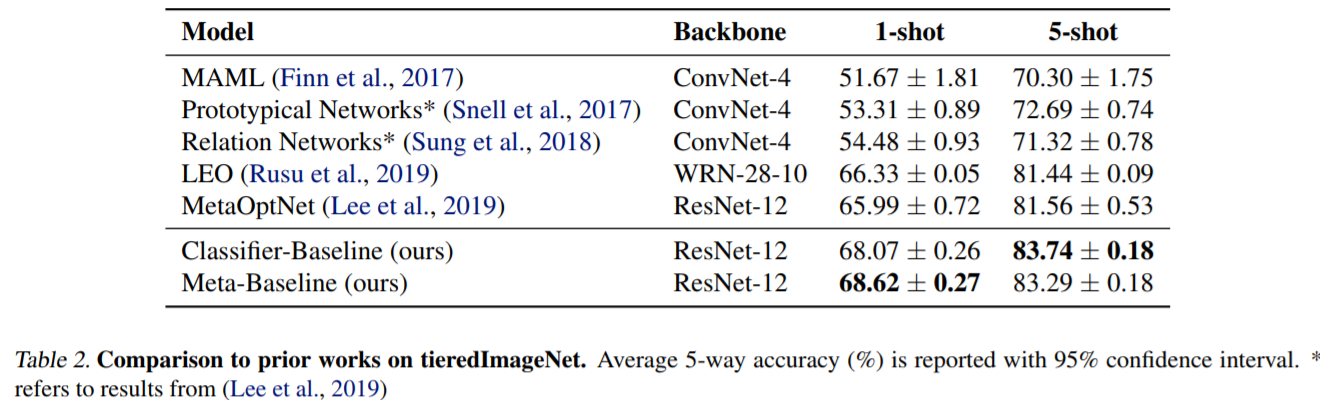
一些赠品:
base和novel的类别相似性影响meta-learning能否提升classifier-baseline
数据规模越大,meta-learning提升越小
meta-learning对于1-shot提升要高于5-shot
meta-learning阶段,base class的泛化性能增加,而novel class的泛化性能在下降。如下图:
