一篇总结整理近来few-shot分类的文章(近来文章一些毛病:code实现细节很难说清真正的gain在哪,一些baseline被压得太低,base类和novel类之间的域差异不明显导致评估也不可能不太准)。作者复现了一下主要的几篇工作,然后总结如下:更深的backbone在不同域上的表现对于不同方法差不多;整理了一个baseline并在mini-ImageNet和CUB数据上和当前的sota表现差不多(通过用基于距离的分类器来替代原有传统的线性分类器);提了一种新的设定来评估few-shot分类中corss-domain的泛化能力。当backbone较浅的时候,减少类内方差是非常重要的,而更深的backbone则淡化了这种域影响,所以对于方法的选择不敏感了。
给定未知类的几个标签人类就可以轻松的记住这种新类,当其再次出现的时候,可以轻松识别。对于机器很难,这种任务就是few-shot classfication。已有的主要方法:元学习,即从一组任务中提取并传播可迁移的知识来避免过拟合,提高泛化能力。元学习方法主要分为:model initialization based methods、metric learning methods(本文所用)、hallucination based methods。

如上图:
首先提出的是baseline: 就是常规的源域训练+目标域微调。(迁移学习)
然后提出的是baseline++:用来减少类内差异。具体的做法基本和baseline一样,除了分类器部分:baseline就是常规的线性分类器:
而baseline++是变成了余弦相似性距离:

然后再对这个距离进行softmax,后续一样。所以这个版本就是除了个模值。这就是文中所谓的线、RelationNet性分类器变成了基于距离的分类器。正因为直接优化的是这个余弦距离,所以文中说“更明确”的减少类内方差。当然这个简单的小操作在其他工作中已经用过,文中也说明了这点。

如上图,文中用了三种距离度量学习,都是已发表的工作(MatchingNet、ProtoNet、RelationNet)。
结果
主要包括三个方面:常规目标识别(mini-ImageNet数据集)、细粒度分类(CUB-200-2011数据集)、跨域适应(mini-ImageNet →CUB)。
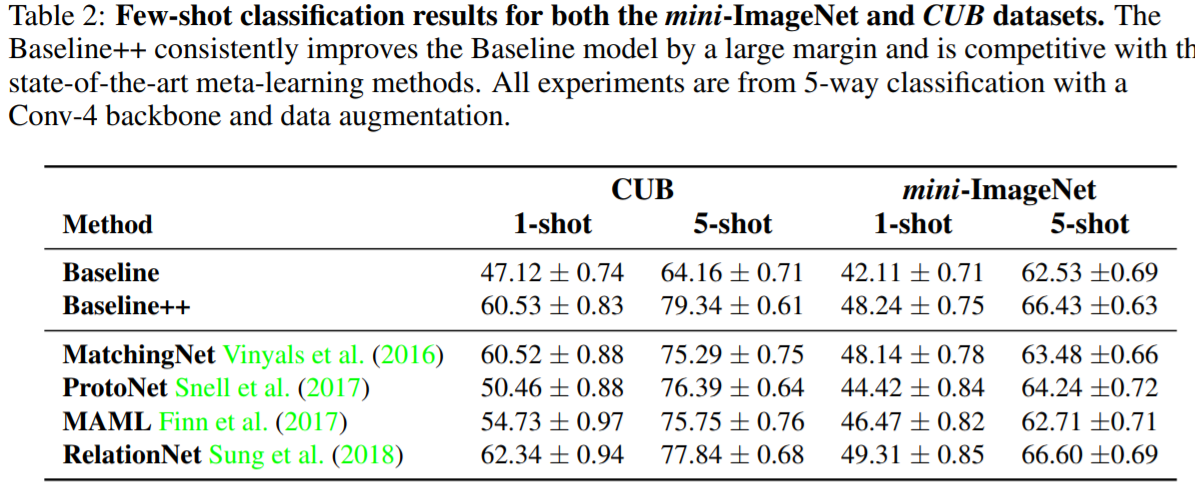
baseline++还是与sota可comparable 的。下面这个是few-shot分类精度与backbone深度的对比:很明显深度越深,不同方法性能的gap影响越小。

最后这个图是说明跨域的问题:baseline反而最抗打,主要可能是因为baseline++中另外减少类内变化会影响适应性。解释稍有点勉强但也说得过去。
 代码:
代码: