这篇稍老一点,18年的用GAN做reid的paper,和上篇19年将输入分解为appearance和structure不同。这篇FD-GAN是希望提到的特征仅仅和id有关,而和姿势无关。所以将输入分解为id+pose。编码器可视化如下:
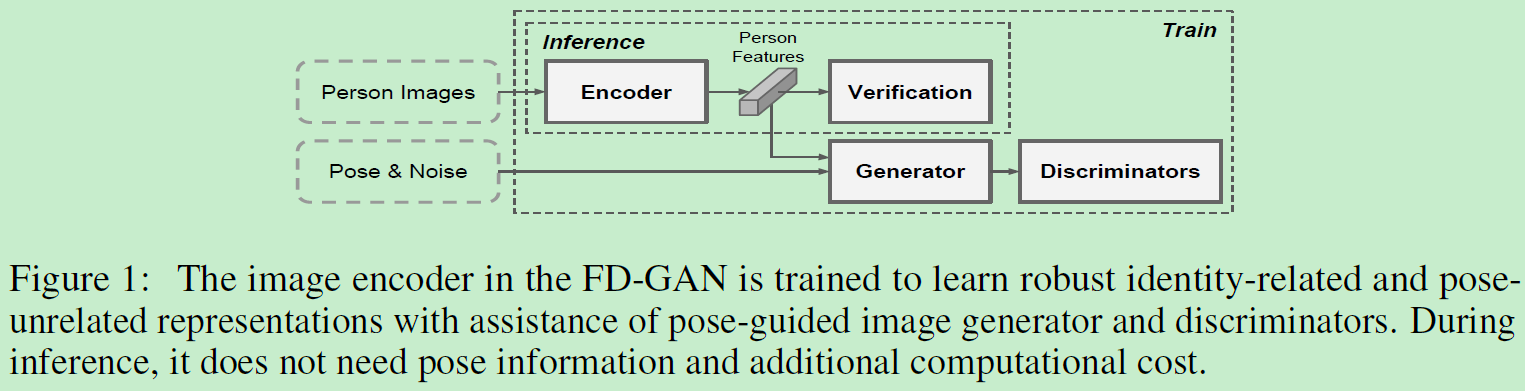
FD-GAN尽量在同一id姿态改变的情况下保持id特征的不变。在推理时又不会增加额外的复杂度。特征学习采用双分支结构,每个分支包括一个图像编码器和一个图像生成器。生成器基于id特征和姿态信息生成新图。感受一下整体框架:
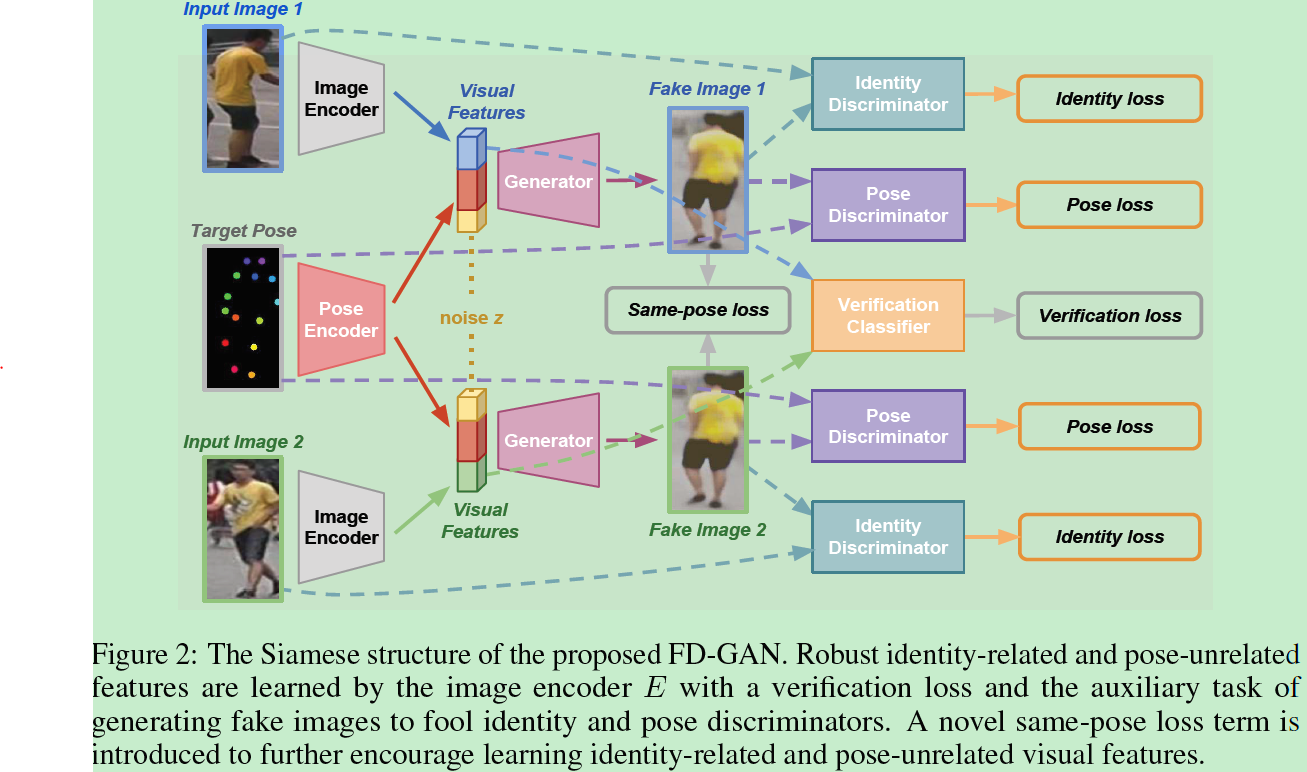
网络结构:
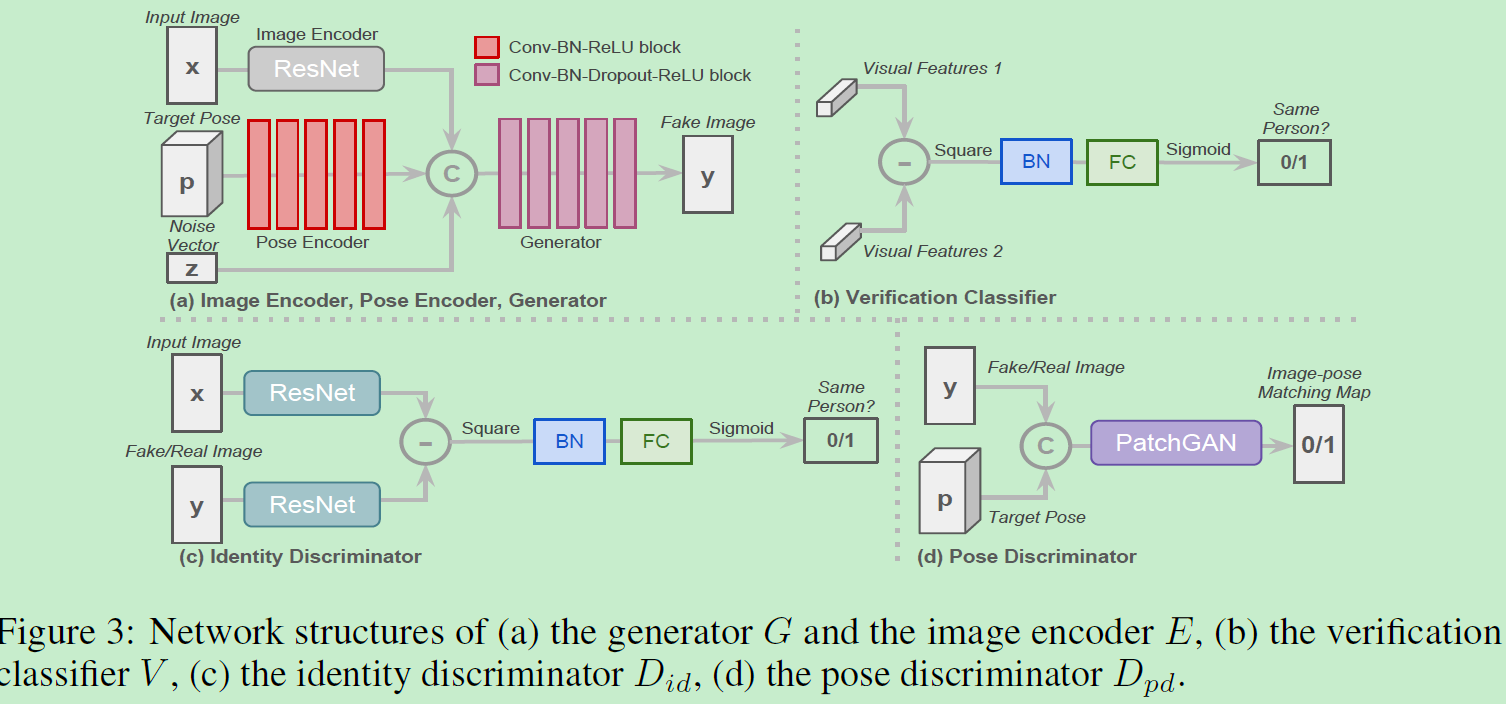
训练过程分三个步骤:
1. 训练一个reid baseline的分类网络
2. 固定E和V,加入G,D来预训练FD-GAN
3. 全局微调
一些副产品:
