一篇关于深度配准技术的综述。
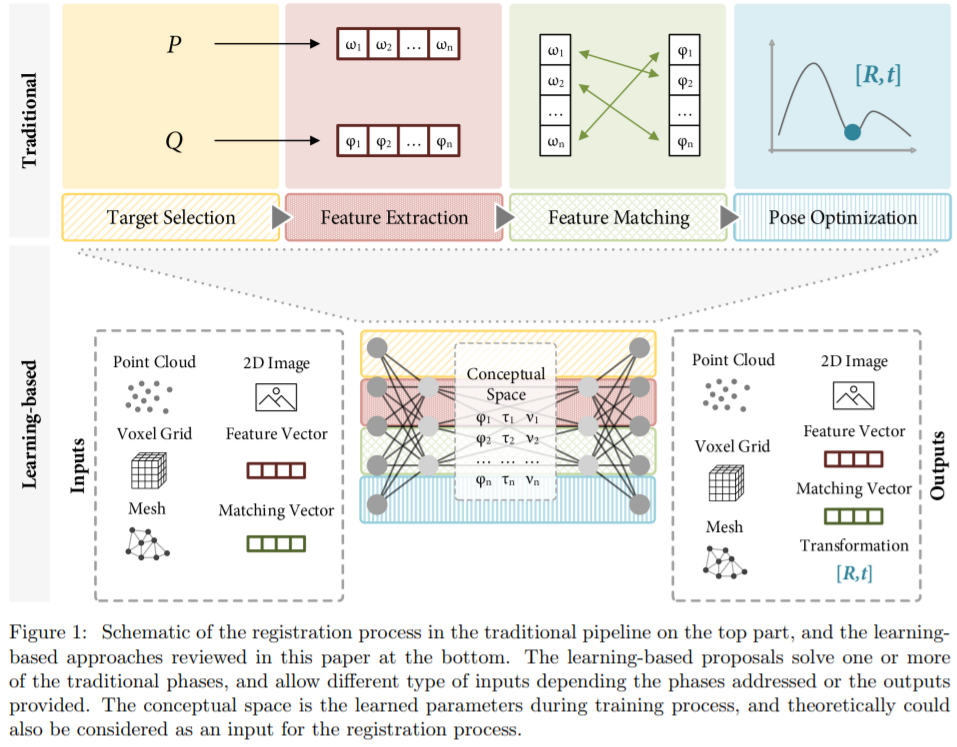
深度学习解决了传统配准技术的某些步骤。对于如下的输入图像:
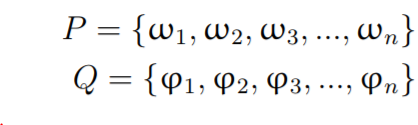
配准的目的是最小化P和Q转换后的对齐误差。即:
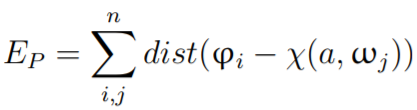
配准过程可以划为三个核心部分:target selection、correspondences and constraints、optimization。这些步骤取决于数据的获取以及格式。所以对于结构化数据和非结构化数据有所区分,结构化数据指存储于离散结构的三维信息,例如深度图、meshes、voxelgrids等,其邻域信息都是已知的。而非结构化信息的往往是存储无规则例如点云。在刚性变化中,计算好的变换关系对于所有数据中的元素都是一样的,而非刚性变换则不然。然而这些变换都没有唯一的结局方案。以下是一些挑战:
- 非刚性变换:Non-rigid Transformation.和刚性变换不同的是,受到非均匀或各向异性的缩放、倾斜和剪切;并进行分段刚性、铰接和自由变形影响。导致转换关系的不精确,导致转换关系的估计参数变多,也带来了噪声。所以对非刚性变换的转换关系建模、减轻复杂度都是很大的挑战。
- 大规模形变:许多算法在数据之间距离较大时易陷入局部最优,这可能与其他因素有关,如有限的数据重叠、范围数据采样率、模糊重叠。
- 实时处理:对于许多任务实时处理是比较重要的,例如自动驾驶。
- 输入数据量和结构:系统承受能力和处理能力。
- 外点筛选和遮挡:一些噪声、外点、遮挡等使配准复杂化。配准和数据质量也有很大关系。