该论文提出一种新的方法从素描来合成完全详细的艺术风格化图像。给定素描图,没有语义标签,给定一个特定风格的参考图。文中引入三个模块来学习,得到了高质量的结果。样例图如下:

介绍
近来的工作主要集中在合成照片上的真实图像,或者从草图上合成卡通图像。本文集中于素描+特定风格。本文的方法更加generic。风格可以指的是art movement、特定的artist style或者特定的artwork。给定输入的素描和风格图,希望可以合成具有颜色和纹理的图像,之前的工作不允许用户指定风格·,本文可以从艺术历史语料库中提取输入素描图和样本参考图像,定义所需的样式,以生成结果。
素描很有的信息非常稀疏,主要组成是线条。模型需要猜测场景的语义组成并合成材料库所提供的语义内容。所提出的方法和两个不同的生成类任务相关:素描到图的合成、风格迁移。前者依赖深度学习来训练成对的样本,主要目的是给素描上色。给定给风格,这些方法不会控制输出。近来的方法用类别做条件,来指导生成。而风格不能类别化,因为风格之间不是严格不重叠。风格迁移任务将一张图的风格迁移到另一张图的内容上。这类方法显然也是不合适的,因为素描图没啥内容,风格迁移不会给素描图补充内容。
本文提出的方法主要包括三个部分:
- Dual Mask Injection:可训练的网络,在卷积网络中对特征映射施加素描约束,以提高内容信度。
- Feature Map Transfer:一种自适应层,它对风格图像的特征图应用一种新的变换,只提取其风格信息而不受其内容的干扰。
- Instance De-Normalization:判别器实例正则化的一种反向过程,它学习将特征映射处理为两部分,以有效地分离风格和内容信息。
相关工作
Image-to-Image Translation: 简称I2I,意在两个不同图像域之间进行转换。应用场景包括物体变形,季节转移,和照片增强。有Pix2Pix实现一对一映射,训练数据成对。而当没有成对训练数据时,利用Cyclegan可以解决。许多多模态方法解决了多对多的映射关系,例如有方法MUNIT、BicycleGAN。但是这些方法不能从粗糙的素描图像生成令人满意的图像,也不能完整的重现参考图的风格,在实验中将会体现。
Neural Style Transfer: 风格迁移主要是将纹理、颜色模式从一张图迁移到另一张图。这可以通过转换多级特征图的统计特性(以伽马矩阵的形式)来实现。后来有许多工作加速前向过程、利用AdaIN来同时捕捉多种风格。然鹅很少关注从素描来实现风格转换,也很少有关注提升风格迁移的质量。
Sketch-to-image Synthesis:本文的任务可以从同时从I2I和NST来考虑。和马-斑马等这种成对数据集不同的是,素描-画的数据是非常严重不平衡的,且是一对多的。而素描图的信息比较稀疏,风格图信息富足且多样。风格迁移考虑色彩模式、纹理类型等,无法太多关注其他重要的艺术属性,如线性与绘画性轮廓、纹理厚重等。风格迁移基本就在很少的数据上训练,通常是一个source+target,而sketch-to-image需要在大数据库上训,学习语义特征。
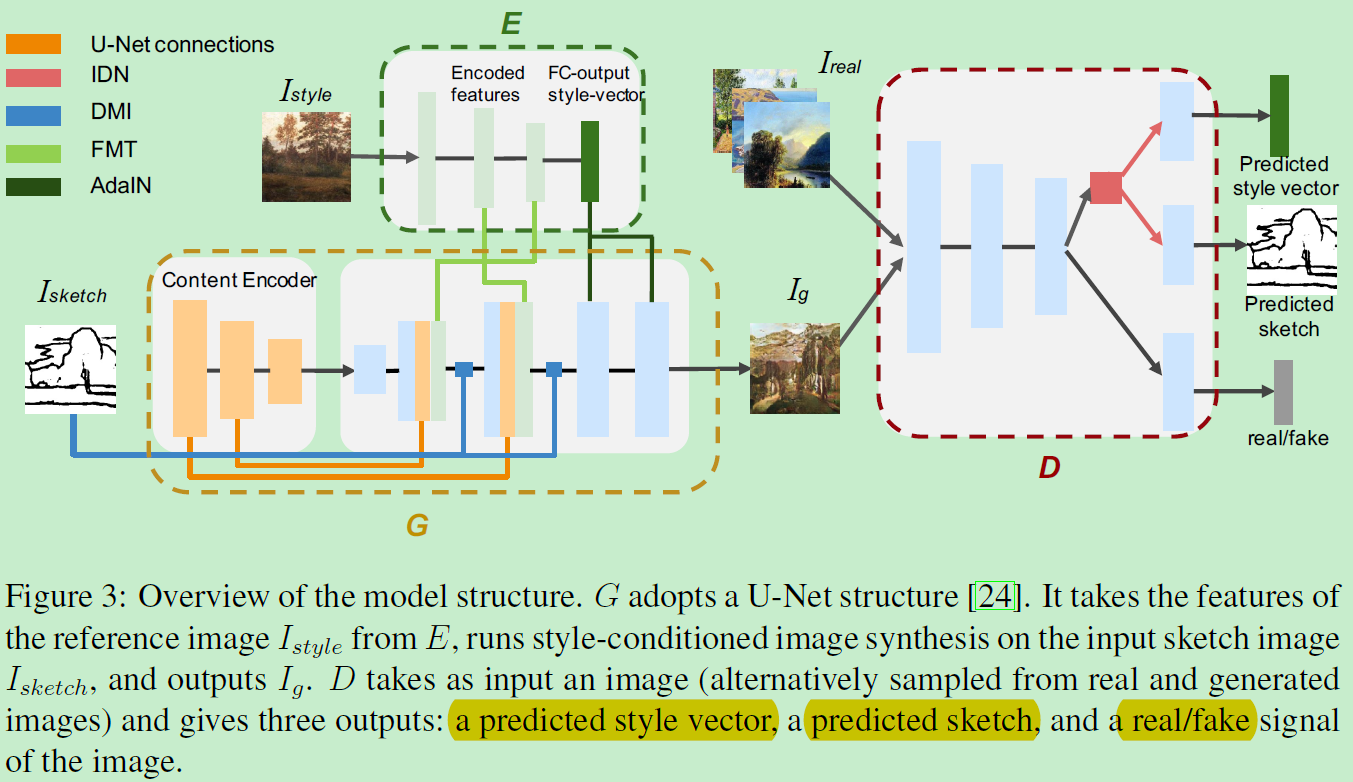
方法
如图,包括三部分: 生成器G、判别器D,预训练好的特征提取E。E是固定的,只提供风格图的特征图和风格图的特征向量。特征图作为G的输入,特征向量作为D的标签。训练G和D以Pix2Pix的方法。
第一个模块:Dual Mask Injection
由于内容部分来源于素描,提供的信息灰常少。当训练生成器产生多样的风格模式时,模型趋向于丢失内容,这在风格迁移中常见,为加强内容提出了DMI模块。在G前向传播的时候,在特征图中施加素描信息。给定f作为风格图的特征,首先将二值素描图进行降采样至同样大小,叫做M。这个M由分别过滤contour-area特征和plain-area特征。

然后进行非线性转换:
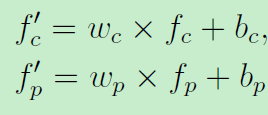
最终DMI模块的输出为:
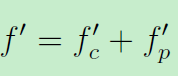
通过在特征图中间直接施加素描,DMI使得生成的图有正确清晰的边缘和组成。

第二个模块:Instance De-Normalization
根据之前条件gan的研究,以条件为输入的判别器不如可以预测条件的判别器。并且对生成器也有易。为了更好指导G,D预测风格图的特征向量和素描。理想条件下,一个具有良好可分离性的判别器可以学到不受内容影响的风格和不受风格影响的内容素描。一些方法已经特定去做这件事了就是分离。但仅仅针对G。本文提出IDN层可以以特征图为输入,然后反转IN并产生风格图向量和内容特征图。在训练阶段,IDN帮助D更好的预测,也帮了G。
在AdaIN或IN中,风格特征图:
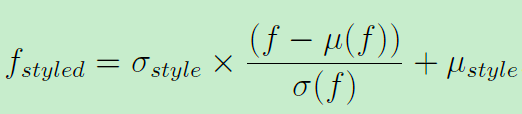
假定原有的特征图f包含了内容信息,一些风格信息(方差和均值)可以用来产生风格化的特征图f-style。所以这样计算后的特征图拥有风格信息的同时保留了原有的内容信息。
而本文倒置,即处理(输入)一个已经得到的风格化图像f_style:首先预测风格的均值和方差。然后分离他们来得到内容特征f:
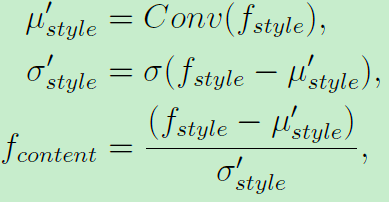
最后就是利用方差和均值来预测风格向量、用f来预测素描内容,实现了风格和内容的分离。
第三个模块:Feature Map Transformation
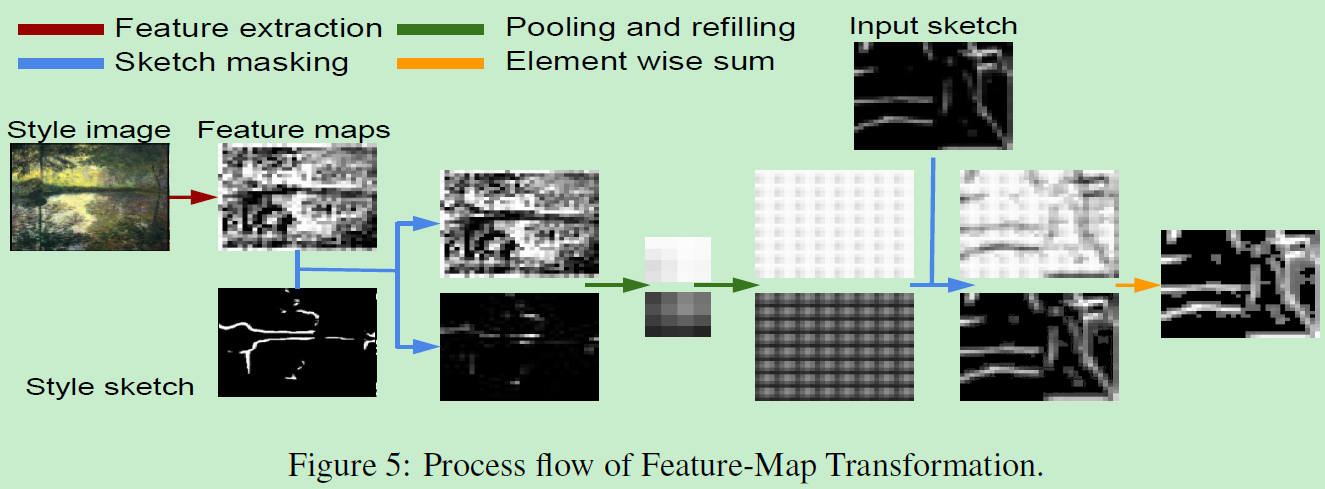
为了利用条件图像生成任务,MUNIT和BicycleGAN模型利用从E中提取的向量。然而本文利用高级抽象特征图。而低微的特征图通常同时拥有风格和内容信息。这种内容信息是不想要的。例如风格图是马,而输入素描是湖,我们不想有任何马的内容被融入到合成图中。为避免内容信息,同时保持丰富的风格,提出FMT,他的输入是:输入的素描、风格图的素描、风格图像的特征图。其中风格图的素描是利用简单的边缘检测器实现。FMT参数固定没有可训练参数。相比AdaIN和Gram矩阵等方法仅仅关注于得到更高级的特征图的统计特性,受限于细节。而FMT提供精确的的指导。
一些和sota的比较:

在人脸合成上的表现: