承接上一篇博客。该论文思路清晰,实验充分,这里大致写一些比较不错的idea。从标题就能看出本文的主要贡献:轻量、鲁棒。利用一个轻量CNN从大规模数据且含大量噪声中来学习一个深度面部表征。 直接谈谈贡献:
- 本文介绍MFM操作,一种特殊的maxout来学习少参数网络。相比于ReLU从数据中学来阈值,MFM采用一种竞争关系来得到更好的泛化能力,适应于不同的数据分布。
- 轻量CNN和MFM一起用来学习一种统一的面部表征。我们按照AlexNet、VGG、ResNet设计了三种轻量网络。所提出的模型在时空复杂度都有很好的表现。
- 通过预训练得到的一种语义自提升方法被设计用来处理大尺度数据中的噪声数据。不连续的数据可以通过概率预测而有效检测出来,然后被移除来训练。
- 所提出的单模型学习到256维深度表征,在各种数据集上:large-scale、video-based、cross-age face recognition、cross-view face recognition等数据集。
相关工作不再赘述,以下是网络结构部分。
1. Max-Feature-Map operation(MFM)
一个规模庞大的数据集通常含有噪声,所以如果噪声不能合适解决,CNN会有偏差。ReLU激活函数通过一个阈值来划分噪声信号和信息信号,这通过相应的激活与抑制来实现。然而这个阈值可能导致尤其是前几个卷积层的信息丢失(视为ReLU的副作用?)。因为这些层类似于Gabor滤波器。为了减轻这个问题,LReLU、PReLU和ELU等被相继提出。考虑到人脑侧抑制等启发,一个卷积层的激活函数应有以下特性:
- 由于大规模数据集通常含有各种类型噪声,我们希望噪声信号和信息信号可被分离。
- 当在图像中有水平的边或线时,对应检测水平信息的神经元应该兴奋而响应垂直信息的神经元应被抑制。
- 神经元的侧抑制是无参的,所以应该不取决于大量数据。
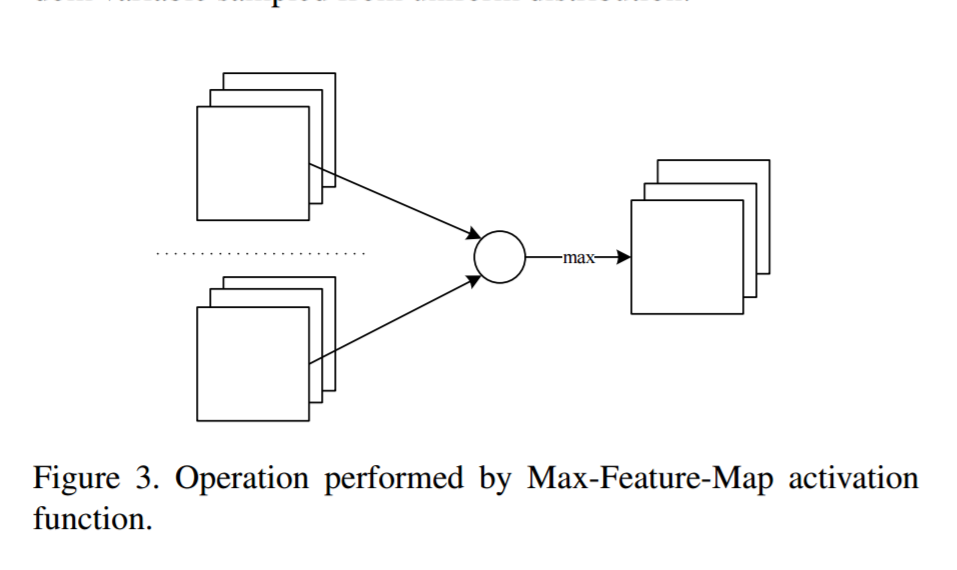
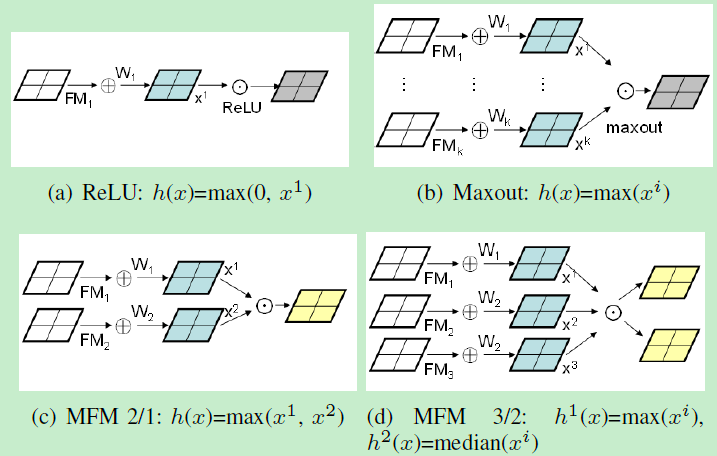
介于此,提出MFM操作,是Maxout activation的拓展。然而其本质不同。Maxout通过大量隐层元来近似一个任意凸函数。更多神经元更好的近似结果。一般来讲Maxout网络要大于ReLU网络。MFM根据max函数来已知一小部分的神经元,所以基于MFM的网络轻量且鲁棒。尽管两者都用max函数,MFM不能视为凸函数估计。我们定义两种MFM操作来获取竞争特征图。下图很清楚:

2. The Light CNN Framework
MMF在CNN中起到类似生物中局部特征选择的角色。MFM在不同的位置挑选不同滤波器学到的最优特征。在反向传播时导致0、1梯度来抑制或激活神经元。伴有MMF的CNN可获得更紧凑的表征,虽然MFM层的梯度是稀疏的。MFM通过激活前面卷积层的特征图的最大值可以获取更多富有竞争力的节点。所以MFM可以实现特征选择并加速生成稀疏连接。
以下是作者按照AlexNet、VGG、ResNet实现的伴有MFM的三个网络,这里直接贴出第二个:因为Network in Network (NIN)可以在卷积层之间做出潜在的特征选择,通过采用小卷积核可以减少网络参数。所以在网络中嵌入NIN和小卷积核的MFM。
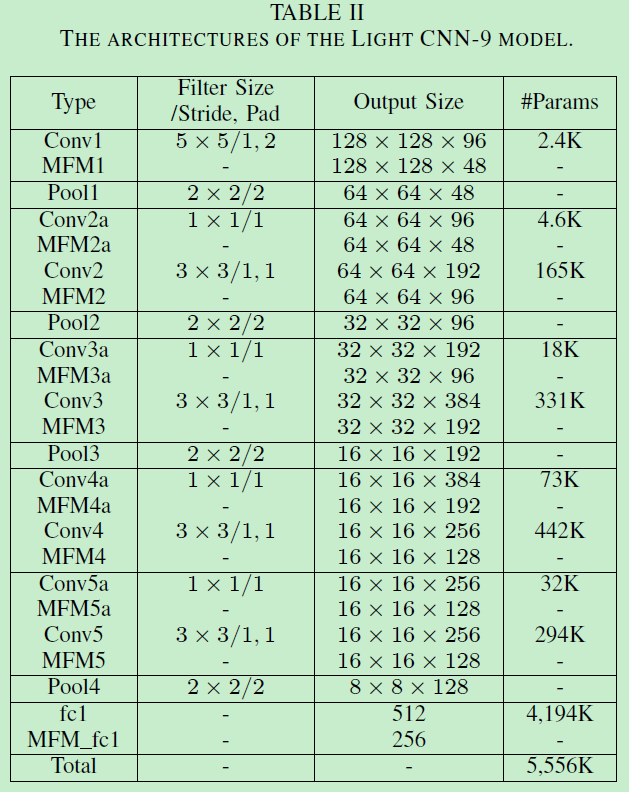
值得注意的是作者去掉了BN:因为BN是有域特征的,即当测试数据和训练数据来自不同域时,BN可能导致失败(这就需要IBN的操作了,即搭配IN来减小域影响)。此外利用FC来代替GAP(global average pool),作者认为高级特征图的每个节点都同时包含语义信息和空间信息,然而这有可能被GAP破坏。作者在FC设置了0.7的dropout,卷积层和除了最后一个FC的权重衰减设为5e-4,而最后一个fc不再担任特征提取角色,所以权重衰减设为5e-3来避免过拟合。卷积层和全连接初始化分别为Xavier和Gaussian。此外特征相似性采用cosine similarity。
some results:
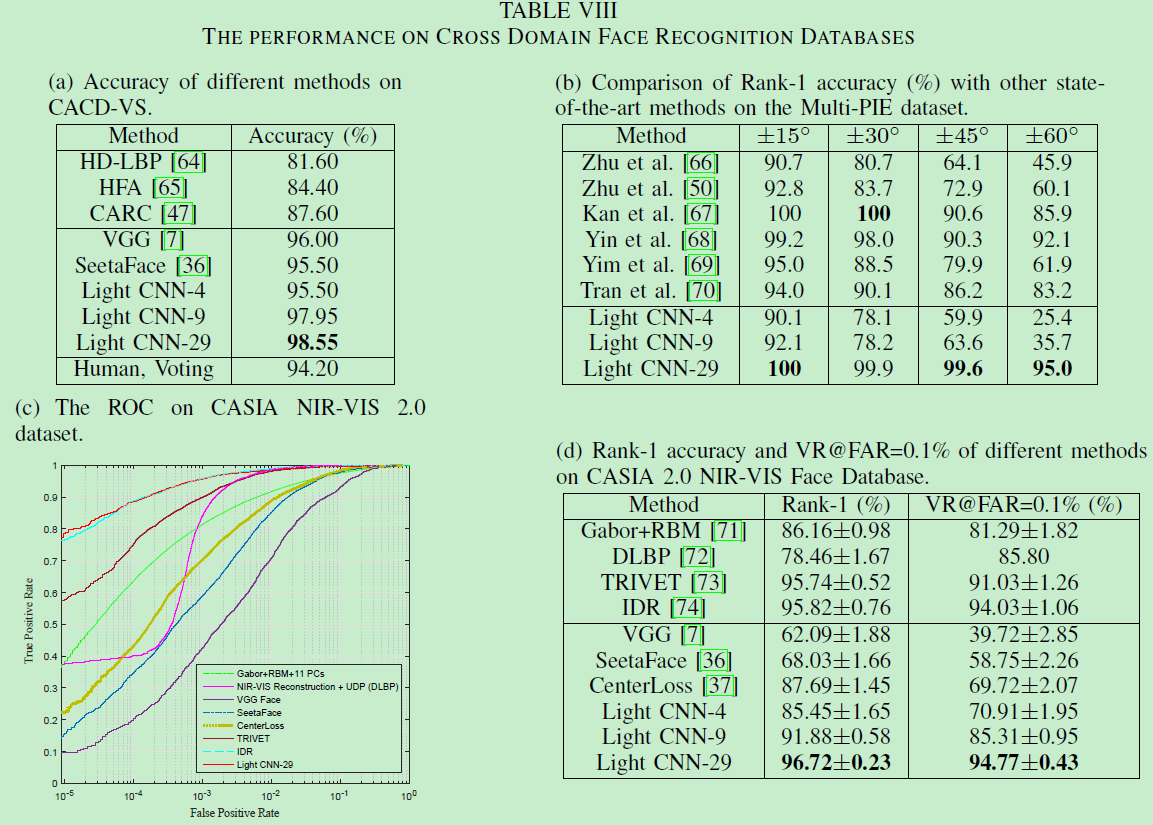
3. 网络分析
MFM操作在轻量CNN中意义重大。下图说明了不同激活函数中,对于人脸表征学习人物来说,MFM表现最优。且MFM3/2优于MFM2/1。
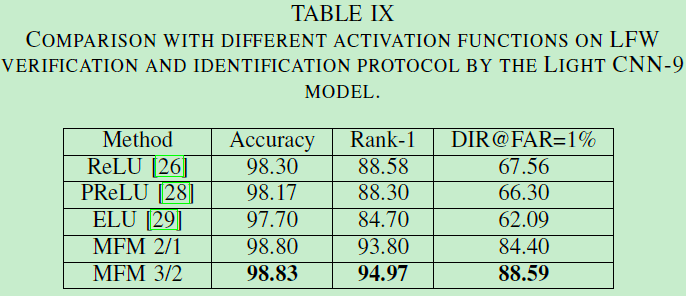
为什么MFM效果这么好呢?原因就是MFM利用了竞争关系而非阈值来激活神经元。由于训练和测试集源于不同数据源,所以MFM有更好的泛化能力。MFM3/2 比 MFM2/1的结果更好,表明当利用MFM时,最好只有一小部分神经元被抑制,所以更多信息被保留在下一卷积层中。也就是说输入与输出神经元个数比应在1~2之间。
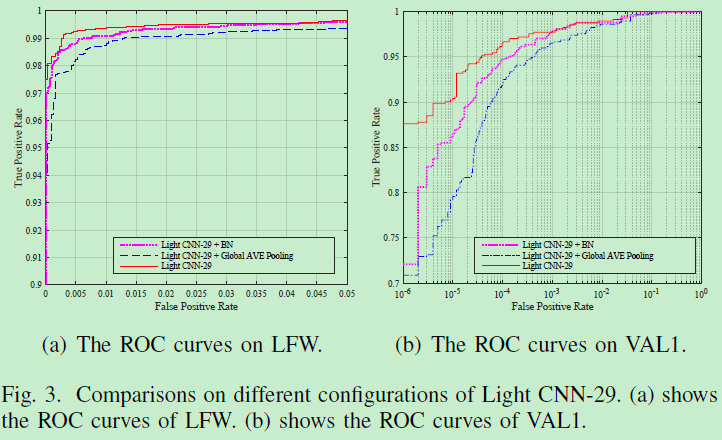
下图表明了BN在域差异问题上的缺憾:没有BN会更好。
4. 结论
受神经元侧抑制和maxout activation的启发,提出一个Max-Feature-Map(MFM)操作,可得到压缩的低维面部表征。卷积层的小核尺寸,Network in Network层、残差块等实现用来缩减参数空间并提高性能。本文的网络结构更小更快。
附:MFM示意图(参考:博客)
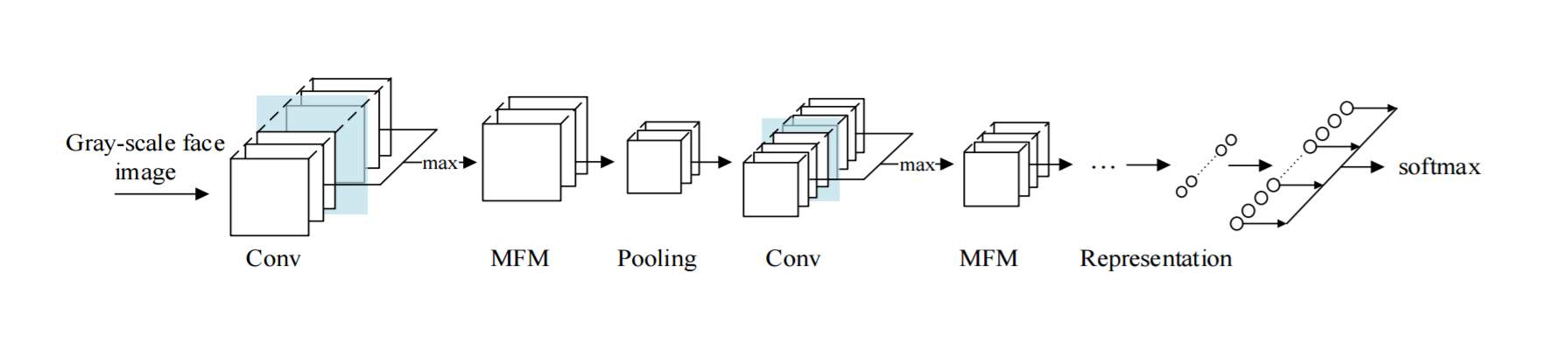
根据上面的MFM示意图,可以看到灰度图像(单通道)输入到两个相同结构的卷积层中,MFM比较两个卷积层中对应的通道,取最大值