环境:
OS:Window10
python:3.7
爬取链家地产上面的数据,两个画面上的数据的爬取
效果,下面的两个网页中的数据取出来
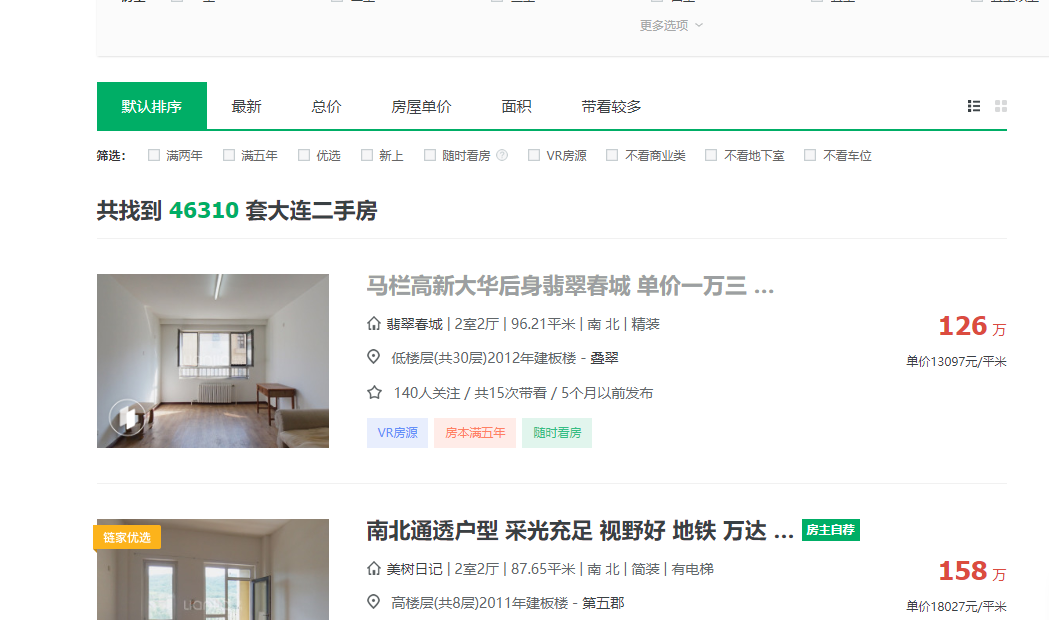
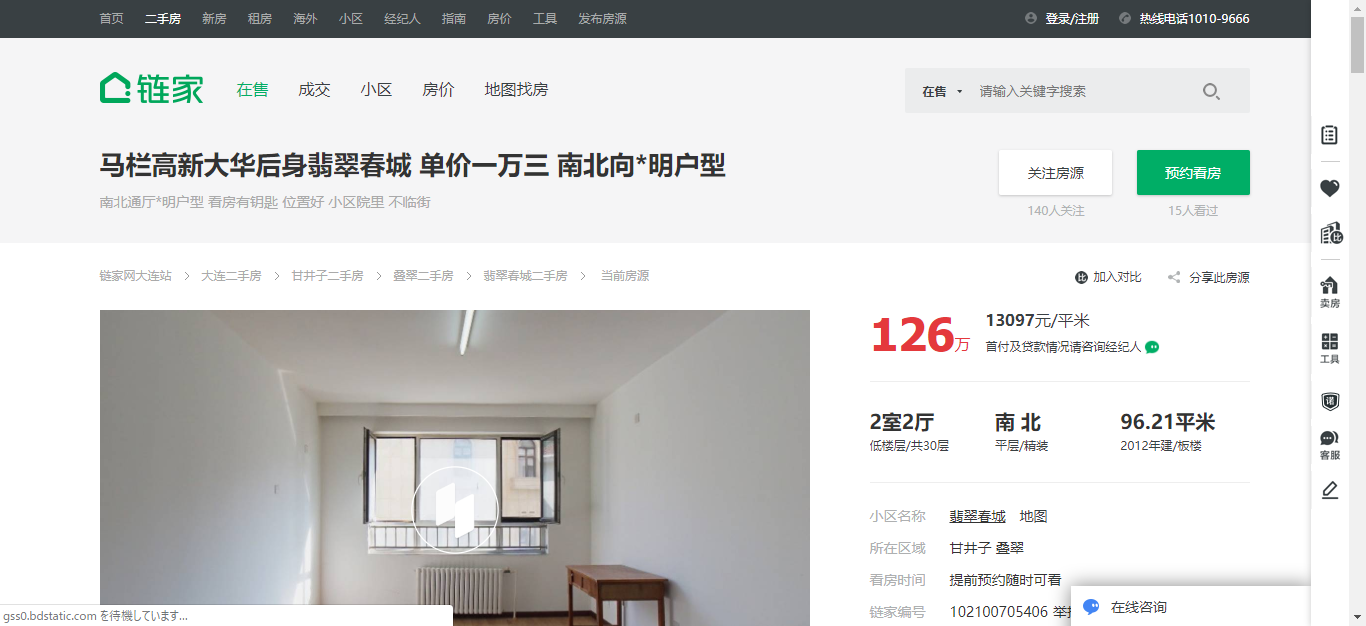
代码
import datetime
import threading
import requests
from bs4 import BeautifulSoup
class LianjiaHouseInfo:
'''
初期化变量的值
'''
def __init__(self):
# 定义自己要爬取的URL
self.url = "https://dl.lianjia.com/ershoufang/pg{0}"
self.path = r"C:pythonProjectLianjia_House"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"}
'''
访问URL
'''
def request(self, param):
# 如果不加的话可能会出现403的错误,所以尽量的都加上header,模仿网页来访问
req = requests.get(param, headers=self.headers)
# req.raise_for_status()
# req.encoding = req.apparent_encoding
return req.text
'''
page設定
'''
def all_pages(self, pageCn):
dataListA = []
for i in range(1, pageCn+1):
if pageCn == 1:
dataListA = dataListA + self.getData(self.url[0:self.url.find("pg")])
else:
url = self.url.format(i)
dataListA = dataListA + self.getData(url)
# self.dataOrganize(dataListA)
'''
数据取得
'''
def getData(self, url):
dataList = []
thread_lock.acquire()
req = self.request(url)
# driver = webdriver.Chrome()
# driver.get(self.url)
# iframe_html = driver.page_source
# driver.close()
# print(iframe_html)
soup = BeautifulSoup(req, 'lxml')
countHouse = soup.find(class_="total fl").find("span")
print("共找到 ", countHouse.string, " 套大连二手房")
sell_all = soup.find(class_="sellListContent").find_all("li")
for sell in sell_all:
title = sell.find(class_="title")
if title is not None:
print("------------------------概要--------------------------------------------")
title = title.find("a")
print("title:", title.string)
housInfo = sell.find(class_="houseInfo").get_text()
print("houseInfo:", housInfo)
positionInfo = sell.find(class_="positionInfo").get_text()
print("positionInfo:", positionInfo)
followInfo = sell.find(class_="followInfo").get_text()
print("followInfo:", followInfo)
print("------------------------詳細信息--------------------------------------------")
url_detail = title["href"]
req_detail = self.request(url_detail)
soup_detail = BeautifulSoup(req_detail, "lxml")
total = soup_detail.find(class_="total")
unit = soup_detail.find(class_="unit").get_text()
dataList.append(total.string+unit)
print("总价:", total.string, unit)
unitPriceValue = soup_detail.find(class_="unitPriceValue").get_text()
dataList.append(unitPriceValue)
print("单价:", unitPriceValue)
room_mainInfo = soup_detail.find(class_="room").find(class_="mainInfo").get_text()
dataList.append(room_mainInfo)
print("户型:", room_mainInfo)
type_mainInfo = soup_detail.find(class_="type").find(class_="mainInfo").get_text()
dataList.append(type_mainInfo)
print("朝向:", type_mainInfo)
area_mainInfo = soup_detail.find(class_="area").find(class_="mainInfo").get_text()
dataList.append(area_mainInfo)
print("面积:", area_mainInfo)
else:
print("広告です")
thread_lock.release()
return dataList
#
# def dataOrganize(self, dataList):
#
# data2 = pd.DataFrame(dataList)
# data2.to_csv(r'C:UserspeiqiangDesktoplagoujob.csv', header=False, index=False, mode='a+')
# data3 = pd.read_csv(r'C:UserspeiqiangDesktoplagoujob.csv', encoding='gbk')
thread_lock = threading.BoundedSemaphore(value=100)
house_Info = LianjiaHouseInfo()
startTime = datetime.datetime.now()
house_Info.all_pages(1)
endTime = datetime.datetime.now()
print("実行時間:", (endTime - startTime).seconds)
运行之后的效果
