案例完整代码、数据见Github
1. 案例背景
用户价值细分是了解用户价值度的重要途径,常用的细分模型包括:基于属性的方法、ABC分类法、聚类法等。
1. 基于属性的方法
常用的细分属性包括:地域、产品类别、用户类别(大客户、普通客户、VIP客户等)、性别、消费等级等。这种细分方法可根据数据库中数据直接得到。
2. ABC分类法
ABC法则是二八法则衍生出的一种法则。不同的是,二八法则强调是抓住关键,ABC法则强调分清主次,将管理对象划分为A、B、C三类。
在ABC法中先将目标数据列倒叙排序,然后做累积百分比统计,最后将百分比在0%-80%划分为A类,80%-90%划分为B类,90%-100%划分为C类。
例:

3. 聚类法
无需任何先验经验,只要指定要划分的群体数量即可。
2. 案例主要应用技术
本案例没有直接使用成熟模型包,而是通过 Python 代码手动实现 RFM 模型。
RFM 模型是根据会员最近一次购买时间 R(Recency)、购买频率 F(Frequency)、购买金额 M(Monetary)计算得出 RFM 得分。
RFM模型基本实现过程:
步骤1:设置截止时间节点(例如2020-6-28)。
步骤2:以今天为时间界限,向前推固定周期(例如1年)。
步骤3:数据预计算。找出各个会员最近购买时间;以会员ID为维度统计每个用户购买频率,将用户多个订单的金额求和得到总订单金额。由此得到R、F、M三个原始数据量。
步骤4:R、F、M分区。对R、F、M分别使用五分位法(三分位也可以,分位数越多划分越详细)做数据区分。需要注意的是,对 R 需要倒过来划分。因为对F、M来说,值越大代表购买频率,订单金额越高,对R来说,值越小代表离截止时间越近,我们需要倒过来划分,离截止时间越近的值划分越大。
步骤5:将三个值组合或相加得到总的RFM得分。RFM总得分的两种计算方式,一种直接将三个值拼接到一起,例如RFM得分为312、333、132;另一种将三个值相加得到一个新的汇总值,例如RFM得分为6、9、6。
根据步骤5产生的两种结果有不同的应用思路:
思路1:基于三个维度值做用户群体划分和解读,对用户的价值度做分析。例如得分为212会员购买频率低,针对购买频率低的客户定期发送促销活动邮件;针对得分为321的会员购买频率高但订单金额低,可以考虑通过关联或搭配销售方式提升金额。
思路2:基于 RFM 的汇总得分评估会员的价值度,并可以做价值度排名;同时,该得分还可以作为输入维度跟其他维度一起作为其他数据分析或数据挖掘的输入变量。
3. 案例数据
数据概况:
- 特征变量数:4
- 数据记录数:86135
- 是否有NA值:有
- 是否有异常值:有
数据集的4个特征变量:
- USERID:用户ID
- ORDERDATE:订单日期
- ORDERID:订单ID
- AMOUNTINFO:订单金额
4. 案例过程
import time import numpy as np import pandas as pd import pymysql # 读取原始数据 dtypes = {'ORDERDATE': object, 'ORDERID': object, 'AMOUNTINFO': np.float} raw_data = pd.read_csv('sales.csv', dtype=dtypes, index_col='USERID') # 数据概览、缺失值审查 print(raw_data.describe()) """ 对DataFrame来说,describe()默认情况下,只返回数字字段。 describe(include='all')返回数据的所有列。 """

从结果看出,最大值30000元,最小值0.5元,经过沟通,最大值正常,为某客户一次性购买多个大型电商品;0.5元订单属于促销优惠券生成的订单,这些订单为用户消费时的优惠券,没有实际意义,因此可以去掉这些数据,所有低于1元的订单均有这个问题。
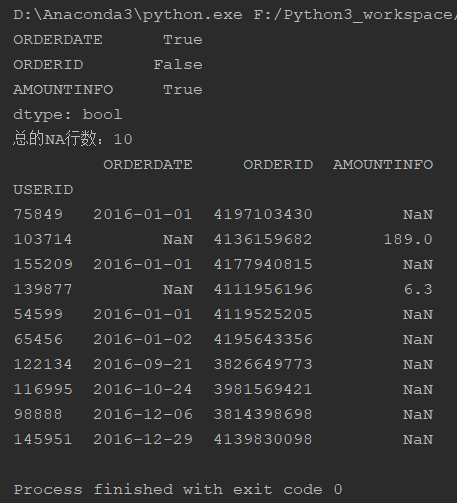
na_cols = raw_data.isnull().any(axis=0) # 查看每一列是否有缺失值 print(na_cols) na_lines = raw_data.isnull().any(axis=1) # 查看每一行是否有缺失值 print('总的NA行数:{}'.format(na_lines.sum())) print(raw_data[na_lines]) # 查看具有缺失值的行信息
# 异常值处理 sales_data = raw_data.dropna() sales_data = sales_data[sales_data['AMOUNTINFO'] > 1] # 丢弃金额≤1 # 日期格式转换 sales_data['ORDERDATE'] = pd.to_datetime(sales_data['ORDERDATE'], format='%Y-%m-%d') """ format参数以原始数据字符串格式来写,只有格式对应才能实现解析 """ print(sales_data.dtypes)

日期转换的目的是计算时间间隔,算出 R 距离指定日期的天数。
计算RFM得分
# 计算R、F、M recency_value = sales_data['ORDERDATE'].groupby(sales_data.index).max() # 计算最近一次订单时间 frequency_value = sales_data['ORDERDATE'].groupby(sales_data.index).count() # 计算频率 monetary_value = sales_data['AMOUNTINFO'].groupby(sales_data.index).sum() # 计算总金额 """ groupby() 函数可以进行数据的分组以及分组后的组内运算。 print(df["评分"].groupby([df["地区"],df["类型"]]).mean()) 该条语句的功能:输出数据中不同地区不同类型的评分的平均值。 """
这三行代码都是以原始数据框的索引为主键(以用户 ID 为汇总维度)分别对 ORDERDATE 求最大值、对 ORDERDATE 做计数统计、对 AMOUNTINFO 求和,得到 R、F、M 的原始值。
# 计算R、F、M得分 deadline_date = pd.datetime(2017, 1, 1) # 指定时间点,计算其他时间与该时间的距离 r_interval = (deadline_date - recency_value).dt.days # 计算 R 间隔 r_score = pd.cut(r_interval, 5, labels=[5, 4, 3, 2, 1]) # 计算 R 得分 f_score = pd.cut(frequency_value, 5, labels=[1, 2, 3, 4, 5]) # 计算 F 得分 m_score = pd.cut(monetary_value, 5, labels=[1, 2, 3, 4, 5]) # 计算 M 得分
这里定义时间节点2017-1-1,通过数据框相减得到时间间隔天数对象,并对该对象使用 dt.days 方法获得天数数值。
然后对 R、F、M 使用分位数法做间隔划分,这里使用 pd.cut(),默认设置为5份,通过 labels 标签指定区间标签(注意R的标签与F、M标签顺序相反)。
# 合并数据框 rfm_list = [r_score, f_score, m_score] rfm_cols = ['r_score', 'f_score', 'm_score'] # 设置R、F、M三个维度列名 rfm_pd = pd.DataFrame(np.array(rfm_list).T, dtype=np.int32, columns=rfm_cols, index=frequency_value.index) # 建立R、F、M数据框 """ np.array().transpose()等价于np.array().T都表示数组的转置 dtype=np.int32 等价于 dtype='int32' """
先建立R、F、M三个维度的值列表和名称列表,用于生成数据框时指定数据和标签。
然后使用 pd.DataFrame 建立数据框,设置列名并指定索引为用户 ID(由于R、F、M三个Series的索引相同,这里随便指定为 frequency_value.index)。
使用 np.array 将列表转换为矩阵,此时矩阵形状(3,59676),使用 transpose 转置。
# 计算RFM总得分 # 方法一:加权得分 rfm_pd['rfm_wscore'] = rfm_pd['r_score']*0.6 + rfm_pd['f_score']*0.3 + rfm_pd['m_score']*0.1 # 方法二:RFM组合 rfm_pd_tmp = rfm_pd.copy() rfm_pd_tmp['r_score'] = rfm_pd_tmp['r_score'].astype('str') rfm_pd_tmp['f_score'] = rfm_pd_tmp['f_score'].astype('str') rfm_pd_tmp['m_score'] = rfm_pd_tmp['m_score'].astype('str') rfm_pd['rfm_comb'] = rfm_pd_tmp['r_score'].str.cat(rfm_pd_tmp['f_score']).str.cat(rfm_pd_tmp['m_score']) print(rfm_pd.head())
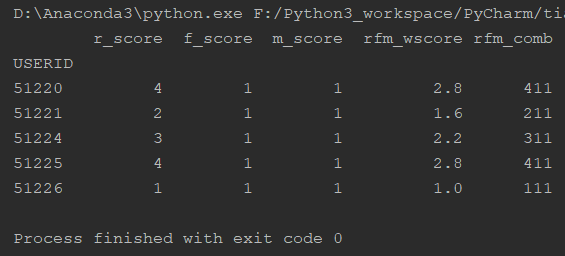
方法二中,由于原始数据为了加权计算,设置为数值型,因此这里转换为字符串型。 为不影响原始数据,通过 copy() 得到一个副本,然后将副本中的三列转换为字符串型。
提示:设置数据类型时一般两种思路:一种是创建数据框时通过 dtype 指定,第二种是在创建好的数据框中使用 astype() 转换。
建立数据库连接
# 连接mysql数据库 # 设置要写库的数据库连接信息 table_name = 'sales_rfm_score' # 要写库的表名 # 数据库基本信息 config = {'host': '127.0.0.1', 'user': 'root', 'password': '****', 'port': 3306, 'database': 'python_data', 'charset': 'gb2312'} con = pymysql.connect(**config) # 建立mysql连接 cursor = con.cursor() # 获得游标 # 查找数据库是否存在目标表,如果没有则新建 cursor.execute('show tables') table_object = cursor.fetchall() # 通过fetchall方法获取数据 table_list = [] # 创建库列表 for t in table_object: # 循环读出多有库 table_list.append(t[0]) # 每个库追加到列表 if not table_name in table_list: # 如果目标表没有创建 cursor.execute(""" CREATE TABLE %s ( userid VARCHAR (20), r_score int(2), f_score int(2), m_score int(2), rfm_wscore DECIMAL (10, 2), rfm_comb VARCHAR (10), insert_date VARCHAR (20) )ENGINE=InnoDB DEFAULT CHARSET=gb2312 """ % table_name) # 创建新表 # 将数据写入数据库 user_id = rfm_pd.index # 索引列 rfm_wscore = rfm_pd['rfm_wscore'] # RFM加权得分列 rfm_comb = rfm_pd['rfm_comb'] # RFM组合得分列 timestamp = time.strftime('%Y-%m-%d', time.localtime(time.time())) # 写库日期 print('Begin to insert data into table {0}...'.format(table_name)) # 输出开始写库的提示信息 for i in range(rfm_pd.shape[0]): # 设置循环次数并依次循环 insert_sql = "INSERT INTO `%s` VALUES ('%s',%s,%s,%s,%s,'%s','%s')" % (table_name, user_id[i], r_score.iloc[i], f_score.iloc[i], m_score.iloc[i], rfm_wscore.iloc[i], rfm_comb.iloc[i], timestamp) # 写库SQL依据 cursor.execute(insert_sql) # 执行SQL语句,execute函数里面要用双引号 con.commit() # 提交命令 cursor.close() # 关闭游标 con.close() # 关闭数据库连接 print('Finish inserting, total records is: %d' % (i + 1)) # 打印写库结果
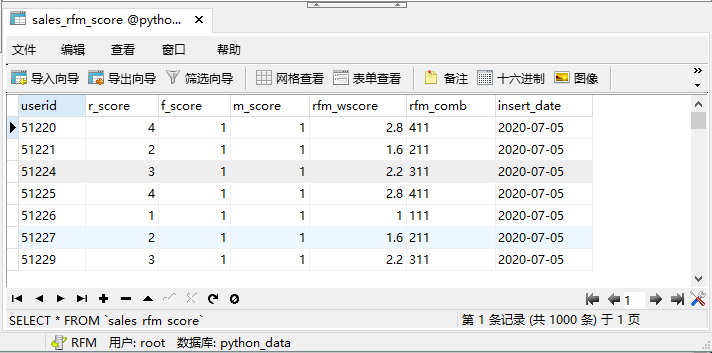
使用 Navicat 打开对应的数据库表,如图:
5. 案例结论
在RFM划分时,将区间划分为5份,定义为:高、中、一般、差、非常差5个级别,分别对应R、F、M中的5/4/3/2/1。
基于RFM得分业务方得到这样的结论:
1. 公司的会员99%以上的客户消费状态不容乐观,主要体现在消费频率低R、消费金额低M。——经过分析,主要由(ID为74270)的客户消费金额非常高影响的,导致做5分位时收到最大值的影响,区间向大值域偏移。
2. 公司中一些典型客户的整个贡献特征明显,重点是 RFM 为555的用户(ID为74270)。
3. 本周表现处于一般水平以上的用户的比例(RFM三个维度均在3以上)相对上周环比增长了1.3%。体现了活跃度的提升。
4. 本周低价值(RFM得分为111以上)用户名单中,新增1221个新用户。
结论的应用和部署:
1. ID为74270客户给与重点关怀和管理
2. 新增客户也需要重点关注和处理。最主要的还是通过会员渠道拉动会员,防止客户流失,订单金额是次要因素。
3. 每周一根据上周新数据运行一次该模型。
案例注意点:
1. 具体划分几个区间,需要跟业务方确认。一般划分为3-5个区间。
2. 权重的确认,不同时期业务关注点不同,权重需要调整。
3. ID为74270的用户,这种极值影响需要跟业务部门沟通确认才能进行处理,否则影响区间划分。