调用WebService返回的数据或是解析HTTP协议(见5.1节)实现网络数据交互。
存储格式一般为XML或是JSON。本节主要讲解这两种类型的数据解析。
XML被设计用来结构化、存储以及传输信息。
JSON:JavaScript对象表示法(JavaScript Object Notation), 是一种轻量级的数据交换格式, 易于人阅读和编写, 同时也易于机器解析和生成。
3.4.1 解析XML
常见的XML解析器分别为DOM解析器、SAX解析器和PULL解析器。另,对于频繁用XML交互的话可以使用xStream框架,一个简单的工具包,用来把对象序列化成xml配置文件,并且也可以把xml反序化成对象。
第一种方式:DOM解析器:
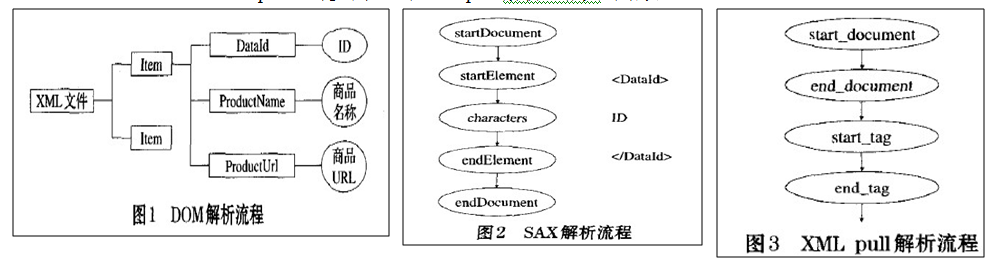
DOM是基于树形结构的的节点或信息片段的集合,允许开发人员使用DOM API遍历XML树、检索所需数据。分析该结构通常需要加载整个文档和构造树形结构,然后才可以检索和更新节点信息。
Android完全支持DOM 解析。利用DOM中的对象,可以对XML文档进行读取、搜索、修改、添加和删除等操作。
DOM的工作原理:使用DOM对XML文件进行操作时,首先要解析文件,将文件分为独立的元素、属性和注释等,然后以节点树的形式在内存中对XML文件进行表示,就可以通过节点树访问文档的内容,并根据需要修改文档——这就是DOM的工作原理。
DOM实现时首先为XML文档的解析定义一组接口,解析器读入整个文档,然后构造一个驻留内存的树结构,这样代码就可以使用DOM接口来操作整个树结构。
优缺点:由于DOM在内存中以树形结构存放,因此检索和更新效率会更高。但是对于特别大的文档,解析和加载整个文档将会很耗资源。 当然,如果XML文件的内容比较小,采用DOM是可行的。
常用的DoM接口和类:
- Document:该接口定义分析并创建DOM文档的一系列方法,它是文档树的根,是操作DOM的基础。
- Element:该接口继承Node接口,提供了获取、修改XML元素名字和属性的方法。
- Node:该接口提供处理并获取节点和子节点值的方法。
- NodeList:提供获得节点个数和当前节点的方法。这样就可以迭代地访问各个节点。
- DOMParser:该类是Apache的Xerces中的DOM解析器类,可直接解析XML文件。
第二种方式:SAX解析器:
Simple API for XML解析器是基于事件的解析器,事件驱动的流式解析方式是,从文件的开始顺序解析到文档的结束,不可暂停或倒退。它的核心是事件处理模式,主要是围绕着事件源以及事件处理器来工作的。当事件源产生事件后,调用事件处理器相应的处理方法,一个事件就可以得到处理。在事件源调用事件处理器中特定方法的时候,还要传递给事件处理器相应事件的状态信息,这样事件处理器才能够根据提供的事件信息来决定自己的行为。
SAX解析器的优点是解析速度快,占用内存少。非常适合在Android移动设备中使用。
SAX的工作原理:SAX的工作原理简单地说就是对文档进行顺序扫描,当扫描到文档(document)开始与结束、元素(element)开始与结束、文档(document)结束等地方时通知事件处理函数,由事件处理函数做相应动作,然后继续同样的扫描,直至文档结束。
在SAX中,事件源是org.xml.sax包中的XMLReader,它通过parser()方法来解析XML文档,并产生事件。
事件处理器是org.xml.sax包中ContentHander、DTDHander、ErrorHandler,以及EntityResolver这4个接口。XMLReader通过相应事件处理器注册方法setXXXX()来完成的与ContentHander、DTDHander、ErrorHandler,以及EntityResolver这4个接口的连接。(可知,我们需要XmlReader 以及DefaultHandler来配合解析xml。)
常用的SAX接口和类:
- Attrbutes:用于得到属性的个数、名字和值。
- ContentHandler:定义与文档本身关联的事件(例如,开始和结束标记)。大多数应用程序都注册这些事件。
- DTDHandler:定义与DTD关联的事件,但并不完整。要对DTD进行语法分析,请使用可选的DeclHandler。
- DeclHandler是SAX的扩展。不是所有的语法分析器都支持它。
- EntityResolver:定义与装入实体关联的事件。只有少数几个应用程序注册这些事件。
- ErrorHandler:定义错误事件。许多应用程序注册这些事件以便用它们自己的方式报错。
- DefaultHandler:它提供了这些接口的缺省实现。在大多数情况下,为应用程序扩展DefaultHandler并覆盖相关的方法要比直接实现一个接口更容易。
第三种方式:PULL解析器:
Android并未提供对Java StAX API的支持。但是,Android附带了一个pull解析器,其工作方式类似于StAX。它允许用户的应用程序代码从解析器中获取事件,这与SAX解析器自动将事件推入处理程序相反。
PULL解析器的运行方式和SAX类似,基于事件的模式。不同的是,在PULL解析过程中返回的是数字,且我们需要自己获取产生的事件然后做相应的操作,而不像SAX那样由处理器触发一种事件的方法,执行我们的代码。
- 读取到xml的声明返回 START_DOCUMENT;
- 读取到xml的结束返回 END_DOCUMENT ;
- 读取到xml的开始标签返回 START_TAG 调用XmlPullParser.next()循环读取节点
- 读取到xml的结束标签返回 END_TA 用switch处理
- 读取到xml的文本返回 TEXT
PULL解析器小巧轻便,解析速度快,简单易用,非常适合在Android移动设备中使用,Android系统内部在解析各种XML时也是用PULL解析器,Android官方推荐开发者们使用Pull解析技术。Pull解析技术是第三方开发的开源技术,它同样可以应用于JavaSE开发。
PULL 的工作原理:XML pull提供了开始元素和结束元素。当某个元素开始时,我们可以调用parser.nextText从XML文档中提取所有字符数据。当解释到一个文档结束时,自动生成EndDocument事件。
常用的XML pull的接口和类:
- XmlPullParser:XML pull解析器是一个在XMLPULL VlAP1中提供了定义解析功能的接口。
- XmlSerializer:它是一个接口,定义了XML信息集的序列。
- XmlPullParserFactory:这个类用于在XMPULL V1 API中创建XML Pull解析器。
- XmlPullParserException:抛出单一的XML pull解析器相关的错误。
[附加]第四种方式:Android.util.Xml类
在Android API中,另外提供了Android.util.Xml类,同样可以解析XML文件,使用方法类似SAX,也都需编写Handler来处理XML的解析,但是在使用上却比SAX来得简单 ,如下所示:
MyHandler myHandler=new MyHandler(); Android.util.Xml.parse(ur1.openConnection().getlnputStream(), Xml.Encoding.UTF-8, myHandler);
几种解析技术的比较与总结:
对于Android的移动设备而言,因为设备的资源比较宝贵,内存是有限的,所以我们需要选择适合的技术来解析XML,这样有利于提高访问的速度。
1) DOM在处理XML文件时,将XML文件解析成树状结构并放入内存中进行处理。当XML文件较小时,我们可以选DOM,因为它简单、直观。
2) SAX则是以事件作为解析XML文件的模式,它将XML文件转化成一系列的事件,由不同的事件处理器来决定如何处理。XML文件较大时,选择SAX技术是比较合理的。虽然代码量有些大,但是它不需要将所有的XML文件加载到内存中。这样对于有限的Android内存更有效,而且Android提供了一种传统的SAX使用方法以及一个便捷的SAX包装器。 使用Android.Util.Xml类,从示例中可以看出,会比使用 SAX来得简单。
3) XML pull解析并未像SAX解析那样监听元素的结束,而是在开始处完成了大部分处理。这有利于提早读取XML文件,可以极大的减少解析时间,这种优化对于连接速度较漫的移动设备而言尤为重要。对于XML文档较大但只需要文档的一部分时,XML Pull解析器则是更为有效的方法。
Dom 解析 import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; import com.leo.sax_parser.model.Person; public class DomParser { public static List<Person> readXMLByDom(InputStream input) throws ParserConfigurationException, SAXException, IOException { List<Person> persons = new ArrayList<Person>(); DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document document = builder.parse(input); Element root = document.getDocumentElement(); NodeList nodes = root.getElementsByTagName("person"); for (int i = 0; i < nodes.getLength(); i++) { //person对象个数 Element element = (Element) nodes.item(i); Person person = new Person(); person.setId(element.getAttribute("id")); NodeList childNodes = element.getChildNodes(); for (int j = 0; j < childNodes.getLength(); j++) { // 对象中属性的个数:id,name,age,phoneNumber Node child = childNodes.item(j); // 解决getChildNodes().getLength()与实际不符的问题 if (child.getNodeType() != Node.ELEMENT_NODE) { continue; } Element childElement = (Element) child; Log.i("DomParser", childElement.getNodeName() + ":" + childElement.getTextContent().trim()); if ("name".equals(childElement.getNodeName())) { person.setName(childElement.getTextContent().trim()); } else if ("age".equals(childElement.getNodeName())) { person.setAge(Integer.parseInt(childElement.getTextContent().trim())); } else if ("phoneNumber".equals(childElement.getNodeName())) { person.setPhoneNumber(Integer.parseInt(childElement.getFirstChild().getNodeValue())); } } persons.add(person); } return persons; } }
[代码]SAX 解析 import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.helpers.DefaultHandler; public class SAX_handler extends DefaultHandler { private List<Person> persons; private String perTag; private Person person; public List<Person> getPersons() { return persons; } @Override public void startDocument() throws SAXException { persons = new ArrayList<Person>(); //初始化用于存放person对象的persons,用于存放读取到的相应的信息。 } @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { if ("person".equals(localName)) { for (int i = 0; i < attributes.getLength(); i++) { Log.i(Tag, "attributeName:" + attributes.getLocalName(i) + "attributeValue:" + attributes.getValue(i)); person = new Person(); person.setId(attributes.getValue(i)); } } perTag = localName; } @Override public void characters(char[] ch, int start, int length) throws SAXException { String data = new String(ch, start, length); if (!"".equals(data.trim())) Log.i(Tag, "Content:" + data); if ("name".equals(perTag)) { person.setName(data); } else if ("age".equals(perTag)) { person.setAge(Integer.parseInt(data)); } else if ("phoneNumber".equals(perTag)) { person.setPhoneNumber(Integer.parseInt(data)); } } @Override public void endElement(String uri, String localName, String qName) throws SAXException { if (person != null&&"person".equals(localName)) { persons.add(person); person = null; } perTag = null; } @Override public void endDocument() throws SAXException { Log.i(Tag, "endDocument"); } }
Pull 解析 import org.xmlpull.v1.XmlPullParser; import org.xmlpull.v1.XmlPullParserException; import android.util.Xml; public class PullParser { public static List<Person> readXML(InputStream inputstream) throws XmlPullParserException, IOException { List<Person> persons = null; XmlPullParser parser = Xml.newPullParser(); parser.setInput(inputstream, "UTF-8"); int eventCode = parser.getEventType(); Person person = null; while (eventCode != XmlPullParser.END_DOCUMENT) { switch (eventCode) { case XmlPullParser.START_DOCUMENT: persons = new ArrayList<Person>(); break; case XmlPullParser.START_TAG: if ("person".equals(parser.getName())) { person = new Person(); person.setId(parser.getAttributeValue(0)); }else if(person != null){ if ("name".equals(parser.getName())) { person.setName(parser.nextText()); }else if("age".equals(parser.getName())){ person.setAge(Integer.parseInt(parser.nextText())); }else if("phoneNumber".equals(parser.getName())){ person.setPhoneNumber(Integer.parseInt(parser.nextText())); } } break; case XmlPullParser.END_TAG: if ("person".equals(parser.getName()) && person!= null) { persons.add(person); person =null; } break; default: break; } eventCode = parser.next(); } return persons; } }
XML和JSON的区别:
- XML的主要组成成分是element、attribute和element content。
- JSON的主要组成成分是object、array、string、number、boolean(true/false)和null。
- JSON相比XML的不同之处:没有结束标签,更短,读写的速度更快,能够使用内建的 JavaScript eval() 方法进行解析,使用数组,不使用保留字。总之: JSON 比 XML 更小、更快,更易解析。
- XML需要选择怎么处理element content的换行,而JSON string则不须作这个选择。
- XML只有文字,没有预设的数字格式,而JSON则有明确的number格式,这样在locale上也安全。
- XML映射数组没大问题,就是数组元素tag比较重复冗余。JSON 比较易读。
- JSON的true/false/null也能容易统一至一般编程语言的对应语义。
解析XML:SAX可以快速扫描一个大型的XML文档,当它找到查询标准时就会立即停止,然后再处理之。DOM是把XML全部加载到内存中建立一棵树之后再进行处理。所以DOM不适合处理大型的XML【会产生内存的急剧膨胀】。
解析JSON:Android自带了JSON解析的相关API(org.json)。谷歌的Gson,阿里的FastJson,还有一个jackJson。有人说jackJson解析速度快,大数据时FastJson要比Gson效率高,小数据时反之。
3.4.2 解析Json
A、服务器端将数据转换成json字符串
首先、服务器端项目要导入Gson的jar包到BuiltPath中。然后将数据转为json字符串,核心函数是:
public static String createJsonString(Object value){ Gson gson = new Gson(); String str = gson.toJson(value); return str; }
B、客户端将json字符串转换为相应的javaBean
首先客户端也要导入gson的两个jar包,json的jar就不需要导入了(因为android已经集成了json的jar包)
1、客户端获取json字符串
public class HttpUtil{ public static String getJsonContent(String urlStr){ try{// 获取HttpURLConnection连接对象 URL url = new URL(urlStr); HttpURLConnection conn = (HttpURLConnection) url.openConnection(); conn.setConnectTimeout(3000); conn.setDoInput(true); conn.setRequestMethod("GET"); int respCode = httpConn.getResponseCode();// 获取相应码 if (respCode == 200) return ConvertStream2Json(httpConn.getInputStream()); } catch (IOException e){ e.printStackTrace(); } return ""; } private static String ConvertStream2Json(InputStream inputStream){ String jsonStr = ""; ByteArrayOutputStream out = new ByteArrayOutputStream();//相当于内存输出流 byte[] buffer = new byte[1024]; int len = 0; try{// 将输入流转移到内存输出流中 while ((len = inputStream.read(buffer, 0, buffer.length)) != -1) out.write(buffer, 0, len); jsonStr = new String(out.toByteArray());// 将内存流转换为字符串 } catch (IOException e){ e.printStackTrace(); } return jsonStr; } }
2、使用泛型获取javaBean(核心函数)
public static <T> T getPerson(String jsonString, Class<T> cls) { T t = null; try { Gson gson = new Gson(); t = gson.fromJson(jsonString, cls); } catch (Exception e) { } return t; } public static <T> List<T> getPersons(String jsonString, Class<T> cls) { List<T> list = new ArrayList<T>(); try { Gson gson = new Gson(); list = gson.fromJson(jsonString, new TypeToken<List<cls>>() { }.getType()); } catch (Exception e) { } return list; } public static List<Map<String, Object>> listKeyMaps(String jsonString) { List<Map<String, Object>> list = new ArrayList<Map<String, Object>>(); try { Gson gson = new Gson(); list = gson.fromJson(jsonString, new TypeToken<List<Map<String, Object>>>() { }.getType()); } catch (Exception e) { } return list; }
3.4.3 Protocol Buffers
1概述
ProtocolBuffer是用于结构化数据串行化的灵活、高效、自动的方法,有如XML,不过它更小、更快、也更简单。你可以定义自己的数据结构,然后使用代码生成器生成的代码来读写这个数据结构。你甚至可以在无需重新部署程序的情况下更新数据结构。目前仅提供了 C++、Java、Python 三种语言的 API。
2工作原理
你首先需要在一个 .proto 文件中定义你需要做串行化的数据结构信息。每个ProtocolBuffer信息是一小段逻辑记录,包含一系列的键值对。
一旦你定义了自己的报文格式(message),你就可以运行ProtocolBuffer编译器,将你的 .proto 文件编译成特定语言的类。这些类提供了简单的方法访问每个字段(像是 query() 和 set_query() ),像是访问类的方法一样将结构串行化或反串行化。
你可以在不影响向后兼容的情况下随意给数据结构增加字段,旧有的数据会忽略新的字段。所以如果使用ProtocolBuffer作为通信协议,你可以无须担心破坏现有代码的情况下扩展协议。
3优缺点
ProtocolBuffer拥有多项比XML更高级的串行化结构数据的特性:
更简单,小3-10倍,快20-100倍,更少的歧义,可以方便的生成数据存取类
当然,ProtocolBuffer并不是在任何时候都比XML更合适,例如ProtocolBuffer无法对一个基于标记文本的文档建模,因为你根本没法方便的在文本中插入结构。另外,XML是便于人类阅读和编辑的,而ProtocolBuffer则不是。还有XML是自解释的,而 ProtocolBuffer仅在你拥有报文格式定义的 .proto 文件时才有意义。
4使用方法
下载包( http://code.google.com/p/protobuf/downloads/ ),包含了Java、Python、C++的ProtocolBuffer编译器,用于生成你需要的IO类。构建和安装你的编译器,跟随README的指令就可以做到。
一旦你安装好了,就可以跟着编程指导( http://code.google.com/apis/protocolbuffers/docs/tutorials.html )来选择语言-随后就是使用ProtocolBuffer创建一个简单的应用了。
1) 所需文件:proto.exe, protobuf-java-2.4.1.jar
2) 建立一个工程TestPb,在下面建立一个proto文件,用来存放【.proto】文件
3) 将proto.exe放在工程目录下
4) 建立一个msg.proto文件:cmd 打开命令工具,输入命令:protoc --java_out=./ msg.proto
5) 再次进入目录后会发现该目录多了一个文件夹,即以该proto的package命名的的目录,会产生一个Msg.java的文件,这时这个文件就可以使用到我们的java或者 android 工程了。
6) 导如jar包到工程中,就可以使用protobuf了
7) Protobuf 实现Socket通信
3.4.4 FlatBuffers
1概述
FlatBuffers是一个开源的、跨平台的、高效的、提供了C++/Java接口的序列化工具库。它是Google专门为游戏开发或其他性能敏感的应用程序需求而创建。尤其更适用于移动平台,这些平台上内存大小及带宽相比桌面系统都是受限的,而应用程序比如游戏又有更高的性能要求。它将序列化数据存储在缓存中,这些数据既可以存储在文件中,又可以通过网络原样传输,而不需要任何解析开销。
2特点
- 对序列化数据的访问不需要打包和拆包——它将序列化数据存储在缓存中,这些数据既可以存储在文件中,又可以通过网络原样传输,而没有任何解析开销;
- 内存效率和速度——访问数据时的唯一内存需求就是缓冲区,不需要额外的内存分配。
- 扩展性、灵活性——它支持的可选字段意味着不仅能获得很好的前向/后向兼容性(对于长生命周期的游戏来说尤其重要,因为不需要每个新版本都更新所有数据);
- 最小代码依赖——仅仅需要自动生成的少量代码和一个单一的头文件依赖,很容易集成到现有系统中。
- 强类型设计——尽可能使错误出现在编译期,而不是等到运行期才手动检查和修正;
- 使用简单——生成的C++代码提供了简单的访问和构造接口;而且如果需要,通过一个可选功能可以用来在运行时高效解析Schema和类JSON格式的文本;
- 跨平台——支持C++、Java,而不需要任何依赖库;在最新的gcc、clang、vs2010等编译器上工作良好;
3 FlatBuffers和Protocol Buffers以及Json的比较:
FlatBuffers的功能和Protocol Buffers很像,他们的最大不同点是在使用具体的数据之前,FlatBuffers不需要解析/解包的过程。同时, FlatBuffers的引用比Protocol Buffers方便很多,只需要包含两三个头文件即可
JSON作为数据交换格式,被广泛用户各种动态语言之间(当然也包括静态语言)。它的优点是可读性好,同时它的最大的缺点那就是解析时的性能问题了。而且因为它的动态类型特点,你的代码可能还需要多写好多类型、数据检查逻辑。
在做 Android 开发的时候,JSON 是最常用的数据序列化技术。我们知道,JSON 的可读性很强,但是序列化和反序列化性能却是最差的。解析的时候,JSON 解析器首先,需要在内存中初始化一个对应的数据结构,这个事件经常会消耗 100ms ~ 200ms2;解析过程中,要产生大量的临时变量,造成 Java 虚拟机的 GC 和内存抖动,解析 20KB 的数据,大概会消耗 100KB 的临时内存2。FlatBuffers 就解决了这些问题。
4使用方法
1) 编写一个用来定义你想序列化的数据的schema文件(又称IDL),数据类型可以是各种大小的int、float,或者是string、array,或者另一对象的引用,甚至是对象集合;
2) 各个数据属性都是可选的,且可以设置默认值。
3) 使用FlatBuffer编译器flatc生成C++头文件或者Java类,生成的代码里额外提供了访问、构造序列化数据的辅助类。生成的代码仅仅依赖flatbuffers.h;
4) 使用FlatBufferBuilder类构造一个二进制buffer。你可以向这个buffer里循环添加各种对象,而且很简单,就是一个单一函数调用;
5) 保存或者发送该buffer
6) 当再次读取该buffer时,你可以得到这个buffer根对象的指针,然后就可以简单的就地读取数据内容;
简单来说,FlatBuffers 的使用方法是,首先按照使用特定的 IDL 定义数据结构 schema,然后使用编译工具 flatc 编译 schema 生成对应的代码,把生成的代码应用到工程中即可。
首先,我们需要得到 flatc,这个需要从源码编辑得到。从 GitHub 上 Clone 代码,
|
$ git clone https://github.com/google/flatbuffers |
在 Mac 上,使用 Xcode 直接打开 build/Xcode/ 里面项目文件,编译运行,即可在项目根目录生成我们需要的 flatc 工具。也可以使用 cmake 编辑,例如在 Linux 上,运行如下命令即可:
|
$ cmake -G "Unix Makefiles" $ make |