Distributed TensorFlow
Client: A client is typically a program that builds a TensorFlow graph and constructs a tensorflow::Session to interact with a cluster. Client are typically written in Python or C++. A single client process can directly interact with multiple TensorFlow servers, and a single server can serve multiple clients.
Cluster: A TensorFlow cluster comprises(包括) a one or more "jobs", each divided into lists of one or more "tasks". A cluster is typically dedicated(专用) to a particular high-level objective, such as training a neural network, using many machines in parallel. A cluster is defined by a tf.train.ClusterSpec object.
Job: A job comprises(包括) a list of "tasks", which typically serve a common purpose. For example, a job named ps (for "parameter server") typically hosts nodes that store and update variables; while a job named worker typically hosts stateless nodes that perform compute-intensive tasks. The tasks in a job typically run on different machines. The set of job roles is flexible: for example, a worker may maintain some data.
Master service: An RPC service that provides remote access to a set of distributed devices, and acts as a session target. The master service implements the tensorflow:Session interface, and is responsible for coordinating work across one or more "worker services". All TensorFlow servers implement the master service.
Task: A task corresponds to a specific TensorFlow server, and typically corresponds to a single process. A task belongs to a particular "job" and is identified by its index within that job's list of tasks.
TensorFlow server: A process running a tf.train.Server instance, which is a member of a cluster, and exports a "master service" and "worker service".
Worker service: An RPC service that executes parts of a TensorFlow graph using its local devices. A worker service implements worker_service.proto. All TensorFlow serves implement the worker service.
Create a cluster
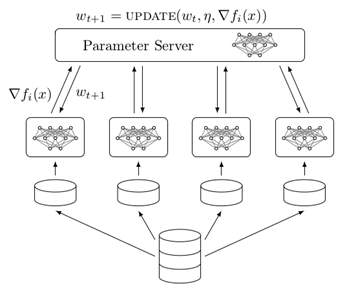
A Tensorflow "cluster" is a set of "tasks" that participate in the distributed executing of a Tensorflow graph. Each task is associated with a TensorFlow "server", which contains a "master" that can be used to create session, and a "worker" that executes operation in the graph. A cluster can also be divided into one or more "jobs", where each job contains one or more tasks.
To create a cluster, you start one Tensorflow server per task in the cluster. Each task typically runs on a different machine, but you can run multiple tasks on the same machine(e.g to control different GPU devices). In each task, do the following:
-
Create a tf.train.ClusterSpec that describes all of the tasks in the cluster. This should be the same for each task.
-
Create a tf.train.Server, passing the tf.train.ClusterSpec to constructor, and identifying the local task with a job name and task index.
A tf.train.Server object contains a set of local devices, a set of connections to other tasks in its tf.train.ClusterSpec, and a tf.Session that can use these to perform a distributed computat-
Ion. Each server is a member of a specific name job and has a task index within that job. A server can communicate with any other server in the cluster.
Replicated training
A common training configuration, called "data parallelism", involves multiple tasks in a worker job training the same model on different mini-batches of data, updating shared parameters hosted in one or more tasks in a ps job. All tasks typically run on different machines. There are many ways to specify this structure in Tensorflow, and we are building libraries that will simply the work of specifying a replicated model. Possible approaches include:
In-graph replication: In this approach, the client builds a single tf.Graph that contains one set of parameters(in tf.Variable nodes pinned to /job:ps); and multiple copies of the compute-
Intensive part of the model, each pinned to a different task in /job:worker.
Between-graph replication: In this approach, there is a separate client for each /job:worker task, typically in the same process as the worker task. Each client builds a similar graph containing the parameters(pinned to /job:ps as before using tf.train.replica_devide_setter to map them deterministically to the same tasks); and a single copy of the compute-intensive part of the model, pinned to the local task in /job:worker.
Asynchronous training. In this approach, each replica of the graph has an independent training loop that executes without coordination. It is compatible with both forms of replication above.
Synchronous training: In this approach, all of the replicas read the same values for the current parameters, compute gradients in parallel, and then apply them together. It is compatible with in-graph replication(e.g using gradient averaging as int the CIFAR-10 multi-GPU trainer), and between-graph replication(e.g using the tf.train.SysnReplicasOptimizer).
TensorFlow Architecture
The Tensorflow runtime is a cross-platform library. Figure 1 illustrates its general architecture. A C API separates user level code in different languages from the core runtime.
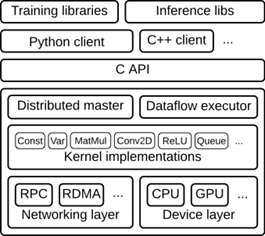
This document focuses on the following layers:
Client:
Defines the computation as a dataflow graph.
Initiates graph execution using a session.
Distributed Master:
Prunes a specific subgraph from the graph, as defined by the arguments to Session.run().
Partitions the subgraph into multiple pieces that run in different processes and devices.
Distributes the graph pieces to worker services.
Initiates graph piece execution by worker services.
Worker Services(one for each task)
Schedule the execution of graph operations using kernel implementations appropriate to the available hardware(CPUs,GPUs,etc).
Send and receive operation results to and from other worker services.
Kernel Implementations
Perform the computation for individual graph operations.
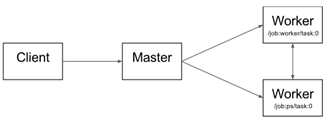
This Figure illustrates the interaction of these components. "/job:worker/task:0" and
/job:ps/task:0" are both tasks with worker services. "PS" stands for "parameter server": a task responsible for storing and updating the model's parameters. Other tasks send updates to these parameters as they work on optimizing the parameters. This particular division of labor between tasks is not required, but it is common for distributed training.
Note that the Distributed Master and Worker Service only exist in distributed TensorFlow. The single-process version of TensorFlow includes a special Session implementation that does everyting the distributed master does but only communicates with devices in the local process.
Client
User write the client TensorFlow program that builds the computation graph. This program can either directly compose individual operations or use a convenience library like the Estimator API to compose neural network layers and other high-level abstractions. The client creates a session, which sends the graph definition to the distributed master as a tf.GraphDef protocol buffer. When the client evaluates a node or nodes in the graph, the evaluation triggers a call to the distributed master to initiate computation.

In this Figure, the client has built a graph that applies weights(w) to a feature vector(x), adds a bias term(b) and saves the result in a variable(s).
Distributed master
The distributed master:
Prunes the graph to obtain the subgraph required to evaluate the nodes requested by the client, partitions the graph to obtain graph pieces for each participating device, and caches these pieces so that they may be re-used in subsequent steps.

Since the master sees the overall computation for a step, it applies standard optimizations such as common subexpression elimination and constant folding. It then coordinates execution of the optimized subgraphs across a set of tasks.
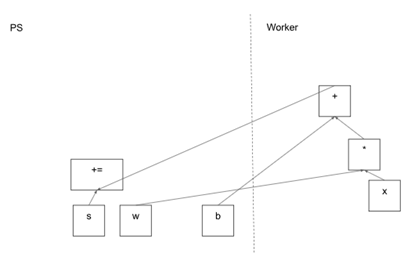
This figure shows a possible partition of our example graph. The distributed master has grouped the model parameters in order to place them together on the parameter server.
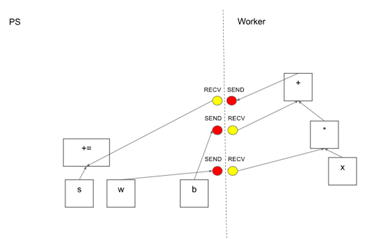
Where graph edges are cut by the partition, the distributed master inserts send and receive nodes to pass information between the distributed tasks.
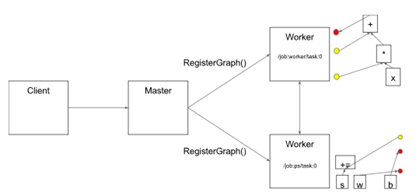
The distributed master then ships the graph pieces to the distributed tasks.
Worker Service
The worker service in each task: handle requests from the master, schedules the execution of the kernels for the operations that comprise a local subgraph, and mediates direct communication between tasks.
We optimize the worker service for running large graphs with low overhead. Our current implementation can execute tens of thousands of subgraphs per second, which enables a large number of replicas to make rapid, fine-grained training steps. The worker service dispatches kernels to local devices and runs kernels in parallel when possible, for example by using multiple CPU cores or GPU streams.
We specialize Send and Recv operations for each pair of source and destination device types:
Transfers between local CPU and GPU devices use the cudaMemcpyAsync() API to overlap computation and data transfer.
Transfers between two local GPUs use peer-to-peer DMA, to avoid an expensive copy via the host CPU.
For transfers between tasks, TensorFlow uses multiple protocols, including:
gRPC over TCP
RDMA over Converged Ethernet.

Kernel Implementations
The runtime contains over 200 standard operations, including mathematical, array manipulation, control flow, and state management operations. Each of these operations can have kernel implementations optimized for a variety of devices. Many of the operation kernels are implemented using Eigen::Tensor, which uses C++ templates to generate efficient parallel code for multicore CPUs and GPUs; however, we liberally use libraries like cuDNN where a more efficient kernel implementation is possible.