关系型和非关系型数据库
非关系型数据库分类
由于非关系型数据库本身天然的多样性,以及出现的时间较短,因此,不想关系型数据库,有几种数据库能够一统江山,非关系型数据库非常多,并且大部分都是开源的。
这些数据库中,其实实现大部分都比较简单,除了一些共性外,很大一部分都是针对某些特定的应用需求出现的,因此,对于该类应用,具有极高的性能。依据结构化方法以及应用场合的不同,主要分为以下几类:
1).面向高性能并发读写的key-value数据库:key-value数据库的主要特点即使具有极高的并发读写性能,Redis,Tokyo Cabinet,Flare就是这类的代表
2).面向海量数据访问的面向文档数据库:这类数据库的特点是,可以在海量的数据中快速的查询数据,典型代表为MongoDB以及CouchDB
3).面向可扩展性的分布式数据库:这类数据库想解决的问题就是传统数据库存在可扩展性上的缺陷,这类数据库可以适应数据量的增加以及数据结构的变化



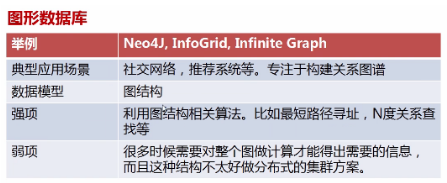
关系型数据库VS非关系型数据库
关系型数据库的最大特点就是事务的一致性:传统的关系型数据库读写操作都是事务的,具有ACID的特点,这个特性使得关系型数据库可以用于几乎所有对一致性有要求的系统中,如典型的银行系统。
但是,在网页应用中,尤其是SNS应用中,一致性却不是显得那么重要,用户A看到的内容和用户B看到同一用户C内容更新不一致是可以容忍的,或者说,两个人看到同一好友的数据更新的时间差那么几秒是可以容忍的,因此,关系型数据库的最大特点在这里已经无用武之地,起码不是那么重要了。
相反地,关系型数据库为了维护一致性所付出的巨大代价就是其读写性能比较差,而像微博、facebook这类SNS的应用,对并发读写能力要求极高,关系型数据库已经无法应付(在读方面,传统上为了克服关系型数据库缺陷,提高性能,都是增加一级memcache来静态化网页,而在SNS中,变化太快,memchache已经无能为力了),因此,必须用新的一种数据结构存储来代替关系数据库。
关系数据库的另一个特点就是其具有固定的表结构,因此,其扩展性极差,而在SNS中,系统的升级,功能的增加,往往意味着数据结构巨大变动,这一点关系型数据库也难以应付,需要新的结构化数据存储。
于是,非关系型数据库应运而生,由于不可能用一种数据结构化存储应付所有的新的需求,因此,非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。
关系型数据库的优缺点
关系型数据库最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组织
优点:
1、易于维护:都是使用表结构,格式一致;
2、使用方便:SQL语言通用,可用于复杂查询;
3、复杂操作:支持SQL,可用于一个表以及多个表之间非常复杂的查询。
缺点:
1、读写性能比较差,尤其是海量数据的高效率读写;
2、固定的表结构,灵活度稍欠;
3、高并发读写需求,传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。
非关系型数据库的优缺点
非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等。
优点:
1、格式灵活:存储数据的格式可以是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。
2、速度快:nosql可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘;
3、高扩展性;
4、成本低:nosql数据库部署简单,基本都是开源软件。
缺点:
1、不提供sql支持,学习和使用成本较高;
2、无事务处理;
3、数据结构相对复杂,复杂查询方面稍欠。
参考: