函数的独占时间
给出一个非抢占单线程CPU的 n 个函数运行日志,找到函数的独占时间。
每个函数都有一个唯一的 Id,从 0 到 n-1,函数可能会递归调用或者被其他函数调用。
日志是具有以下格式的字符串:function_id:start_or_end:timestamp。例如:"0:start:0" 表示函数 0 从 0 时刻开始运行。"0:end:0" 表示函数 0 在 0 时刻结束。
函数的独占时间定义是在该方法中花费的时间,调用其他函数花费的时间不算该函数的独占时间。你需要根据函数的 Id 有序地返回每个函数的独占时间。
示例 1:
输入:
n = 2
logs =
["0:start:0",
"1:start:2",
"1:end:5",
"0:end:6"]
输出:[3, 4]
说明:
函数 0 在时刻 0 开始,在执行了 2个时间单位结束于时刻 1。
现在函数 0 调用函数 1,函数 1 在时刻 2 开始,执行 4 个时间单位后结束于时刻 5。
函数 0 再次在时刻 6 开始执行,并在时刻 6 结束运行,从而执行了 1 个时间单位。
所以函数 0 总共的执行了 2 +1 =3 个时间单位,函数 1 总共执行了 4 个时间单位。
说明:
- 输入的日志会根据时间戳排序,而不是根据日志Id排序。
- 你的输出会根据函数Id排序,也就意味着你的输出数组中序号为 0 的元素相当于函数 0 的执行时间。
- 两个函数不会在同时开始或结束。
- 函数允许被递归调用,直到运行结束。
- 1 <= n <= 100


1 import java.util.List; 2 import java.util.Stack; 3 4 public class Solution { 5 public int[] exclusiveTime(int n, List<String> logs) { 6 Stack<Integer> stack = new Stack<>(); 7 int[] res = new int[n]; 8 String[] s = logs.get(0).split(":"); 9 stack.push(Integer.parseInt(s[0])); 10 int i = 1, time = Integer.parseInt(s[2]); 11 while (i < logs.size()) { 12 s = logs.get(i).split(":"); 13 while (time < Integer.parseInt(s[2])) { 14 res[stack.peek()]++; 15 time++; 16 } 17 if (s[1].equals("start")) 18 stack.push(Integer.parseInt(s[0])); 19 else { 20 res[stack.peek()]++; 21 time++; 22 stack.pop(); 23 } 24 i++; 25 } 26 return res; 27 } 28 }


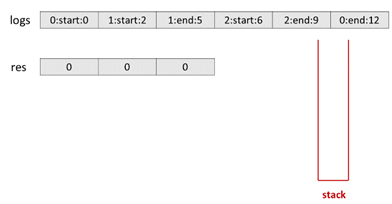



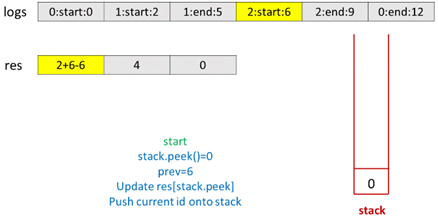
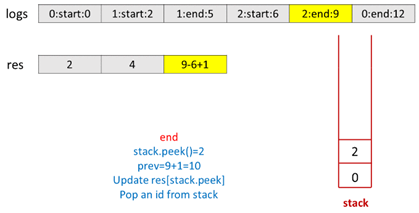

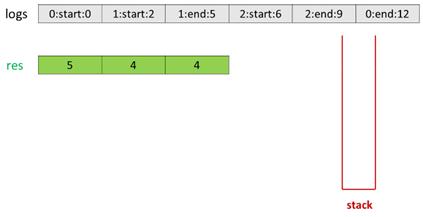
1 public class Solution { 2 public int[] exclusiveTime(int n, List < String > logs) { 3 Stack < Integer > stack = new Stack < > (); 4 int[] res = new int[n]; 5 String[] s = logs.get(0).split(":"); 6 stack.push(Integer.parseInt(s[0])); 7 int i = 1, prev = Integer.parseInt(s[2]); 8 while (i < logs.size()) { 9 s = logs.get(i).split(":"); 10 if (s[1].equals("start")) { 11 if (!stack.isEmpty()) 12 res[stack.peek()] += Integer.parseInt(s[2]) - prev; 13 stack.push(Integer.parseInt(s[0])); 14 prev = Integer.parseInt(s[2]); 15 } else { 16 res[stack.peek()] += Integer.parseInt(s[2]) - prev + 1; 17 stack.pop(); 18 prev = Integer.parseInt(s[2]) + 1; 19 } 20 i++; 21 } 22 return res; 23 } 24 }
