什么是流处理
如果有 java 使用经验的同学一定会对 java8 的 Stream 赞不绝口,极大的提高了们对于集合类型数据的处理能力。
int sum = widgets.stream()
.filter(w -> w.getColor() == RED)
.mapToInt(w -> w.getWeight())
.sum();
Stream 能让我们支持链式调用和函数编程的风格来实现数据的处理,看起来数据像是在流水线一样不断的实时流转加工,最终被汇总。Stream 的实现思想就是将数据处理流程抽象成了一个数据流,每次加工后返回一个新的流供使用。
Stream 功能定义
动手写代码之前,先想清楚,把需求理清楚是最重要的一步,我们尝试代入作者的视角来思考整个组件的实现流程。首先把底层实现的逻辑放一下 ,先尝试从零开始进行功能定义 stream 功能。
Stream 的工作流程其实也属于生产消费者模型,整个流程跟工厂中的生产流程非常相似,尝试先定义一下 Stream 的生命周期:
- 创建阶段/数据获取(原料)
- 加工阶段/中间处理(流水线加工)
- 汇总阶段/终结操作(最终产品)
下面围绕 stream 的三个生命周期开始定义 API:
创建阶段
为了创建出数据流 stream 这一抽象对象,可以理解为构造器。
我们支持三种方式构造 stream,分别是:切片转换,channel 转换,函数式转换。
注意这个阶段的方法都是普通的公开方法,并不绑定 Stream 对象。
// 通过可变参数模式创建 stream
func Just(items ...interface{}) Stream
// 通过 channel 创建 stream
func Range(source <-chan interface{}) Stream
// 通过函数创建 stream
func From(generate GenerateFunc) Stream
// 拼接 stream
func Concat(s Stream, others ...Stream) Stream
加工阶段
加工阶段需要进行的操作往往对应了我们的业务逻辑,比如:转换,过滤,去重,排序等等。
这个阶段的 API 属于 method 需要绑定到 Stream 对象上。
结合常用的业务场景进行如下定义:
// 去除重复item
Distinct(keyFunc KeyFunc) Stream
// 按条件过滤item
Filter(filterFunc FilterFunc, opts ...Option) Stream
// 分组
Group(fn KeyFunc) Stream
// 返回前n个元素
Head(n int64) Stream
// 返回后n个元素
Tail(n int64) Stream
// 转换对象
Map(fn MapFunc, opts ...Option) Stream
// 合并item到slice生成新的stream
Merge() Stream
// 反转
Reverse() Stream
// 排序
Sort(fn LessFunc) Stream
// 作用在每个item上
Walk(fn WalkFunc, opts ...Option) Stream
// 聚合其他Stream
Concat(streams ...Stream) Stream
加工阶段的处理逻辑都会返回一个新的 Stream 对象,这里有个基本的实现范式
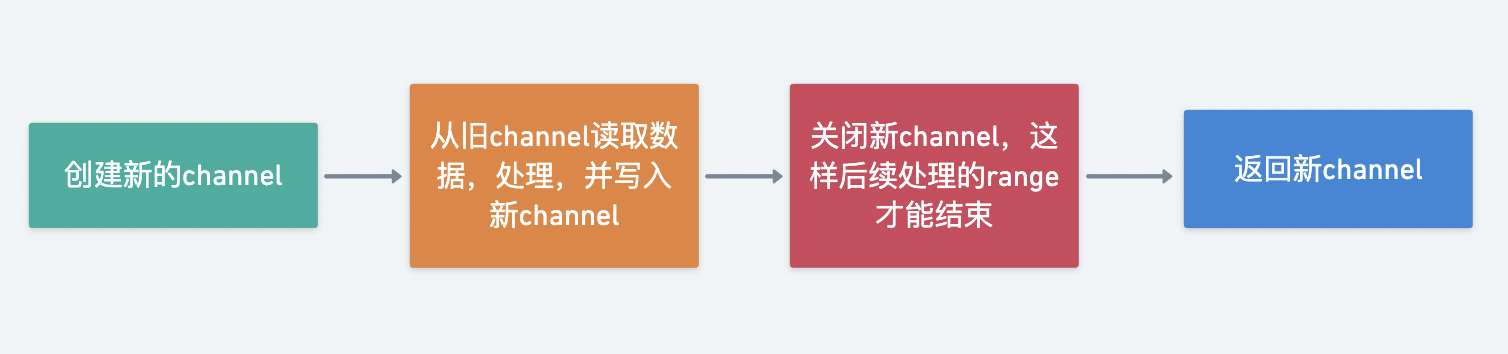
汇总阶段
汇总阶段其实就是我们想要的处理结果,比如:是否匹配,统计数量,遍历等等。
// 检查是否全部匹配
AllMatch(fn PredicateFunc) bool
// 检查是否存在至少一项匹配
AnyMatch(fn PredicateFunc) bool
// 检查全部不匹配
NoneMatch(fn PredicateFunc) bool
// 统计数量
Count() int
// 清空stream
Done()
// 对所有元素执行操作
ForAll(fn ForAllFunc)
// 对每个元素执行操作
ForEach(fn ForEachFunc)
梳理完组件的需求边界后,我们对于即将要实现的 Stream 有了更清晰的认识。在我的认知里面真正的架构师对于需求的把握以及后续演化能达到及其精准的地步,做到这一点离不开对需求的深入思考以及洞穿需求背后的本质。通过代入作者的视角来模拟复盘整个项目的构建流程,学习作者的思维方法论这正是我们学习开源项目最大的价值所在。
好了,我们尝试定义出完整的 Stream 接口全貌以及函数。
接口的作用不仅仅是模版作用,还在于利用其抽象能力搭建项目整体的框架而不至于一开始就陷入细节,能快速的将我们的思考过程通过接口简洁的表达出来,学会养成自顶向下的思维方法从宏观的角度来观察整个系统,一开始就陷入细节则很容易拔剑四顾心茫然。。。
rxOptions struct {
unlimitedWorkers bool
workers int
}
Option func(opts *rxOptions)
// key生成器
//item - stream中的元素
KeyFunc func(item interface{}) interface{}
// 过滤函数
FilterFunc func(item interface{}) bool
// 对象转换函数
MapFunc func(intem interface{}) interface{}
// 对象比较
LessFunc func(a, b interface{}) bool
// 遍历函数
WalkFunc func(item interface{}, pip chan<- interface{})
// 匹配函数
PredicateFunc func(item interface{}) bool
// 对所有元素执行操作
ForAllFunc func(pip <-chan interface{})
// 对每个item执行操作
ForEachFunc func(item interface{})
// 对每个元素并发执行操作
ParallelFunc func(item interface{})
// 对所有元素执行聚合操作
ReduceFunc func(pip <-chan interface{}) (interface{}, error)
// item生成函数
GenerateFunc func(source <-chan interface{})
Stream interface {
// 去除重复item
Distinct(keyFunc KeyFunc) Stream
// 按条件过滤item
Filter(filterFunc FilterFunc, opts ...Option) Stream
// 分组
Group(fn KeyFunc) Stream
// 返回前n个元素
Head(n int64) Stream
// 返回后n个元素
Tail(n int64) Stream
// 获取第一个元素
First() interface{}
// 获取最后一个元素
Last() interface{}
// 转换对象
Map(fn MapFunc, opts ...Option) Stream
// 合并item到slice生成新的stream
Merge() Stream
// 反转
Reverse() Stream
// 排序
Sort(fn LessFunc) Stream
// 作用在每个item上
Walk(fn WalkFunc, opts ...Option) Stream
// 聚合其他Stream
Concat(streams ...Stream) Stream
// 检查是否全部匹配
AllMatch(fn PredicateFunc) bool
// 检查是否存在至少一项匹配
AnyMatch(fn PredicateFunc) bool
// 检查全部不匹配
NoneMatch(fn PredicateFunc) bool
// 统计数量
Count() int
// 清空stream
Done()
// 对所有元素执行操作
ForAll(fn ForAllFunc)
// 对每个元素执行操作
ForEach(fn ForEachFunc)
}
channel() 方法用于获取 Stream 管道属性,因为在具体实现时我们面向的是接口对象所以暴露一个私有方法 read 出来。
// 获取内部的数据容器channel,内部方法
channel() chan interface{}
实现思路
功能定义梳理清楚了,接下来考虑几个工程实现的问题。
如何实现链式调用
链式调用,创建对象用到的 builder 模式可以达到链式调用效果。实际上 Stream 实现类似链式的效果原理也是一样的,每次调用完后都创建一个新的 Stream 返回给用户。
// 去除重复item
Distinct(keyFunc KeyFunc) Stream
// 按条件过滤item
Filter(filterFunc FilterFunc, opts ...Option) Stream
如何实现流水线的处理效果
所谓的流水线可以理解为数据在 Stream 中的存储容器,在 go 中我们可以使用 channel 作为数据的管道,达到 Stream 链式调用执行多个操作时异步非阻塞效果。
如何支持并行处理
数据加工本质上是在处理 channel 中的数据,那么要实现并行处理无非是并行消费 channel 而已,利用 goroutine 协程、WaitGroup 机制可以非常方便的实现并行处理。
go-zero 实现
core/fx/stream.go
go-zero 中关于 Stream 的实现并没有定义接口,不过没关系底层实现时逻辑是一样的。
为了实现 Stream 接口我们定义一个内部的实现类,其中 source 为 channel 类型,模拟流水线功能。
Stream struct {
source <-chan interface{}
}
创建 API
channel 创建 Range
通过 channel 创建 stream
func Range(source <-chan interface{}) Stream {
return Stream{
source: source,
}
}
可变参数模式创建 Just
通过可变参数模式创建 stream,channel 写完后及时 close 是个好习惯。
func Just(items ...interface{}) Stream {
source := make(chan interface{}, len(items))
for _, item := range items {
source <- item
}
close(source)
return Range(source)
}
函数创建 From
通过函数创建 Stream
func From(generate GenerateFunc) Stream {
source := make(chan interface{})
threading.GoSafe(func() {
defer close(source)
generate(source)
})
return Range(source)
}
因为涉及外部传入的函数参数调用,执行过程并不可用因此需要捕捉运行时异常防止 panic 错误传导到上层导致应用崩溃。
func Recover(cleanups ...func()) {
for _, cleanup := range cleanups {
cleanup()
}
if r := recover(); r != nil {
logx.ErrorStack(r)
}
}
func RunSafe(fn func()) {
defer rescue.Recover()
fn()
}
func GoSafe(fn func()) {
go RunSafe(fn)
}
拼接 Concat
拼接其他 Stream 创建一个新的 Stream,调用内部 Concat method 方法,后文将会分析 Concat 的源码实现。
func Concat(s Stream, others ...Stream) Stream {
return s.Concat(others...)
}
加工 API
去重 Distinct
因为传入的是函数参数KeyFunc func(item interface{}) interface{}意味着也同时支持按照业务场景自定义去重,本质上是利用 KeyFunc 返回的结果基于 map 实现去重。
函数参数非常强大,能极大的提升灵活性。
func (s Stream) Distinct(keyFunc KeyFunc) Stream {
source := make(chan interface{})
threading.GoSafe(func() {
// channel记得关闭是个好习惯
defer close(source)
keys := make(map[interface{}]lang.PlaceholderType)
for item := range s.source {
// 自定义去重逻辑
key := keyFunc(item)
// 如果key不存在,则将数据写入新的channel
if _, ok := keys[key]; !ok {
source <- item
keys[key] = lang.Placeholder
}
}
})
return Range(source)
}
使用案例:
// 1 2 3 4 5
Just(1, 2, 3, 3, 4, 5, 5).Distinct(func(item interface{}) interface{} {
return item
}).ForEach(func(item interface{}) {
t.Log(item)
})
// 1 2 3 4
Just(1, 2, 3, 3, 4, 5, 5).Distinct(func(item interface{}) interface{} {
uid := item.(int)
// 对大于4的item进行特殊去重逻辑,最终只保留一个>3的item
if uid > 3 {
return 4
}
return item
}).ForEach(func(item interface{}) {
t.Log(item)
})
过滤 Filter
通过将过滤逻辑抽象成 FilterFunc,然后分别作用在 item 上根据 FilterFunc 返回的布尔值决定是否写回新的 channel 中实现过滤功能,实际的过滤逻辑委托给了 Walk method。
Option 参数包含两个选项:
- unlimitedWorkers 不限制协程数量
- workers 限制协程数量
FilterFunc func(item interface{}) bool
func (s Stream) Filter(filterFunc FilterFunc, opts ...Option) Stream {
return s.Walk(func(item interface{}, pip chan<- interface{}) {
if filterFunc(item) {
pip <- item
}
}, opts...)
}
使用示例:
func TestInternalStream_Filter(t *testing.T) {
// 保留偶数 2,4
channel := Just(1, 2, 3, 4, 5).Filter(func(item interface{}) bool {
return item.(int)%2 == 0
}).channel()
for item := range channel {
t.Log(item)
}
}
遍历执行 Walk
walk 英文意思是步行,这里的意思是对每个 item 都执行一次 WalkFunc 操作并将结果写入到新的 Stream 中。
这里注意一下因为内部采用了协程机制异步执行读取和写入数据所以新的 Stream 中 channel 里面的数据顺序是随机的。
// item-stream中的item元素
// pipe-item符合条件则写入pipe
WalkFunc func(item interface{}, pipe chan<- interface{})
func (s Stream) Walk(fn WalkFunc, opts ...Option) Stream {
option := buildOptions(opts...)
if option.unlimitedWorkers {
return s.walkUnLimited(fn, option)
}
return s.walkLimited(fn, option)
}
func (s Stream) walkUnLimited(fn WalkFunc, option *rxOptions) Stream {
// 创建带缓冲区的channel
// 默认为16,channel中元素超过16将会被阻塞
pipe := make(chan interface{}, defaultWorkers)
go func() {
var wg sync.WaitGroup
for item := range s.source {
// 需要读取s.source的所有元素
// 这里也说明了为什么channel最后写完记得完毕
// 如果不关闭可能导致协程一直阻塞导致泄漏
// 重要, 不赋值给val是个典型的并发陷阱,后面在另一个goroutine里使用了
val := item
wg.Add(1)
// 安全模式下执行函数
threading.GoSafe(func() {
defer wg.Done()
fn(item, pipe)
})
}
wg.Wait()
close(pipe)
}()
// 返回新的Stream
return Range(pipe)
}
func (s Stream) walkLimited(fn WalkFunc, option *rxOptions) Stream {
pipe := make(chan interface{}, option.workers)
go func() {
var wg sync.WaitGroup
// 控制协程数量
pool := make(chan lang.PlaceholderType, option.workers)
for item := range s.source {
// 重要, 不赋值给val是个典型的并发陷阱,后面在另一个goroutine里使用了
val := item
// 超过协程限制时将会被阻塞
pool <- lang.Placeholder
// 这里也说明了为什么channel最后写完记得完毕
// 如果不关闭可能导致协程一直阻塞导致泄漏
wg.Add(1)
// 安全模式下执行函数
threading.GoSafe(func() {
defer func() {
wg.Done()
//执行完成后读取一次pool释放一个协程位置
<-pool
}()
fn(item, pipe)
})
}
wg.Wait()
close(pipe)
}()
return Range(pipe)
}
使用案例:
返回的顺序是随机的。
func Test_Stream_Walk(t *testing.T) {
// 返回 300,100,200
Just(1, 2, 3).Walk(func(item interface{}, pip chan<- interface{}) {
pip <- item.(int) * 100
}, WithWorkers(3)).ForEach(func(item interface{}) {
t.Log(item)
})
}
分组 Group
通过对 item 匹配放入 map 中。
KeyFunc func(item interface{}) interface{}
func (s Stream) Group(fn KeyFunc) Stream {
groups := make(map[interface{}][]interface{})
for item := range s.source {
key := fn(item)
groups[key] = append(groups[key], item)
}
source := make(chan interface{})
go func() {
for _, group := range groups {
source <- group
}
close(source)
}()
return Range(source)
}
获取前 n 个元素 Head
n 大于实际数据集长度的话将会返回全部元素
func (s Stream) Head(n int64) Stream {
if n < 1 {
panic("n must be greather than 1")
}
source := make(chan interface{})
go func() {
for item := range s.source {
n--
// n值可能大于s.source长度,需要判断是否>=0
if n >= 0 {
source <- item
}
// let successive method go ASAP even we have more items to skip
// why we don't just break the loop, because if break,
// this former goroutine will block forever, which will cause goroutine leak.
// n==0说明source已经写满可以进行关闭了
// 既然source已经满足条件了为什么不直接进行break跳出循环呢?
// 作者提到了防止协程泄漏
// 因为每次操作最终都会产生一个新的Stream,旧的Stream永远也不会被调用了
if n == 0 {
close(source)
break
}
}
// 上面的循环跳出来了说明n大于s.source实际长度
// 依旧需要显示关闭新的source
if n > 0 {
close(source)
}
}()
return Range(source)
}
使用示例:
// 返回1,2
func TestInternalStream_Head(t *testing.T) {
channel := Just(1, 2, 3, 4, 5).Head(2).channel()
for item := range channel {
t.Log(item)
}
}
获取后 n 个元素 Tail
这里很有意思,为了确保拿到最后 n 个元素使用环形切片 Ring 这个数据结构,先了解一下 Ring 的实现。
// 环形切片
type Ring struct {
elements []interface{}
index int
lock sync.Mutex
}
func NewRing(n int) *Ring {
if n < 1 {
panic("n should be greather than 0")
}
return &Ring{
elements: make([]interface{}, n),
}
}
// 添加元素
func (r *Ring) Add(v interface{}) {
r.lock.Lock()
defer r.lock.Unlock()
// 将元素写入切片指定位置
// 这里的取余实现了循环写效果
r.elements[r.index%len(r.elements)] = v
// 更新下次写入位置
r.index++
}
// 获取全部元素
// 读取顺序保持与写入顺序一致
func (r *Ring) Take() []interface{} {
r.lock.Lock()
defer r.lock.Unlock()
var size int
var start int
// 当出现循环写的情况时
// 开始读取位置需要通过去余实现,因为我们希望读取出来的顺序与写入顺序一致
if r.index > len(r.elements) {
size = len(r.elements)
// 因为出现循环写情况,当前写入位置index开始为最旧的数据
start = r.index % len(r.elements)
} else {
size = r.index
}
elements := make([]interface{}, size)
for i := 0; i < size; i++ {
// 取余实现环形读取,读取顺序保持与写入顺序一致
elements[i] = r.elements[(start+i)%len(r.elements)]
}
return elements
}
总结一下环形切片的优点:
- 支持自动滚动更新
- 节省内存
环形切片能实现固定容量满的情况下旧数据不断被新数据覆盖,由于这个特性可以用于读取 channel 后 n 个元素。
func (s Stream) Tail(n int64) Stream {
if n < 1 {
panic("n must be greather than 1")
}
source := make(chan interface{})
go func() {
ring := collection.NewRing(int(n))
// 读取全部元素,如果数量>n环形切片能实现新数据覆盖旧数据
// 保证获取到的一定最后n个元素
for item := range s.source {
ring.Add(item)
}
for _, item := range ring.Take() {
source <- item
}
close(source)
}()
return Range(source)
}
那么为什么不直接使用 len(source) 长度的切片呢?
答案是节省内存。凡是涉及到环形类型的数据结构时都具备一个优点那就省内存,能做到按需分配资源。
使用示例:
func TestInternalStream_Tail(t *testing.T) {
// 4,5
channel := Just(1, 2, 3, 4, 5).Tail(2).channel()
for item := range channel {
t.Log(item)
}
// 1,2,3,4,5
channel2 := Just(1, 2, 3, 4, 5).Tail(6).channel()
for item := range channel2 {
t.Log(item)
}
}
元素转换Map
元素转换,内部由协程完成转换操作,注意输出channel并不保证按原序输出。
MapFunc func(intem interface{}) interface{}
func (s Stream) Map(fn MapFunc, opts ...Option) Stream {
return s.Walk(func(item interface{}, pip chan<- interface{}) {
pip <- fn(item)
}, opts...)
}
使用示例:
func TestInternalStream_Map(t *testing.T) {
channel := Just(1, 2, 3, 4, 5, 2, 2, 2, 2, 2, 2).Map(func(item interface{}) interface{} {
return item.(int) * 10
}).channel()
for item := range channel {
t.Log(item)
}
}
合并 Merge
实现比较简单,我考虑了很久没想到有什么场景适合这个方法。
func (s Stream) Merge() Stream {
var items []interface{}
for item := range s.source {
items = append(items, item)
}
source := make(chan interface{}, 1)
source <- items
close(source)
return Range(source)
}
反转 Reverse
反转 channel 中的元素。反转算法流程是:
-
找到中间节点
-
节点两边开始两两交换
注意一下为什么获取 s.source 时用切片来接收呢? 切片会自动扩容,用数组不是更好吗?
其实这里是不能用数组的,因为不知道 Stream 写入 source 的操作往往是在协程异步写入的,每个 Stream 中的 channel 都可能在动态变化,用流水线来比喻 Stream 工作流程的确非常形象。
func (s Stream) Reverse() Stream {
var items []interface{}
for item := range s.source {
items = append(items, item)
}
for i := len(items)/2 - 1; i >= 0; i-- {
opp := len(items) - 1 - i
items[i], items[opp] = items[opp], items[i]
}
return Just(items...)
}
使用示例:
func TestInternalStream_Reverse(t *testing.T) {
channel := Just(1, 2, 3, 4, 5).Reverse().channel()
for item := range channel {
t.Log(item)
}
}
排序 Sort
内网调用 slice 官方包的排序方案,传入比较函数实现比较逻辑即可。
func (s Stream) Sort(fn LessFunc) Stream {
var items []interface{}
for item := range s.source {
items = append(items, item)
}
sort.Slice(items, func(i, j int) bool {
return fn(i, j)
})
return Just(items...)
}
使用示例:
// 5,4,3,2,1
func TestInternalStream_Sort(t *testing.T) {
channel := Just(1, 2, 3, 4, 5).Sort(func(a, b interface{}) bool {
return a.(int) > b.(int)
}).channel()
for item := range channel {
t.Log(item)
}
}
拼接 Concat
func (s Stream) Concat(steams ...Stream) Stream {
// 创建新的无缓冲channel
source := make(chan interface{})
go func() {
// 创建一个waiGroup对象
group := threading.NewRoutineGroup()
// 异步从原channel读取数据
group.Run(func() {
for item := range s.source {
source <- item
}
})
// 异步读取待拼接Stream的channel数据
for _, stream := range steams {
// 每个Stream开启一个协程
group.Run(func() {
for item := range stream.channel() {
source <- item
}
})
}
// 阻塞等待读取完成
group.Wait()
close(source)
}()
// 返回新的Stream
return Range(source)
}
汇总 API
全部匹配 AllMatch
func (s Stream) AllMatch(fn PredicateFunc) bool {
for item := range s.source {
if !fn(item) {
// 需要排空 s.source,否则前面的goroutine可能阻塞
go drain(s.source)
return false
}
}
return true
}
任意匹配 AnyMatch
func (s Stream) AnyMatch(fn PredicateFunc) bool {
for item := range s.source {
if fn(item) {
// 需要排空 s.source,否则前面的goroutine可能阻塞
go drain(s.source)
return true
}
}
return false
}
一个也不匹配 NoneMatch
func (s Stream) NoneMatch(fn func(item interface{}) bool) bool {
for item := range s.source {
if fn(item) {
// 需要排空 s.source,否则前面的goroutine可能阻塞
go drain(s.source)
return false
}
}
return true
}
数量统计 Count
func (s Stream) Count() int {
var count int
for range s.source {
count++
}
return count
}
清空 Done
func (s Stream) Done() {
// 排空 channel,防止 goroutine 阻塞泄露
drain(s.source)
}
迭代全部元素 ForAll
func (s Stream) ForAll(fn ForAllFunc) {
fn(s.source)
}
迭代每个元素 ForEach
func (s Stream) ForAll(fn ForAllFunc) {
fn(s.source)
}
小结
至此 Stream 组件就全部实现完了,核心逻辑是利用 channel 当做管道,数据当做水流,不断的用协程接收/写入数据到 channel 中达到异步非阻塞的效果。
回到开篇提到的问题,未动手前想要实现一个 stream 难度似乎非常大,很难想象在 go 中 300 多行的代码就能实现如此强大的组件。
实现高效的基础来源三个语言特性:
- channel
- 协程
- 函数式编程
参考资料
项目地址
https://github.com/zeromicro/go-zero
欢迎使用 go-zero 并 star 支持我们!
微信交流群
关注『微服务实践』公众号并点击 交流群 获取社区群二维码。