作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2753
1.列表,元组,字典,集合分别如何增删改查及遍历。
2.总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
- 括号
- 有序无序
- 可变不可变
- 重复不可重复
- 存储与查找方式
列表:list1 = ['python',2019,'java',1997]
列表的数据项不需要具有相同的类型,创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可
list[index]:访问列表下标为index的值,赋值修改下标index的值 del list[index]:删除列表下标为index的值 list[ : ]:截取列表中的片段
len(list):返回列表的长度 max(list):返回列表中的最大值 min(list):返回列表中的最小值 list(seq):将元组转换成列表
list.append(obj):在列表末尾添加新的对象 list.count(obj):统计某个元素在列表中出现的次数
list.extend(seq):在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
list.index(obj):从列表中找出某个值第一个匹配项的索引位置 list.insert(index, obj):将对象插入列表
list.pop([index=-1])移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
list.remove(obj)移除列表中某个值的第一个匹配项 list.sort(key=None, reverse=False)对原列表进行排序
元组:tup1 = ('python',2019,'java',1997)
元组与列表类似,不同之处在于元组的元素不能修改
创建元组,只需要在括号中添加元素,并使用逗号隔开即可
元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用;
元组中的元素值不允许修改,tup[index]:访问元组下标为index的值,可通过tup = tup1+tup2对元组进行连接组合
元组中的元素值不允许删除,del tup:删除整个元组 tup[ : ]:截取元组中的片段
len(tup):返回元组的长度 max(tup):返回元组中的最大值 min(tup):返回元组中的最小值 tup(seq):将列表转换成列表
字典:dict = {'a': '1', 'b': '2', 'c': '3'}
字典是另一种可变容器模型,且可存储任意类型对象。
字典的键必须是唯一的,但值则不必
字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中
dict['key']:访问字典中的值,赋值修改key对应的值 dict['key'] = value:添加键值对
del dict['key']:删除键 'key' dict.clear():清空字典 del dict :删除字典
len(dict):返回字典元素的个数 str(dict):输出字典,以可打印的字符串表示
dict.items():返回可遍历的(键, 值) 元组数组 pop(key[,default]):删除字典给定键 key 所对应的值,返回值为被删除的值
集合:set1= {value01,value02,...} 或者 set(value)
集合是一个无序的不重复元素序列,可以使用大括号 { } 或者 set() 函数创建集合
set1 - set2:集合set1中包含而集合set2中不包含的元素
set1 | set2:集合set1 或set2中包含的所有元素
set1 & set2:集合set1和set2中都包含了的元素
set1 ^ set2:不同时包含于set1和set2的元素
set.add(elmnt):添加元素 set.pop(): 随机移除一个元素 set.remove(item):移除集合中的指定元素
set.update:修改当前集合,可以添加新的元素或集合到当前集合中
3.词频统计
3.1下载一长篇小说,存成utf-8编码的文本文件 file
3.2通过文件读取字符串 str
3.3对文本进行预处理
3.4分解提取单词 list
3.5单词计数字典 set , dict
3.6按词频排序 list.sort(key=lambda),turple
3.7排除语法型词汇,代词、冠词、连词等无语义词
自定义停用词表
或用stops.txt
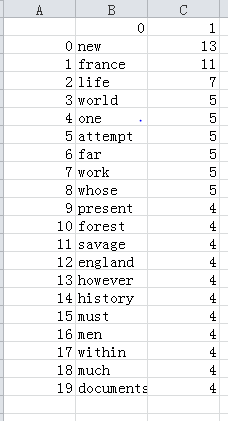
3.8输出TOP(20)
3.9可视化:词云
排序好的单词列表word保存成csv文件
import pandas as pd
pd.DataFrame(data=word).to_csv('big.csv',encoding='utf-8')
线上工具生成词云:
https://wordart.com/create
import requests from bs4 import BeautifulSoup from fake_useragent import UserAgent import re from nltk.corpus import stopwords import pandas as pd def get_text(): url = 'http://novel.tingroom.com/jingdian/2857/78803.html' ua = UserAgent() headers = {'User_Agent': ua.random} html = requests.get(url,headers= headers) #请求得到链接 html.encoding = 'utf-8' #编码 soup = BeautifulSoup(html.text,'lxml') #操作html文档 Eng_text = soup.find('div',class_='text').get_text() #获取text文本 Eng_text = re.sub('<!-[\s\S]*?-->','',Eng_text) #去text的注释 Eng_text = Eng_text.replace('欢迎访问英文小说网http://novel.tingroom.com','').replace('只需30秒,测测你的英语词汇量!','') #去text后面的文本 Eng_text = Eng_text.strip('\t\n\r').lstrip().rstrip() #去空行、空格 #保存text文件 with open('Eng_text.txt','w') as f: f.write(Eng_text) Eng_text = Eng_text.lower() # 将所有大写转换为小写 s = ',.?!\";' for i in s: Eng_text = Eng_text.replace(i, ' ') # 将所有其他做分隔符(,.?!)替换为空格 Eng_text = Eng_text.split() # 分隔出一个一个的单词 InfoSet = set(Eng_text) #集合方式获得每个单词 Count = {} for txt in InfoSet: Count.setdefault(txt, Eng_text.count(txt)) # 统计单词出现的次数 words = stopwords.words('english') #英语的stopwords for word in words: Stopword = Count.pop(word,'none') #删除字典中的停用词,返回删除对象,没有则返回none Count = sorted(Count.items(), key=lambda x: x[1],reverse=True) #按values的值从大到小排序,返回列表,以数组存储键值对 Top = Count[:20] #截取前20个 print(Top) pd.DataFrame(data=Top).to_csv('TOP20.csv', encoding='utf-8') #将前20个保存成csv文件,excel打开 if __name__ == '__main__': get_text()